
硬件
“没有硬件支持,你破解个屁”

GPU

什么是 GPU?
GPU 是 Graphics Processing Unit 的缩写,中文翻译为图形处理器。GPU 最初是为了提高电脑处理图形的速度而设计的,主要负责图像的计算和处理。GPU 通过并行计算的方式,可以同时执行多个任务,大大提高了图形和数据处理的速度和效率。
近年来,由于其并行计算的特性,GPU 也被应用于一些需要大量计算的领域,如机器学习、深度学习、数据挖掘、科学计算等。在这些领域中,GPU 可以加速训练模型、处理海量数据等计算密集型任务,显著提高了计算效率和速度。因此,GPU 已成为现代计算机的重要组成部分,被广泛应用于各种领域。
GPU 是如何工作的?
GPU 的工作原理和 CPU 类似,都是通过执行指令来完成计算任务的。不同的是,CPU 是通过串行执行指令的方式来完成计算任务的,而 GPU 是通过并行执行指令的方式来完成计算任务的。GPU 的并行计算方式可以同时执行多个任务,大大提高了计算效率和速度。
可以参考这个视频来了解 GPU 的工作原理:https://www.bilibili.com/video/BV1VW411i7ah/?spm_id_from=333.337.search-card.all.click&vd_source=6fb7f58b736bb5913c33073b42979450
GPU 和 CPU 的区别
GPU 和 CPU 的区别主要体现在以下几个方面:
架构设计不同:CPU 的设计注重单线程处理能力,通常有少量的计算核心和更多的高速缓存。GPU 则是面向并行处理的设计,通常拥有大量的计算核心,但缓存较小。
计算方式不同:CPU 在处理任务时,主要通过执行指令流的方式进行计算。而 GPU 则是通过执行大量的线程,同时进行并行计算,以提高计算效率。GPU 的并行计算能力可以同时处理许多相似的任务,适用于大规模的计算密集型任务,例如图像处理、机器学习等。
用途不同:CPU 主要用于通用计算任务,例如文件处理、操作系统运行、编程等。GPU 则主要用于图形处理、游戏、计算密集型任务,例如机器学习、深度学习等。
总结来说,GPU 和 CPU 都有各自的优势和适用场景,它们通常是相互协作的。例如,在机器学习中,CPU 通常用于数据的预处理和模型的训练过程,而 GPU 则用于模型的计算推理过程。
我们常说的显卡就是 GPU 吗?
是的,我们通常所说的显卡(Graphics Card)就是安装了 GPU 的设备。显卡除了包含 GPU 之外,还包括显存、散热器、显卡 BIOS 等部件。显卡通过将 CPU 传输的数据转换为图像信号,控制显示器输出图像。
在一些需要大量图像处理或计算的应用场景中,GPU 可以比 CPU 更高效地完成任务。因此,现代的显卡也广泛应用于机器学习、深度学习等领域的加速计算,甚至被用于科学计算、天文学、地质学、气象学等领域。
关于显卡,你可能听说过“集成显卡”、“独立显卡”,其实,显卡的集成和独立通常是指显存的不同管理方式,它们有以下区别:
集成显卡:集成显卡通常是指将显存集成在主板芯片组或处理器内部的显卡。这种显卡通常性能较差,适用于一些简单的应用场景,例如日常办公、网页浏览等。
独立显卡:独立显卡通常是指显存独立于主板芯片组或处理器,有自己的显存和显存控制器。这种显卡性能更加强大,适用于游戏、图形处理、科学计算等需要大量显存和计算性能的应用场景。
共享显存:共享显存通常是指显存与系统内存共享使用,也就是一部分系统内存被划分为显存使用。这种方式适用于一些轻度图形处理的应用场景,例如电影播放、网页浏览等。
总的来说,集成显卡通常性能较差,适用于简单应用场景,独立显卡性能更加强大,适用于需要大量显存和计算性能的应用场景,而共享显存则是一种折中的方案,适用于一些轻度图形处理的应用场景。
GPU 厂商
海外头部 GPU 厂商:
- Nvidia:Nvidia 是目前全球最大的 GPU 制造商之一,Nvidia 主要生产针对游戏玩家、数据中心和专业用户等不同领域的 GPU 产品。
- AMD:全球知名的 GPU 制造商之一。AMD 主要生产用于个人电脑、工作站和服务器等不同领域的 GPU 产品。
- Intel:目前也开始进军 GPU 市场。Intel 主要生产用于个人电脑、工作站和服务器等不同领域的 GPU 产品。
国内 GPU 厂商:
海光信息、寒武纪、龙芯中科、景嘉微等。
芯片“卡脖子” 说的就是 GPU 吗?
是,但不全是。
“芯片卡脖子"是指全球半导体短缺现象,也称为"芯片荒"或"半导体荒”,指的是 2020 年以来由新冠疫情和其他因素导致的全球半导体供应不足的局面。这种供应短缺已经影响了多个行业,包括汽车、电子产品、通信设备等。中国作为世界上最大的半导体市场之一,也受到了这种供应短缺的影响。
我国在半导体领域的自主研发和制造水平相对较低,依赖进口芯片来支撑其经济和工业发展。受全球芯片短缺影响,我国的一些关键行业,特别是汽车、电子和通信行业,出现了供应短缺和价格上涨等问题,对其经济造成了一定的影响。为了应对这种情况,政府加强了对半导体行业的支持,鼓励本土企业增加芯片研发和生产能力,以减轻对进口芯片的依赖。
具体与 GPU 相关的:2022 年 8 月 31 日,为符合美国政府要求,Nvidia 和 AMD 的高端 GPU 将在中国暂停销售,包括 Nvidia 的 A100、H100 以及 AMD 的 MI100 和 MI200 芯片
英伟达在 SEC 文件上官方确认此事,称是 8 月 26 日收到美国政府的通知。
“
SEC 文件是由上市公司、上市公司内部人士、券商提交给美国证券交易委员会(SEC) 的财务报表或者其他正式文件。
”
nvidia (英伟达)

根据 2021 年第四季度的市场研究报告,英伟达在全球离散显卡市场占有率为 51.2%,位列第一,超过了其竞争对手 AMD 的市场份额。而在全球 GPU 市场(包括离散显卡和集成显卡)中,英伟达的市场占有率为 18.8%,位列第二,仅次于 Intel 的市场份额。
nvidia 的产品矩阵
- GeForce 系列:主要面向消费者市场,包括桌面显卡和笔记本电脑显卡等,以高性能游戏和多媒体应用为主要应用场景。
- Quadro 系列:主要面向专业工作站市场,包括电影和电视制作、建筑设计、科学计算、医疗影像等领域,具有高性能、高稳定性和优秀的图形渲染能力。
- Tesla 系列:主要面向高性能计算市场,包括科学计算、深度学习、人工智能等领域,具有极高的计算性能和数据吞吐量,支持多 GPU 集群计算。
- Tegra 系列:主要面向移动和嵌入式市场,包括智能手机、平板电脑、汽车、无人机等领域,具有高性能、低功耗、小尺寸等特点。
- Jetson 系列:主要面向人工智能应用市场,包括机器人、自动驾驶、智能视频分析等领域,具有高性能、低功耗、小尺寸等特点。
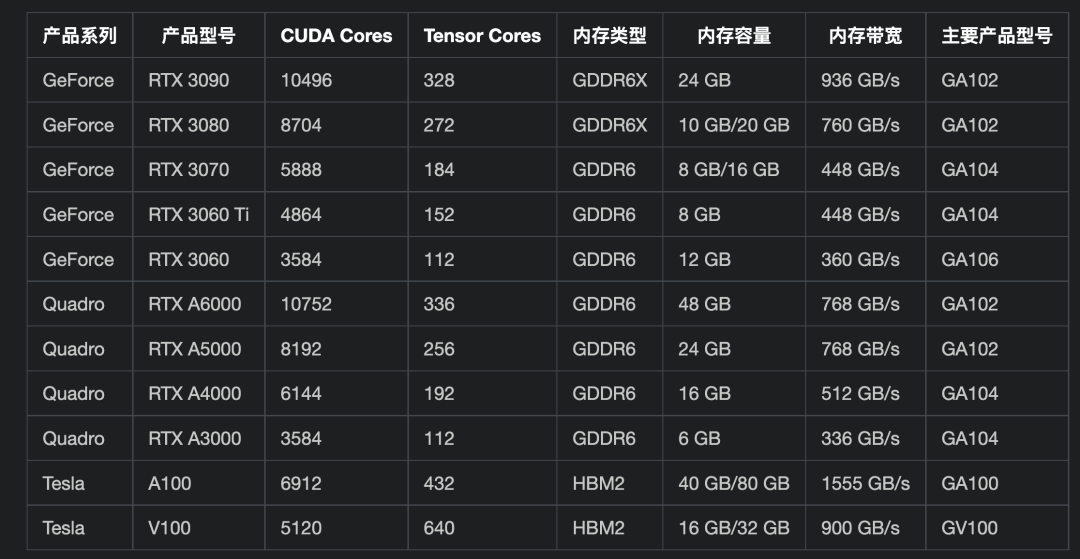
可能你对上面这些产品系列、型号和名词不太了解,没有什么概念,那这样,咱们先建立个价格概念。我们以当下在人工智能领域广泛应用的 GPU A100 为例,看一下它的价格:
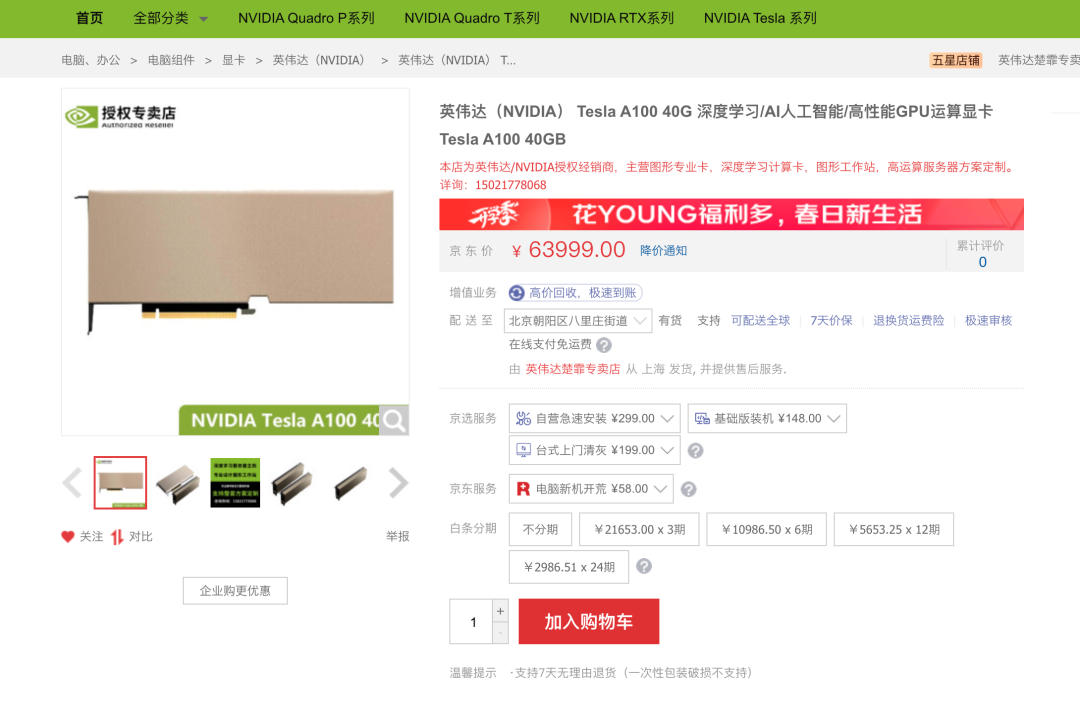
就是因为这个价格,所以 A100 也被称为“英伟达大金砖”.
为什么要单独说英伟达呢?因为算力是 人工智能的“力量源泉”,GPU 是算力的“主要供应商”。而英伟达是全球最大的 GPU 制造商,并且它的 GPU 算力是最强的,比如 A100 GPU 算力是 10.5 petaFLOPS,而 AMD 的 MI100 GPU 算力是 7.5 petaFLOPS。
不明白什么意思?Peta 是计量单位之一,它代表的是 10 的 15 次方。因此,1 petaFLOPS(PFLOPS)表示每秒可以完成 10 的 15 次浮点运算。所以,A100 GPU 算力为 10.5 petaFLOPS,意味着它可以每秒完成 10.5 万亿次浮点运算。
AI
什么是人工智能 (Artificial Intelligence-AI)?
人工智能是指一种计算机技术,它使得计算机系统可以通过学习、推理、自适应和自我修正等方法,模拟人类的智能行为,以实现类似于人类的智能水平的一系列任务。这些任务包括语音识别、自然语言处理、图像识别、机器翻译、自动驾驶、智能推荐和游戏等。人工智能的核心是机器学习,它是通过使用大量数据和算法训练计算机系统,使其能够识别模式、做出预测和决策。人工智能还涉及到其他领域,如自然语言处理、计算机视觉、机器人技术、知识表示和推理等。人工智能被广泛应用于各种领域,如医疗、金融、交通、制造业、媒体和游戏等,为这些领域带来了更高的效率和创新。
人工智能细分领域
人工智能领域有很多分支领域,以下列举一些比较常见的:
- 机器学习(Machine Learning):研究如何通过算法和模型让计算机从数据中学习和提取规律,以完成特定任务。
- 深度学习(Deep Learning):是机器学习的一种,使用多层神经网络来学习特征和模式,以实现对复杂任务的自动化处理。
- 自然语言处理(Natural Language Processing, NLP):研究如何让计算机理解、分析、处理人类语言的方法和技术。
- 计算机视觉(Computer Vision):研究如何让计算机“看懂”图像和视频,并从中提取有用的信息和特征。
- 机器人学(Robotics):研究如何设计、构建和控制机器人,让它们能够完成特定任务。
- 强化学习(Reinforcement Learning):是一种机器学习的方法,通过与环境的交互和反馈来学习最优行动策略。
- 知识图谱(Knowledge Graph):是一种将知识以图谱的形式进行组织、表示和推理的方法,用于实现智能搜索、推荐等应用。
- 语音识别(Speech Recognition):研究如何让计算机识别和理解人类语音,以实现语音输入、语音控制等功能。
当然以上这些分支领域互相也有交叉和相互影响,比如深度学习在计算机视觉、自然语言处理和语音识别等领域都有应用;计算机视觉和自然语言处理也经常结合在一起,比如在图像字幕生成和图像问答等任务中。此外,人工智能还与其他领域如控制工程、优化学、认知科学等存在交叉。
NLP
我们具体地来看一下自然语言处理(NLP)这个分支领域,它是人工智能的一个重要分支,也是人工智能技术在实际应用中最为广泛的应用之一。
NLP(Natural Language Processing,自然语言处理)旨在让计算机能够理解、解析、生成和操作人类语言。
NLP 技术可以用于文本分类、情感分析、机器翻译、问答系统、语音识别、自动摘要、信息抽取等多个方面。实现 NLP 技术通常需要使用一些基础的机器学习算法,例如文本预处理、词嵌入(word embedding)、分词、词性标注、命名实体识别等等。这些算法可以从大量的语料库中学习到语言的结构和规律,并通过统计分析和机器学习模型进行自然语言的处理和应用。
近年来,随着深度学习技术的发展,NLP 领域也出现了一些基于深度学习的新模型,例如 Transformer 模型和 BERT 模型等。这些模型通过使用大规模语料库进行预训练,可以在多个 NLP 任务中取得优秀的表现。同时,也涌现了一些新的应用领域,例如对话系统、智能客服、智能写作、智能问答等。
Transformer 是什么?
上文我们提到人工智能的分支领域之间会有交叉,Transformer 算是深度学习和 NLP 的交叉领域。
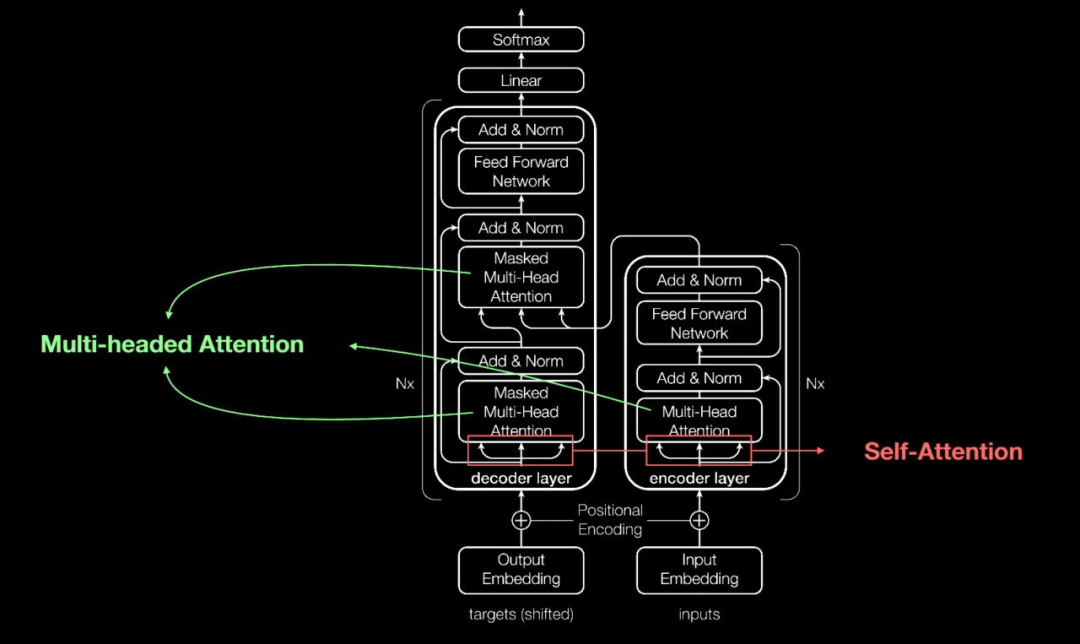
Transformer 模型是深度学习中的一种神经网络模型,该模型是由 Google 开源的。
Transformer 模型最初是在 2017 年发表的论文"Attention Is All You Need"中提出的,随后被加入到 TensorFlow 等深度学习框架中,方便了广大开发者使用和扩展。目前,Transformer 模型已经成为自然语言处理领域中最流行的模型之一。
“
TensorFlow 是一种用于实现神经网络模型的开源深度学习框架。因此,可以使用 TensorFlow 实现 Transformer 模型。实际上,TensorFlow 团队已经提供了一个名为“Tensor2Tensor”的库,其中包含了 Transformer 模型的实现。此外,许多研究人员和工程师也使用 TensorFlow 实现自己的 Transformer 模型,并将其用于各种 NLP 任务中。
”
Transformer 特别擅长处理序列数据,其中包括了 NLP 领域的自然语言文本数据。在 NLP 领域中,Transformer 模型被广泛应用于各种任务,例如机器翻译、文本摘要、文本分类、问答系统、语言模型等等。相比于传统的基于循环神经网络(RNN)的模型,Transformer 模型通过使用注意力机制(self-attention)和多头注意力机制(multi-head attention)来建模序列中的长程依赖性和关系,有效地缓解了 RNN 模型中梯度消失和梯度爆炸的问题,从而在 NLP 任务上取得了很好的表现。因此,可以说 Transformer 是 NLP 领域中的一种重要的深度学习模型,也是现代 NLP 技术的重要组成部分。
Transformer 模型的实现
Transformer 模型只是一个抽象的概念和算法框架,具体的实现还需要考虑许多细节和技巧。在实际应用中,需要根据具体的任务和数据集进行模型的设计、参数调整和训练等过程。此外,还需要使用特定的软件框架(如 TensorFlow、PyTorch 等)进行实现和优化,以提高模型的效率和准确性。
实现 Transformer 模型可以使用深度学习框架,如 TensorFlow、PyTorch 等。一般来说,实现 Transformer 模型的步骤如下:
- 数据准备:准备训练和测试数据,包括语料数据和标签数据等。模型架构设计:确定模型的结构,包括 Transformer 的编码器和解码器部分,以及注意力机制等。
- 模型训练:使用训练数据对模型进行训练,并对模型进行调优,以达到较好的预测效果。
- 模型评估:使用测试数据对模型进行评估,包括损失函数的计算、精度、召回率、F1 值等。
- 模型部署:将训练好的模型部署到生产环境中,进行实际的应用。
业界流行的实现方式是使用深度学习框架,如 TensorFlow 或 PyTorch,在现有的 Transformer 模型代码基础上进行二次开发,以满足自己的需求。同时,也有一些第三方的 Transformer 库,如 Hugging Face 的 Transformers 库,可供直接使用,方便快捷。
还有没有其他模型 ?
类似于 Transformer 的模型有许多,其中一些主要的模型包括:
- BERT(Bidirectional Encoder Representations from Transformers):BERT 是由 Google 在 2018 年推出的预训练语言模型,采用了 Transformer 模型的编码器部分,并使用双向的 Transformer 模型来对输入的文本进行建模。
- GPT(Generative Pre-trained Transformer):GPT 是由 OpenAI 在 2018 年推出的预训练语言模型,采用了 Transformer 模型的解码器部分,主要用于生成文本。
- XLNet:XLNet 是由 CMU、Google 和 Carnegie Mellon University 的研究人员在 2019 年提出的一种预训练语言模型,它使用了自回归 Transformer 模型和自回归 Transformer 模型的结合,具有更好的生成性能和语言理解能力。
- T5(Text-to-Text Transfer Transformer):T5 是由 Google 在 2019 年推出的一种基于 Transformer 的通用文本转换模型,可以处理各种 NLP 任务,如文本分类、问答、文本摘要等。
- RoBERTa(Robustly Optimized BERT Pretraining Approach):RoBERTa 是 Facebook 在 2019 年推出的预训练语言模型,它通过对 BERT 训练过程进行优化,提高了在多种 NLP 任务上的性能表现。
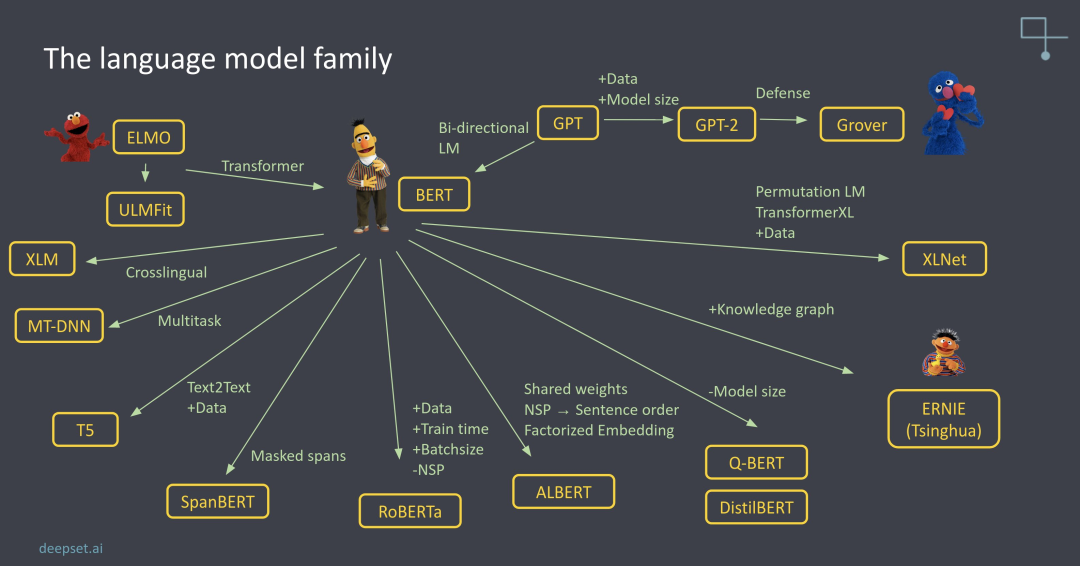
这些模型都基于 Transformer 架构,并通过不同的优化和改进来提高性能和应用范围。下面一张图是模型的家族树:
GPT 模型
2018 年 OpenAI 公司基于 Transformer 结构推出 GPT-1 (Generative Pre-training Transformers, 创造型预训练变换模型),参数量为 1.17 亿个,GPT-1 超越 Transformer 成为业内第一。2019 年至 2020 年,OpenAI 陆续发布 GPT-2、GPT-3,其参数量分别达 到 15 亿、1750 亿,其中,GPT-3 训练过程中直接以人类自然语言作为指令,显著提升了 LLM 在多种语言场景中的性能。
ChatGPT

ChatGPT 是美国 OpenAI 公司研发的对话 AI 模型,是由人工智能技术支持的自然语言处理(NLP,Natural Language Processing)工具,于 2022 年 11 月 30 日正式发布。它能够学习、理解人类语言,并结合对话上下文,与人类聊天互动,也可撰写稿件、翻译文字、编程、编写视频脚本等。截至 2023 年 1 月底,ChatGPT 月活用户已高达 1 亿,成为史上活跃用户规模增长最快的应用
与现存的其他同类产品相比,ChatGPT 的独特优势在于:
- 基于 GPT-3.5 架构,运用海量语料库训练模型,包括真实生活中的对话,使 ChatGPT 能做到接近与人类聊天
- 应用新技术 RLHF (Reinforcement Learning with Human Feedback,基于人类反馈的强化学习),从而能更准确地理解并遵循人类的思维、价值观与需求
- 可在同一阶段内完成模型训练
- 具有强大算力、自我学习能力和适应性,且预训练通用性较高
- 可进行连续多轮对话,提升用户体验
- 更具独立批判性思维,能质疑用户问题的合理性,也能承认自身知识的局限性,听取用户意见并改进答案。
GPT-3.5
ChatGPT 使用的 GPT-3.5 模型是在 GPT-3 的基础上加入 Reinforcement Learning from Human Feedback(RLHF,人类反馈强化学习)技术和近段策略优化算法,其目的是从真实性、无害性和有用性三个方面优化输出结果,降低预训练模型生成种族歧视、性别歧视等有害内容的风险。
ChatGPT 训练的过程主要有三个阶段。
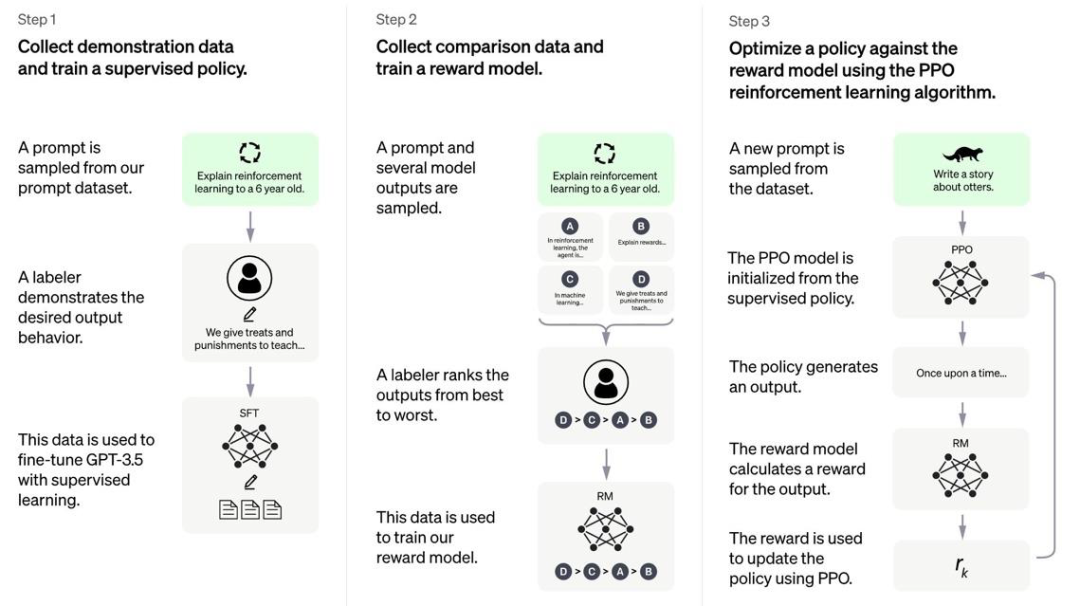
- 第一步是训练监督策略,人类标注员对随机抽取的提示提供预期结果,用监督学习的形式微调 GPT-3.5,生成 Supervised Fine-Tuning(SFT)模型,使 GPT-3.5 初步理解指令,这一步与先前的 GPT-3 模型训练方式相同,类似于老师为学生提供标答的过程。
- 第二步是奖励模型,在 SFT 模型中随机抽取提示并生成数个结果,由人类标注员对结果的匹配程度进行排序,再将问题与结果配对成数据对输入奖励模型进行打分训练,这个步骤类似于学生模拟标答写出自己的答案,老师再对每个答案进行评分。
- 第三步是 Proximal Policy Optimization(PPO,近段策略优化),也是 ChatGPT 最突出的升级。模型通过第二步的打分机制,对 SFT 模型内数据进行训练,自动优化迭代,提高 ChatGPT 输出结果的质量,即是学生根据老师反馈的评分,对自己的作答进行修改,使答案更接近高分标准。
ChatGPT 的优势在于:
- 使用 1750 万亿参数的 GPT-3 为底层模型进行预训练,为全球最大的语言模型之一
- 算力上得到微软支持,使用上万片 NVIDIA A100 GPU 进行训练,模型的运行速度得到保障(从这里就看出硬件的重要性了,A100 “卡脖子”确实很难受,不过之前各厂都囤货了,短期应该能满足现状,而且作为 A00 的平替 A800 即将出货,训练效率快速提升,应该也能满足需求。)
- 算法上使用奖励模型和近端优化策略进行迭代优化, 将输出结果与人类预期答案对齐,减少有害性、歧视性答案,使 ChatGPT 更拟人化,让用户感觉沟通的过程更流畅。
GPT-4
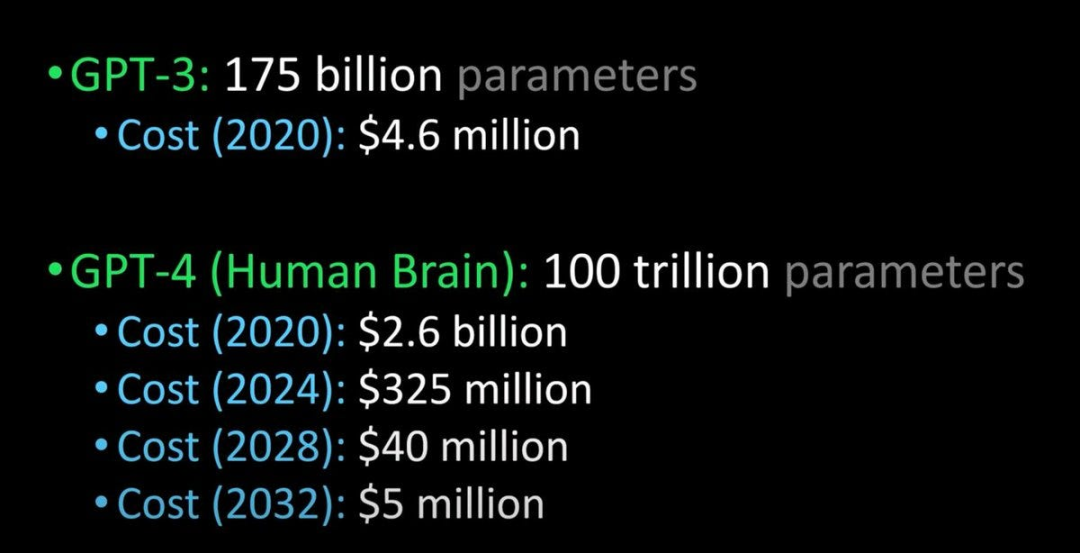
据德国媒体 Heise 消息,当地时间 3 月 9 日一场人工智能相关活动上,四名微软德国员工在现场介绍了包括 GPT 系列在内的大语言模型(LLM),在活动中,微软德国首席技术官 Andreas Braun 表示 GPT-4 即将发布。
GPT-4 已经发展到基本上「适用于所有语言」:你可以用德语提问,然后用意大利语得到答案。借助多模态,微软和 OpenAI 将使「模型变得全面」。将提供完全不同的可能性,比如视频。
AIGC 模型
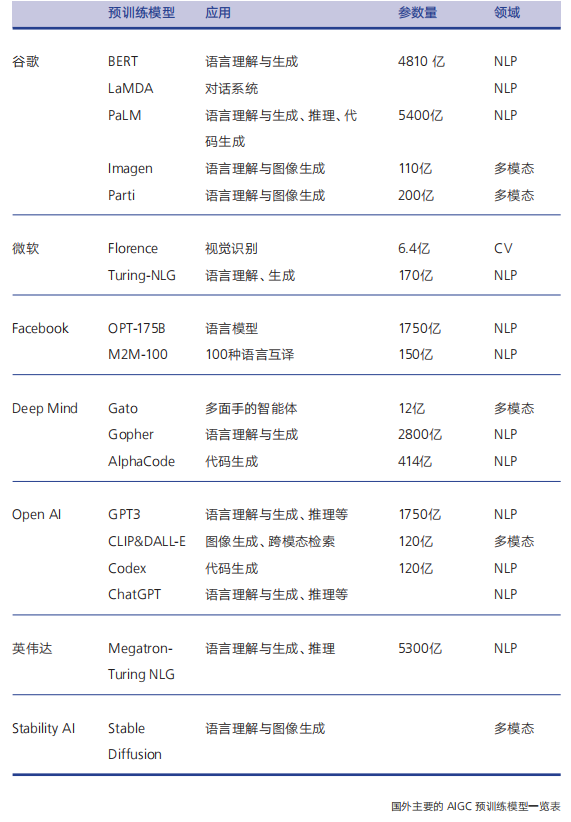
在人工智能内容生成领域,除了 OpenAI, 还有其他玩家,来看一下目前头部玩家的情况:
人工智能突破摩尔定律
“
摩尔定律是由英特尔公司创始人之一戈登·摩尔于 1965 年提出的一项预测。这项预测认为,在集成电路上可容纳的晶体管数量每隔 18 至 24 个月会翻一番,而成本不变或者成本减少。
简单来说,摩尔定律预测了随着时间的推移,计算机芯片上能集成的晶体管数量将以指数级别增长,而成本将持续降低。这意味着计算机性能将在同样的芯片面积上不断提高,同时计算机的成本也会不断降低。
摩尔定律在过去几十年的计算机工业中发挥了重要的作用,它是计算机发展的重要标志之一,但近年来随着摩尔定律趋于极限,一些人开始怀疑其可持续性。
”
摩尔定律的定义归纳起来,主要有以下三种版本:
- 集成电路上可容纳的晶体管数目,约每隔 18 个月便增加一倍。
- 微处理器的性能每隔 18 个月提高一倍,或价格下降一半。
- 相同价格所买的电脑,性能每隔 18 个月增加一倍。
随着模型的迭代,对算力的需求也越来越大了: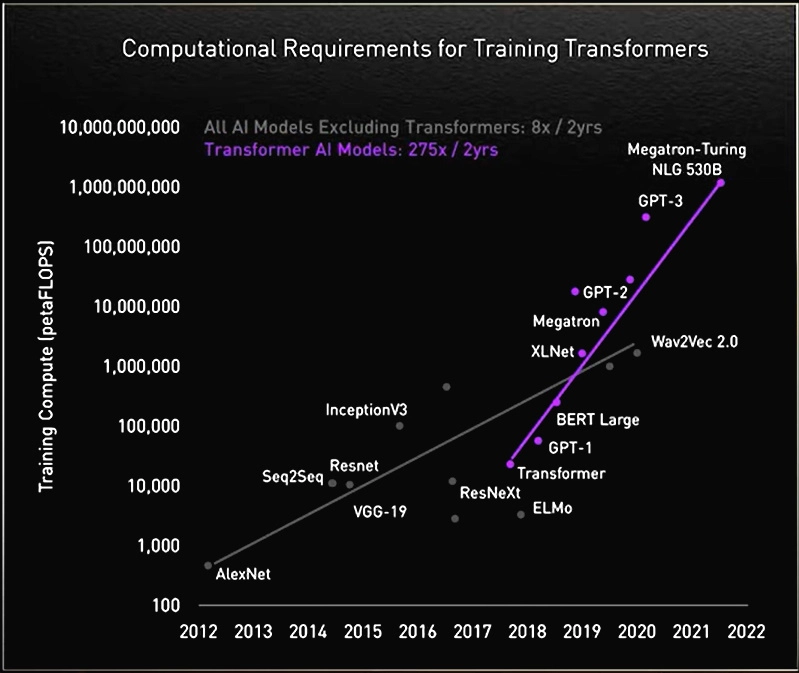
目前看人工智能对算力的需求已经突破了摩尔定律
未来
目前我已在编程、邮件书写、知识学习等多个场景开始使用 chatGPT,未来有计划开发 chatGPT的应用程序,让更多人能够体验到 chatGPT 的魅力。
未来已来,缺少的不是技术,而是想象力!
参考
- https://blogs.nvidia.com/blog/2009/12/16/whats-the-difference-between-a-cpu-and-a-gpu/
- https://www.zhihu.com/question/19903344
- https://www.sec.gov/Archives/edgar/data/1045810/000104581022000146/nvda-20220826.htm
- https://blogs.nvidia.com/blog/2022/03/25/what-is-a-transformer-model/
https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf