
分布式主键问题
传统数据库软件开发中,主键自动生成技术是基本需求。而各个数据库对于该需求也提供了相应的支持,比如 MySQL 的自增键,Oracle 的自增序列等。数据分片后,不同数据节点生成全局唯一主键是非常棘手的问题。同一个逻辑表内的不同实际表之间的自增键由于无法互相感知而产生重复主键。虽然可通过约束自增主键初始值和步长的方式避免碰撞,但需引入额外的运维规则,使解决方案缺乏完整性和可扩展性。
目前有许多第三方解决方案可以完美解决这个问题,如 UUID 等依靠特定算法自生成不重复键,或者通过引入主键生成服务等。为了方便用户使用、满足不同用户不同使用场景的需求, Apache ShardingSphere 不仅提供了内置的分布式主键生成器,例如 UUID、SNOWFLAKE,还抽离出分布式主键生成器的接口,方便用户自行实现自定义的自增主键生成器。
可以参考之前的一篇文章:分库分表与到底要不要用自增ID?
分片键
用于分片的数据库字段,是将数据库(表)水平拆分的关键字段。例:将订单表中的订单主键的尾数取模分片,则订单主键为分片字段。SQL 中如果无分片字段,将执行全路由,性能较差。除了对单分片字段的支持,Apache ShardingSphere 也支持根据多个字段进行分片。
路由
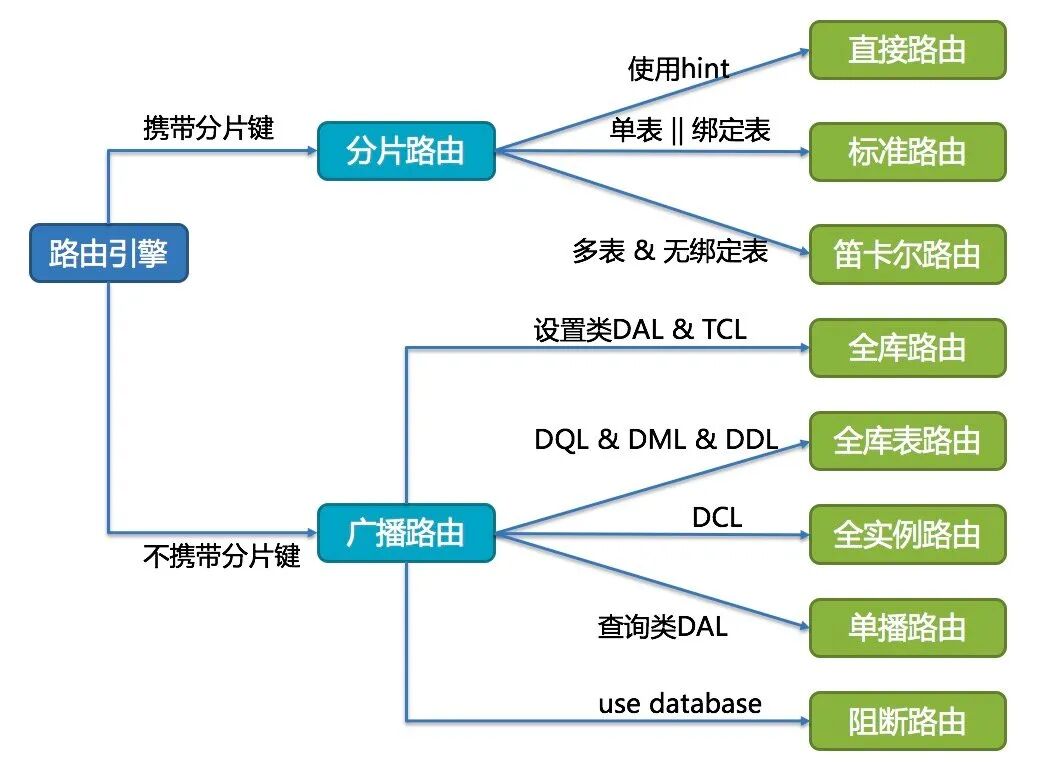
广播路由
对于不携带分片键的 SQL,采取广播路由的方式。
1
2SELECT * FROM t_order WHERE good_prority IN (1, 10);
这样一句 SQL 广播到全库表查询
1SELECT * FROM t_order_0 WHERE good_prority IN (1, 10);
2SELECT * FROM t_order_1 WHERE good_prority IN (1, 10);
3SELECT * FROM t_order_2 WHERE good_prority IN (1, 10);
4SELECT * FROM t_order_3 WHERE good_prority IN (1, 10);
单播路由
单播路由用于获取某一真实表信息的场景,它仅需要从任意库中的任意真实表中获取数据即可。
实践
由于我们数据库的发展方向大概是这样的:
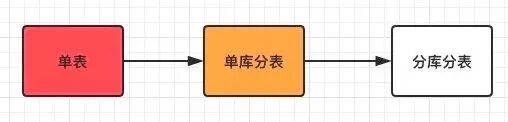
所以我们按照趋势先做单库分表的操作实践,再做分库分表的。
声明一下版本,以下实践用的是 ShardingSphere5.0 Beta版本
单库分表-新业务
我们先假设在理想情况下,也就是业务未开始前就采用分表的方式。
由于 ShardingSphere 是不会自动按照分表规则创建表的,所以我们先手动将表创建好,当然也只是表名不一样,表结构是相同的,以下是测试用建表语句:
1CREATE TABLE `t_order_sharding_0` (
2 `order_id` bigint(20) NOT NULL,
3 `user_id` bigint(20) DEFAULT NULL,
4 `create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
5 `update_time` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
6 PRIMARY KEY (`order_id`)
7) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
8
9CREATE TABLE `t_order_sharding_1` (
10 `order_id` bigint(20) NOT NULL,
11 `user_id` bigint(20) DEFAULT NULL,
12 `create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
13 `update_time` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
14 PRIMARY KEY (`order_id`)
15) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
为了演示方便,我们简单建了两个表 t_order_sharding_0,t_order_sharding_1
以下是我 yaml 配置文件中有关分表部分的配置:
1# 配置分库分表
2sharding:
3 sharding-algorithms:
4 table_inline:
5 props:
6 algorithm-expression: t_order_sharding_${order_id % 2}
7 type: INLINE
8 tables:
9 t_order_sharding:
10 # 配置 t_order 表规则
11 actual-data-nodes: write-ds.t_order_sharding_$->{0..1}
12 table-strategy: #分表策略
13 standard:
14 sharding-algorithm-name: table_inline
15 sharding-column: order_id
注意这里你配置成我这样是跑不起来的,有两个原因:
11 table_inline 不能写下划线,要写成 table-inline
22 t_order_sharding_${order_id % 2} 不能这么写,t_order_sharding_$->{order_id % 2 }
最后正常的配置是:
1# 配置分库分表
2sharding:
3 sharding-algorithms:
4 table-inline:
5 props:
6 algorithm-expression: t_order_sharding_$->{order_id % 2}
7 type: INLINE
8 tables:
9 t_order_sharding:
10 # 配置 t_order 表规则
11 actual-data-nodes: write-ds.t_order_sharding_$->{0..1}
12 table-strategy: #分表策略
13 standard:
14 sharding-algorithm-name: table-inline
15 sharding-column: order_id
通过配置可以看出来,我的策略比较简单,由于只有两个表,所以根据数据的 order_id列的值与 2 取模,值只有可能是 0 和 1,正好那就我的两个表的后缀名。
如果你要分更多的表,或者有其他自定义的分表策略和算法,可以参考官方文档进行设置。
接下来我们编写好应用端的程序,用接口请求新增一些数据,看是否按照我们的规则进入到不同的表中了。新增时我们先自行模拟 user_id , order_id 我们用一个本地的工具类利用 Snowflake 生成。
当然也可以借助 ShardingSphere 的配置帮我们自动生成:
1# 配置分库分表
2sharding:
3 key-generators:
4 snowflake:
5 type: SNOWFLAKE
6 props:
7 worker:
8 id: 123
9 sharding-algorithms:
10 table-inline:
11 props:
12 algorithm-expression: t_order_sharding_$->{order_id % 2 }
13 type: INLINE
14 tables:
15 t_order_sharding:
16 # 配置 t_order 表规则
17 actual-data-nodes: write-ds.t_order_sharding_$->{0..1}
18 table-strategy: #分表策略
19 standard:
20 sharding-algorithm-name: table-inline
21 sharding-column: order_id
22 # 主建生成策略
23 key-generate-strategy:
24 key-generator-name: snowflake
25 column: order_id
关注key-generators 部分的配置
我们用业务接口先接入后查询 4 条数据发现分别插入到了不同的表,重要的是,业务程序不需要做任何的改动,跟之前用一张表是同样的逻辑,比如用 SpringBoot+MybatisPlus 进行快速业务实现,之前怎么写还怎么写,ShardingSphere 配置好后会帮你自动做好相关的事情,不用担心。
1{
2 "code": 100000,
3 "msg": "",
4 "data": [
5 {
6 "orderId": 654340378203258881,
7 "userId": 12,
8 "createTime": "2021-10-11 15:15:03",
9 "updateTime": "2021-10-11 15:15:03"
10 },
11 {
12 "orderId": 1447456383522967551,
13 "userId": 12,
14 "createTime": "2021-10-11 14:59:14",
15 "updateTime": "2021-10-11 14:59:14"
16 },
17 {
18 "orderId": 1447457650144055296,
19 "userId": 12,
20 "createTime": "2021-10-11 15:02:50",
21 "updateTime": "2021-10-11 15:02:50"
22 },
23 {
24 "orderId": 1447457651482038272,
25 "userId": 12,
26 "createTime": "2021-10-11 15:02:52",
27 "updateTime": "2021-10-11 15:02:52"
28 }
29 ]
30}
根据配置将表分完,也不需要修改业务代码,原来怎么写还怎么写,很完美,不过需要注意的是你的 SQL,之前的写法是否支持需要根据官方文档查询,一般情况下普通的 SQL 都是可以的,有些比较特殊的不行,当然这些特殊的可能是开发偷懒没有合理地设计程序就只用一条 SQL 搞定,不是最合适的方式。比如一个复杂 SQL 完全可以用多条简单 SQL 再经过程序利用内存计算得出结果。
分库分表可以和读写分离混合配置,以下为一个完整的配置:
1spring:
2 profiles:
3 include: common-local
4 shardingsphere:
5 props:
6 sql:
7 #设置sql是否展示
8 show: true
9 check:
10 table:
11 metadata:
12 enabled: false
13 datasource:
14 names: write-ds,read-ds-0
15 write-ds:
16 jdbcUrl: jdbc:mysql://mysql.local.test.myapp.com:23306/test?allowPublicKeyRetrieval=true&useSSL=false&allowMultiQueries=true&serverTimezone=Asia/Shanghai&useSSL=false&autoReconnect=true&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull
17 type: com.zaxxer.hikari.HikariDataSource
18 driver-class-name: com.mysql.cj.jdbc.Driver
19 username: root
20 password: nicai
21 connectionTimeoutMilliseconds: 3000
22 idleTimeoutMilliseconds: 60000
23 maxLifetimeMilliseconds: 1800000
24 maxPoolSize: 50
25 minPoolSize: 1
26 maintenanceIntervalMilliseconds: 30000
27 read-ds-0:
28 jdbcUrl: jdbc:mysql://mysql.local.test.read1.myapp.com:23306/test?allowPublicKeyRetrieval=true&useSSL=false&allowMultiQueries=true&serverTimezone=Asia/Shanghai&useSSL=false&autoReconnect=true&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull
29 type: com.zaxxer.hikari.HikariDataSource
30 driver-class-name: com.mysql.cj.jdbc.Driver
31 username: root
32 password: nicai
33 connectionTimeoutMilliseconds: 3000
34 idleTimeoutMilliseconds: 60000
35 maxLifetimeMilliseconds: 1800000
36 maxPoolSize: 50
37 minPoolSize: 1
38 maintenanceIntervalMilliseconds: 30000
39 rules:
40 readwrite-splitting:
41 data-sources:
42 glapp:
43 write-data-source-name: write-ds
44 read-data-source-names:
45 - read-ds-0
46 load-balancer-name: roundRobin # 负载均衡算法名称
47 load-balancers:
48 roundRobin:
49 type: ROUND_ROBIN # 一共两种一种是 RANDOM(随机),一种是 ROUND_ROBIN(轮询)
50 # 配置分库分表
51 sharding:
52 key-generators:
53 snowflake:
54 type: SNOWFLAKE
55 props:
56 worker:
57 id: 123
58 sharding-algorithms:
59 table-inline:
60 props:
61 algorithm-expression: t_order_sharding_$->{order_id % 2 }
62 type: INLINE
63 tables:
64 t_order_sharding:
65 # 配置 t_order 表规则
66 actual-data-nodes: write-ds.t_order_sharding_$->{0..1}
67 table-strategy: #分表策略
68 standard:
69 sharding-algorithm-name: table-inline
70 sharding-column: order_id
71 key-generate-strategy:
72 key-generator-name: snowflake
73 column: order_id
单库分表-老业务
请听下回分解