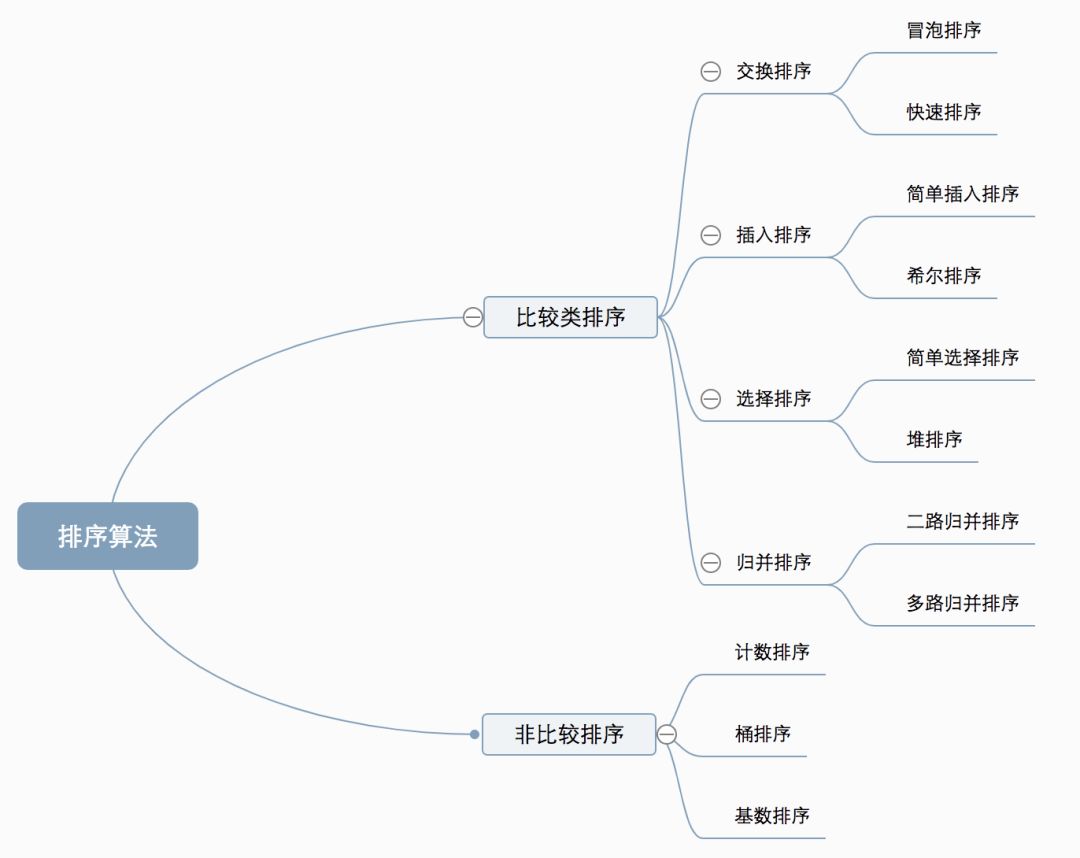
十种常见排序算法可以分为两大类:
比较类排序:通过比较来决定元素间的相对次序,由于其时间复杂度不能突破O(nlogn),因此也称为非线性时间比较类排序。
非比较类排序:不通过比较来决定元素间的相对次序,它可以突破基于比较排序的时间下界,以线性时间运行,因此也称为线性时间非比较类排序。
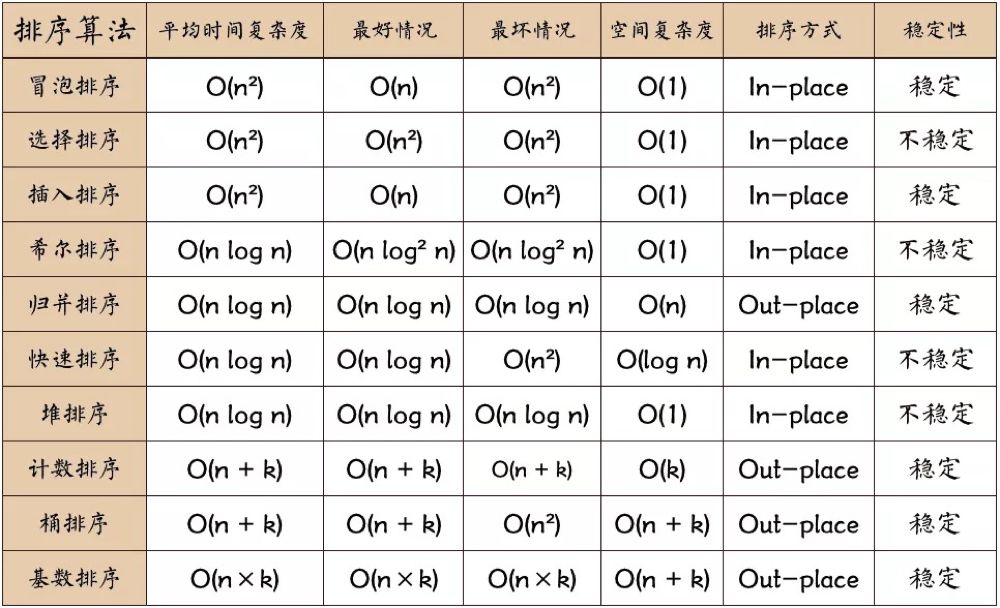
概括一下时间和空间复杂度:
上图相关概念:
稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面。
不稳定:如果a原本在b的前面,而a=b,排序之后 a 可能会出现在 b 的后面。
时间复杂度:对排序数据的总的操作次数。反映当n变化时,操作次数呈现什么规律。
空间复杂度:是指算法在计算机内执行时所需存储空间的度量,它也是数据规模n的函数。
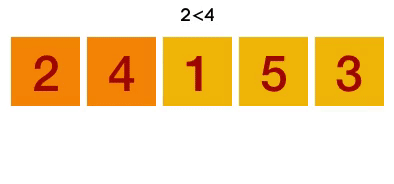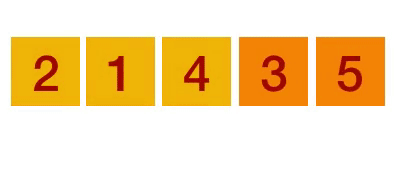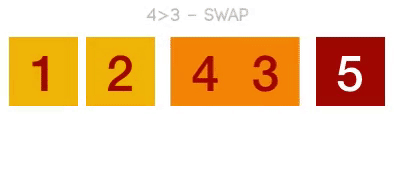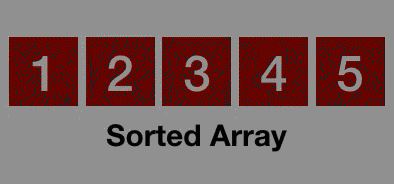
1 冒泡排序(Bubble Sort)
冒泡排序是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。冒泡排序还有一种优化算法,就是立一个flag,当在一趟序列遍历中元素没有发生交换,则证明该序列已经有序。但这种改进对于提升性能来说并没有什么太大作用。
算法描述
比较相邻的元素。如果第一个比第二个大,就交换它们两个;
对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最后的元素应该会是最大的数;
针对所有的元素重复以上的步骤,除了最后一个;
重复步骤1~3,直到排序完成。
动图演示
代码实现
1public class BubbleSort implements IArraySort {
2
3 @Override
4 public int[] sort(int[] sourceArray) throws Exception {
5 // 对 arr 进行拷贝,不改变参数内容
6 int[] arr = Arrays.copyOf(sourceArray, sourceArray.length);
7
8 for (int i = 1; i < arr.length; i++) {
9 // 设定一个标记,若为true,则表示此次循环没有进行交换,也就是待排序列已经有序,排序已经完成。
10 boolean flag = true;
11
12 for (int j = 0; j < arr.length - i; j++) {
13 if (arr[j] > arr[j + 1]) {
14 int tmp = arr[j];
15 arr[j] = arr[j + 1];
16 arr[j + 1] = tmp;
17
18 flag = false;
19 }
20 }
21
22 if (flag) {
23 break;
24 }
25 }
26 return arr;
27 }
28}
29
30```java
31
32### 2 选择排序(Selection Sort)
33
34选择排序(Selection-sort)是一种简单直观的排序算法。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
35
36#### 算法描述
37
38- 首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置
39
40- 再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
41
42- 重复第二步,直到所有元素均排序完毕。
43
44**动图演示**
45
46****
47
48#### 代码实现
49
50```java
51public class SelectionSort implements IArraySort {
52
53 @Override
54 public int[] sort(int[] sourceArray) throws Exception {
55 int[] arr = Arrays.copyOf(sourceArray, sourceArray.length);
56
57 // 总共要经过 N-1 轮比较
58 for (int i = 0; i < arr.length - 1; i++) {
59 int min = i;
60
61 // 每轮需要比较的次数 N-i
62 for (int j = i + 1; j < arr.length; j++) {
63 if (arr[j] < arr[min]) {
64 // 记录目前能找到的最小值元素的下标
65 min = j;
66 }
67 }
68
69 // 将找到的最小值和i位置所在的值进行交换
70 if (i != min) {
71 int tmp = arr[i];
72 arr[i] = arr[min];
73 arr[min] = tmp;
74 }
75
76 }
77 return arr;
78 }
79}
80
81```java
82
83### 3 插入排序(Insertion Sort)
84
85插入排序的代码实现虽然没有冒泡排序和选择排序那么简单粗暴,但它的原理应该是最容易理解的了,因为只要打过扑克牌的人都应该能够秒懂。插入排序是一种最简单直观的排序算法,它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
86
87#### 算法描述
88
89- 从第一个元素开始,该元素可以认为已经被排序;
90
91- 取出下一个元素,在已经排序的元素序列中从后向前扫描;
92
93- 如果该元素(已排序)大于新元素,将该元素移到下一位置;
94
95- 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置;
96
97- 将新元素插入到该位置后;
98
99- 重复步骤2~5。
100
101**动图演示**
102
103
104
105#### 代码实现
106
107```java
108public class InsertSort implements IArraySort {
109
110 @Override
111 public int[] sort(int[] sourceArray) throws Exception {
112 // 对 arr 进行拷贝,不改变参数内容
113 int[] arr = Arrays.copyOf(sourceArray, sourceArray.length);
114
115 // 从下标为1的元素开始选择合适的位置插入,因为下标为0的只有一个元素,默认是有序的
116 for (int i = 1; i < arr.length; i++) {
117
118 // 记录要插入的数据
119 int tmp = arr[i];
120
121 // 从已经排序的序列最右边的开始比较,找到比其小的数
122 int j = i;
123 while (j > 0 && tmp < arr[j - 1]) {
124 arr[j] = arr[j - 1];
125 j--;
126 }
127
128 // 存在比其小的数,插入
129 if (j != i) {
130 arr[j] = tmp;
131 }
132
133 }
134 return arr;
135 }
136}
137
138```java
139
140### 4 希尔排序(Shell Sort)
141
142希尔排序按其设计者希尔(Donald Shell)的名字命名,该算法由1959年公布。
143
144希尔排序,也称**递减增量排序**算法,它是简单插入排序经过改进之后的一个更高效的版本。实际上,希尔排序就是插入排序的高级版。
145
146希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止。它的做法不是每次一个元素挨一个元素的比较。而是初期选用大跨步(增量较大)间隔比较,使记录跳跃式接近它的排序位置;然后增量缩小;最后增量为 1 ,这样记录**移动次数大大减少**,提高了排序效率。希尔排序对增量序列的选择没有严格规定。
147
148简单插入排序很循规蹈矩,不管数组分布是怎么样的,依然一步一步的对元素进行比较,移动,插入,比如[5,4,3,2,1,0]这种倒序序列,数组末端的0要回到首位置很是费劲,比较和移动元素均需n-1次。而希尔排序在数组中采用跳跃式分组的策略,通过某个增量将数组元素划分为若干组,然后分组进行插入排序,随后逐步缩小增量,继续按组进行插入排序操作,直至增量为1。希尔排序通过这种策略使得整个数组在初始阶段达到从宏观上看基本有序,小的基本在前,大的基本在后。然后缩小增量,到增量为1时,其实多数情况下只需微调即可,不会涉及过多的数据移动。
149
150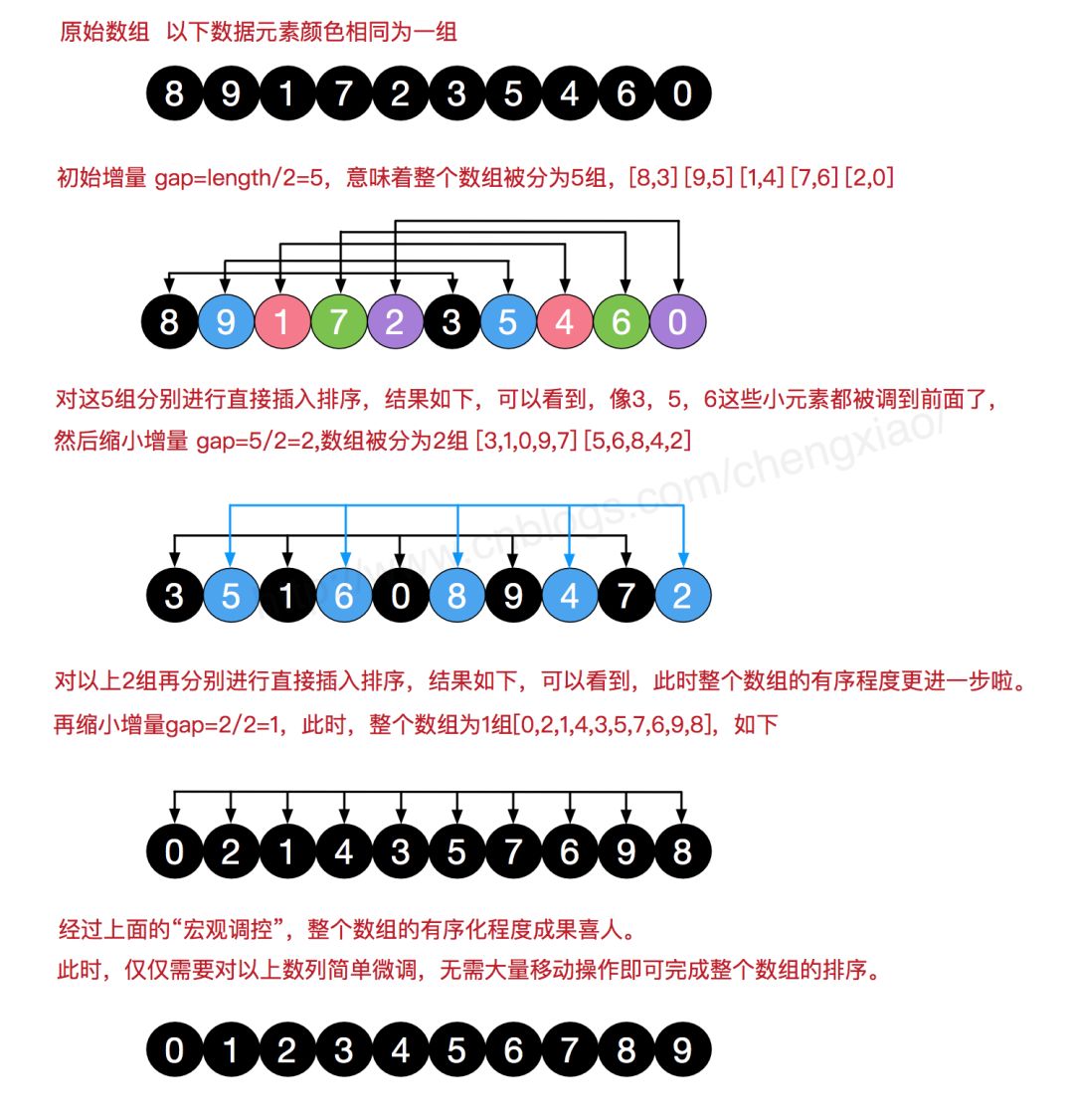
151
152再举个例子:
153
154例如,假设有这样一组数[ 13 14 94 33 82 25 59 94 65 23 45 27 73 25 39 10 ],如果我们以步长为5开始进行排序,我们可以通过将这列表放在有5列的表中来更好地描述算法,这样他们就应该看起来是这样:
155
15613 14 94 33 82
15725 59 94 65 23
15845 27 73 25 39
15910
160
161然后我们对每列进行排序:
162
16310 14 73 25 23
16413 27 94 33 39
16525 59 94 65 82
16645
167
168将上述四行数字,依序接在一起时我们得到:[ 10 14 73 25 23 13 27 94 33 39 25 59 94 65 82 45 ].这时10已经移至正确位置了,然后再以3为步长进行排序:
169
17010 14 73
17125 23 13
17227 94 33
17339 25 59
17494 65 82
17545
176
177排序之后变为:
178
17910 14 13
18025 23 33
18127 25 59
18239 65 73
18345 94 82
18494
185
186最后以1步长进行排序(此时就是简单的插入排序了)。
187
188**总结来看:步长是多少,就分多少组(子序列)**
189
190#### 算法描述
191
192- 选择一个增量序列t1,t2,…,tk,其中ti>tj,tk=1;
193
194- 按增量序列个数k,对序列进行k 趟排序;
195
196- 每趟排序,根据对应的增量ti,将待排序列分割成若干长度为m 的子序列,分别对各子表进行直接插入排序。仅增量因子为1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
197
198#### 动图演示
199
200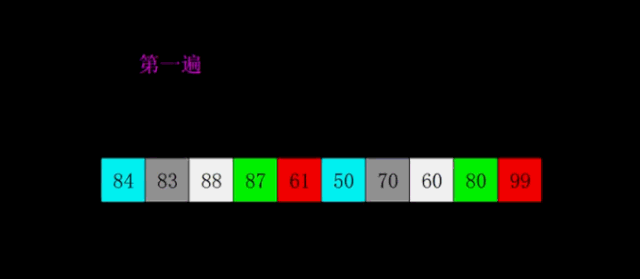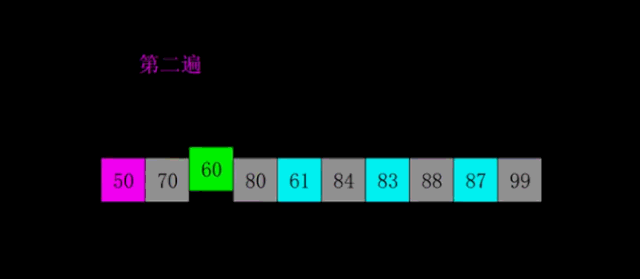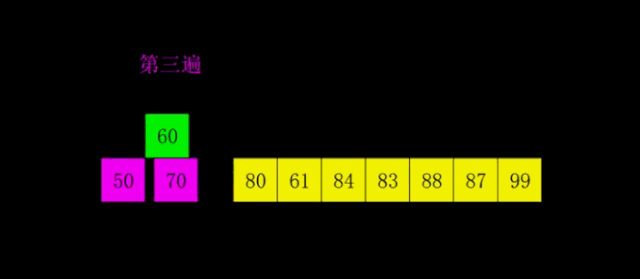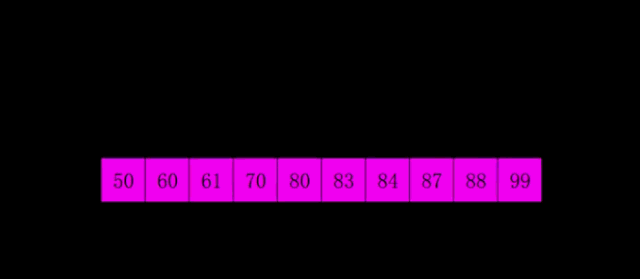
201
202#### 代码实现
203
204```java
205public class ShellSort implements IArraySort {
206
207 @Override
208 public int[] sort(int[] sourceArray) throws Exception {
209 // 对 arr 进行拷贝,不改变参数内容
210 int[] arr = Arrays.copyOf(sourceArray, sourceArray.length);
211
212 int gap = 1;
213 while (gap < arr.length/3) {
214 gap = gap * 3 + 1;
215 }
216
217 while (gap > 0) {
218 for (int i = gap; i < arr.length; i++) {
219 int tmp = arr[i];
220 int j = i - gap;
221 while (j >= 0 && arr[j] > tmp) {
222 arr[j + gap] = arr[j];
223 j -= gap;
224 }
225 arr[j + gap] = tmp;
226 }
227 gap = (int) Math.floor(gap / 3);
228 }
229
230 return arr;
231 }
232}
随着排序的进行,数组越来越接近有序,步长也越来越小,直到gap=1,此时希尔排序就变得跟插入排序一模一样了,但此时数组已经几乎完全有序了,对一个几乎有序的数组运行插入排序,其复杂度接近O(N)。整个过程看起来天衣无缝,然而其中隐藏着一个难点,应该使用怎样的增量序列?
必须要考虑的因素有两点:
当改变步长的时候,如何保证新的步长不会打乱之前排序的结果?
这不会影响最终排序的正确性,因为只要步长在减小,数组永远都只会朝着更加有序的方向迈进,但这却是影响希尔排序效率的关键。因为这涉及到完成排序的过程中,算法做了多少无用功。如何保证每一个步长都是有意义的?来看一个例子,假设有一个数组[1,5,2,6,3,7,4,8],使用步长序列[4,2,1]对其进行排序,过程如图:
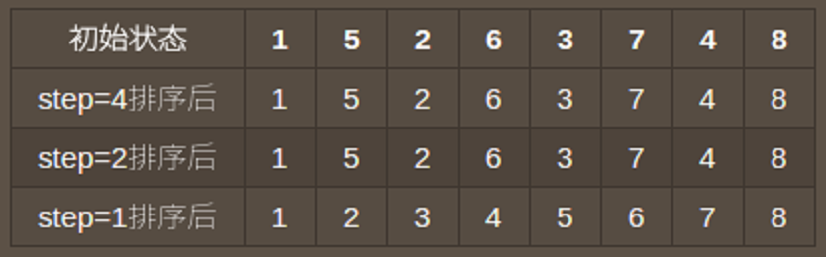
这就相当于进行了一次低效的插入排序,因为在step=1之前,程序什么也没干,偶数位置永远不会与基数位置进行比较 **目前已有的增量算法有以下几种**( N为数组长度):

其中第一个它出自Shell本人且非常容易用代码表达,因此而流行,我看到现在的一些文章中的例子都还在使用它或它的变种。本文中代码实现部分为了方便演示,选择了很多例子中惯用的一个增量算法。
希尔排序相对于前面三种排序复杂一些,没有那么直观,需要仔细思考,如果对照程序想不明白,最好Debug一下程序,看一下流程,你会发现其实内核还是插入排序只不过外面套了多个不同步长的子序列,进行了多次插入排序而已。
5 归并排序(Merge Sort)
归并排序(MERGE-SORT)是利用归并的思想实现的排序方法,该算法采用经典的分治(divide-and-conquer)策略(分治法将问题分(divide)成一些小的问题然后递归求解,而治(conquer)的阶段则将分的阶段得到的各答案"修补"在一起,即分而治之)。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为2路归并。
作为一种典型的分而治之思想的算法应用,归并排序的实现由两种方法:
自上而下的递归(所有递归的方法都可以用迭代重写,所以就有了第 2 种方法);
自下而上的迭代;
分而治之
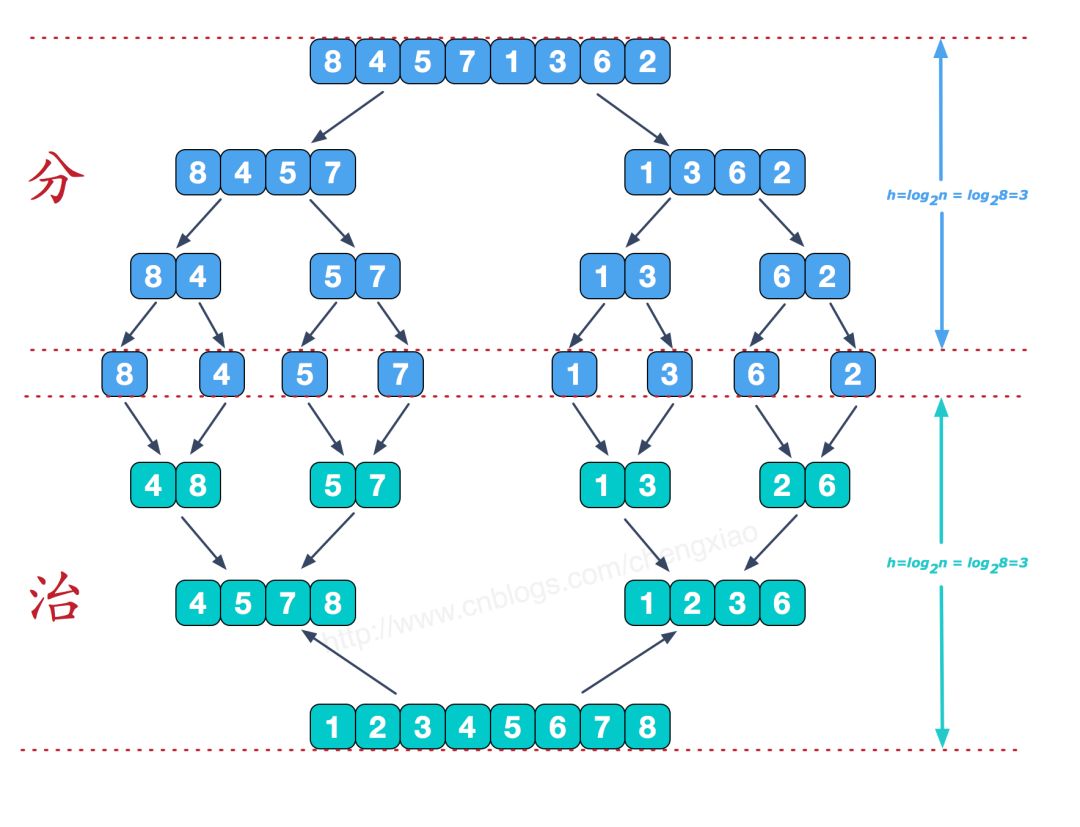
可以看到这种结构很像一棵完全二叉树,本文的归并排序我们采用递归去实现(也可采用迭代的方式去实现)
算法描述
把长度为n的输入序列分成两个长度为n/2的子序列;
对这两个子序列分别采用归并排序;
将两个排序好的子序列合并成一个最终的排序序列。
动图演示

代码实现
1public class MergeSort {
2
3 public int[] sort(int[] sourceArray) throws Exception {
4 // 对 arr 进行拷贝,不改变参数内容
5 int[] arr = Arrays.copyOf(sourceArray, sourceArray.length);
6
7 if (arr.length < 2) {
8 return arr;
9 }
10 int middle = (int) Math.floor(arr.length / 2);
11
12 int[] left = Arrays.copyOfRange(arr, 0, middle);
13 int[] right = Arrays.copyOfRange(arr, middle, arr.length);
14
15 return merge(sort(left), sort(right));
16 }
17
18 protected int[] merge(int[] left, int[] right) {
19 int[] result = new int[left.length + right.length];
20 int i = 0;
21 while (left.length > 0 && right.length > 0) {
22 if (left[0] <= right[0]) {
23 result[i++] = left[0];
24 left = Arrays.copyOfRange(left, 1, left.length);
25 } else {
26 result[i++] = right[0];
27 right = Arrays.copyOfRange(right, 1, right.length);
28 }
29 }
30
31 while (left.length > 0) {
32 result[i++] = left[0];
33 left = Arrays.copyOfRange(left, 1, left.length);
34 }
35
36 while (right.length > 0) {
37 result[i++] = right[0];
38 right = Arrays.copyOfRange(right, 1, right.length);
39 }
40
41 return result;
42 }
43
44}
归并排序是一种稳定的排序方法。和选择排序一样,归并排序的性能不受输入数据的影响,但表现比选择排序好的多,因为始终都是O(nlogn)的时间复杂度。代价是需要额外的内存空间。
关于动画演示,网上有许多比本文更漂亮的,大家可以搜索看一下,比如 http://sorting.at/ 有多种排序算法的动画演示,非常漂亮
参考

关注公众号 获取更多精彩内容