
回顾
在上一文中我们使用 LlamaIndex 整合 智谱 AI 的 GLM-4 和 Embedding-3 模型一起构建 RAG 应用。
在上篇文章的最后,我们发现因为 Embedding-3 模型是同步调用的,所以从测试效果看比较慢。每一次运行都产生了大量的 http 同步请求。文末我说解决的办法可以在本地部署一个开源的 embedding 模型,这样就不会产生远程的 http 调用了,而且也比较省钱。
这是个办法,但实际上还有其他的好办法。
我们可以将 文档通过 embedding 模型产生的向量存储起来,这样相同的文档,只有在第一次 embedding 时会慢一些,再次检索时,可以快速地将已经保存好的向量查询出来使用。
本地文件存储
利用 LlamaIndex 的 API ,我们可以非常方便地把向量存储到本地文件,以下是一个例子,我把向量存储到项目的 index目录下:
1def load_or_create_index():
2
3 # 检查是否存在有效的持久化索引
4 if (
5 os.path.exists("index")
6 and os.path.isdir("index")
7 and any(file.endswith(".json") for file in os.listdir("index"))
8 ):
9 print("正在加载现有索引。..")
10 storage_context = StorageContext.from_defaults(persist_dir="index")
11 index = load_index_from_storage(storage_context)
12 else:
13 print("未找到有效的现有索引,正在创建新索引。..")
14 # 使用预定义的 DATA_DIR 常量
15 documents = SimpleDirectoryReader("./data").load_data()
16 # 创建新索引,显示 embedding 进度
17 index = VectorStoreIndex.from_documents(documents, show_progress=True)
18 # 持久化索引
19 index.storage_context.persist(persist_dir="index")
20 print("索引已创建并保存到本地。")
21
22 return index
看起来代码多,实际上重要的就是这两行:
1storage_context = StorageContext.from_defaults(persist_dir="index")
2index = load_index_from_storage(storage_context)
也很容易理解,见文知意。
索引创建后,index 会自动创建一些文件来保存向量信息:
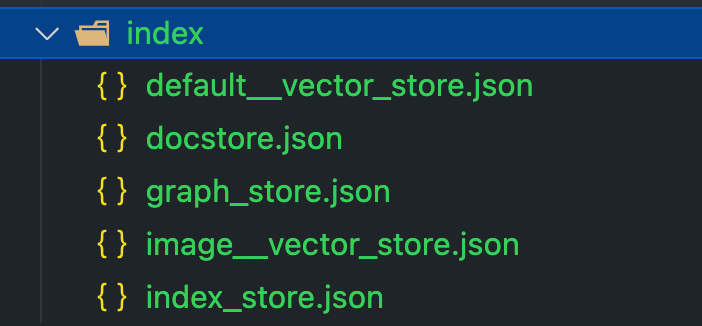
向量数据库
一般情况下,比如小型项目,将向量数据保存在系统文件中就已经够用了。但是,在中大型项目中,由于数据规模较大,使用人数较多,为了方便管理和扩展,我们会使用专业的向量数据库来存储和管理向量数据。
你可以借助下图了解下向量数据库在 AIGC 应用架构中的位置和作用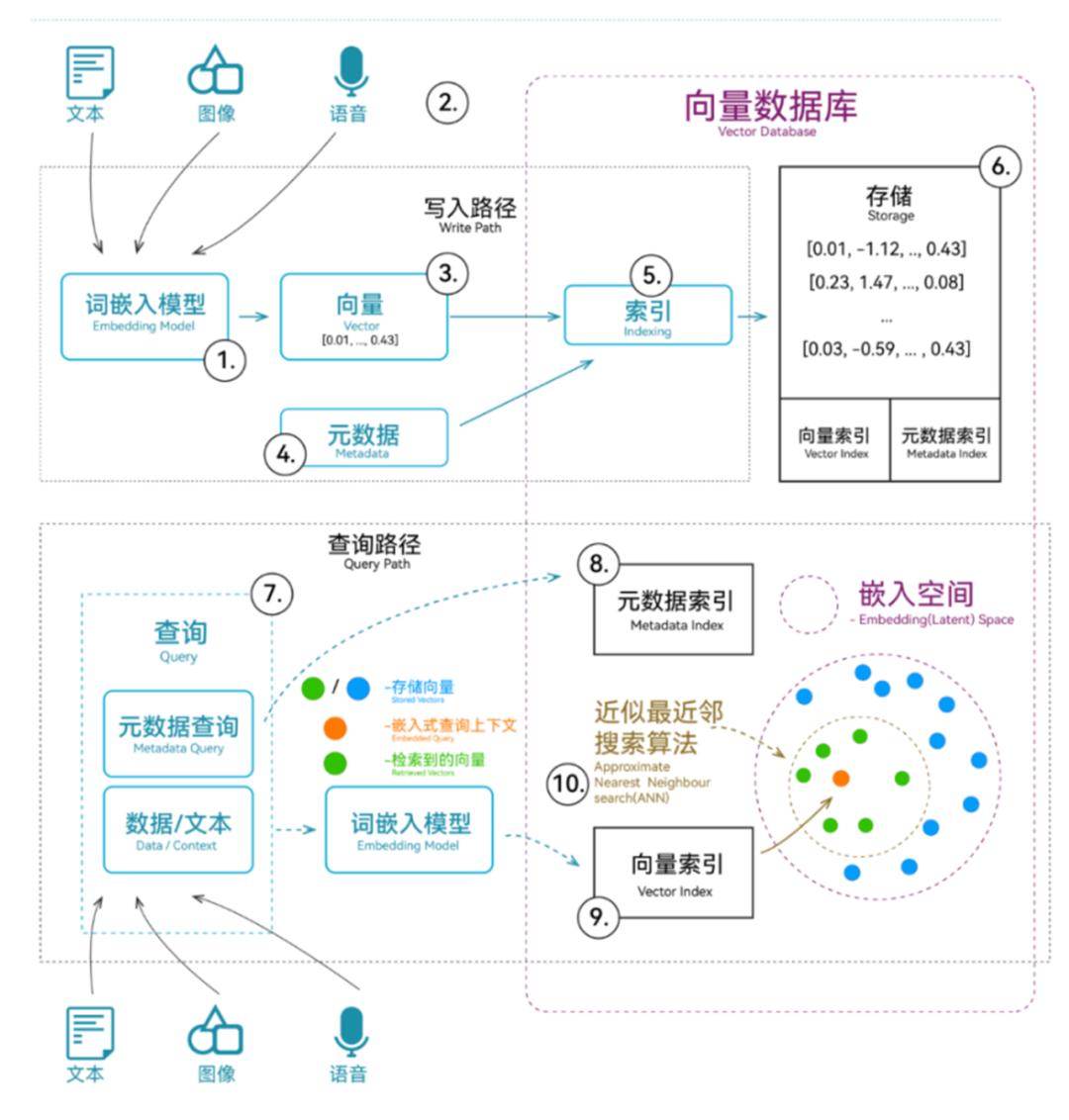
向量数据库选型
“
RAG 系统的成功在很大程度上取决于其高效地获取和处理海量信息的能力。向量数据库又在其中发挥了不可替代的作用,并构成了 RAG 系统的核心
不看不知道,作为一个数据库软件 ,目前向量数据库领域是真卷啊,打眼一看至少有几十个。知名的也得有 10 几个。
说实话,最开始还真有些茫然,有点儿挑花眼了,我们这里列举几个知名的向量数据库:
Milvus 是一个 2019 年开源的纯向量数据库,号称全球最先进的开源向量数据库。它是
LF AI & Data Foundation(简称 LFAI,它相当于 CNCF 在云原生界的地位)赞助的毕业项目Chroma 是一个相对较新的向量数据库,目前它的设计确实是以单节点模式为主,主要用于中小型应用或开发测试环境。然而,对于需要更高可用性和横向扩展能力的生产环境,Chroma 当前的版本可能还不完全满足需求。Chroma 内置了
SQLite作为其底层存储引擎Weaviate :是一个云原生的、开源的向量数据库。专为大规模的向量数据存储和检索设计。它结合了向量搜索和图数据库的优势,适用于机器学习、推荐系统、图像识别和自然语言处理等场景。
Faiss :由 Facebook AI Research 开发的 Faiss 是一个开源库,用于快速、密集向量相似性搜索和分组
Qdrant 是一个开源的向量数据库,专为高效的大规模向量数据存储和检索设计。它适用于机器学习、推荐系统、图像识别和自然语言处理等场景,提供了高性能和易用性的结合。
PGVector 是一个基于 PostgreSQL 的扩展插件,旨在提供强大的向量存储和查询功能,PGVector 可以无缝集成到现有的 PostgreSQL 数据库中,用户无需迁移现有的数据库即可开始使用向量搜索功能。因为是 PostgreSQL 插件,借助 PostgreSQL 的长期开发和优化,PGVector 继承了其可靠性和稳健性,同时在向量化处理方面进行了增强。
整体上看在向量数据库领域有这么几类玩家:
- 专做向量数据库的,大部分是开源的,如 Chroma、Weaviate 等
- 做关系型数据库的扩展或插件,如 PGVector
- 做 NoSQL 数据库的功能扩展或兼容,如
Elasticsearch、Redis、ClickHouse等
太多了,真是太多了,最开始我做选型的时候真是有点儿挑花眼了。最后,一点点缩小范围,最终进入决赛圈的是:
- Qdrant
- Weaviate
- Milvus
你可以通过 https://zilliz.com.cn/comparison 来了解各向量数据库之间的对比情况


最终我选择了 Milvus 原因是:
- 它确实很知名,看了那么多评测,各方面性能都很能打
- 我个人觉得比较重要的是它还有数据库管理客户端
attu
向量数据库不像我之前使用过的关系型数据库,一般是没有像 Navicat 、DataGrip 这样的数据库管理客户端的。一般只有 CRUD 接口或 CLI 客户端。这对于初学者了解和学习向量数据库不太友好,所以我还是特别希望有这样一个有 GUI 图形界面、看得见摸得着的客户端的,而 Milvus 正好是有的。就是 attu (可以通过 https://github.com/zilliztech/attu 下载)
如果你也和我一样在 Qdrant、Weaviate、Milvus 之间纠结的话,可以参考网上一位大哥对它们的评价:“总结起来就是,Qdrant 开销特别小,Weaviate 支持向量搜索、对象存储和倒排索引的组合,Milvus 性能最强、花活最多。”
Chroma
LlamaIndex 官方的例子使用的是 Chroma 作为向量数据库进行向量存储。
默认情况下,Chroma 会将向量数据存储在本地文件系统中。我们就以 Chroma 为例写个例子。
Chroma 不需要安装外部软件,安装导入相关的库就可了
1import chromadb
2from llama_index.vector_stores.chroma import ChromaVectorStore
在导入了 Chroma 相关的库后,我们将 load_or_create_index() 方法调整一下:
1def load_or_create_index():
2
3 # 初始化客户端,设置数据保存路径
4 db = chromadb.PersistentClient(path="./chroma_db")
5 # 创建或获取集合
6 chroma_collection = db.get_or_create_collection("quickstart")
7 # 将 chroma 指定为上下文的 vector_store
8 vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
9 storage_context = StorageContext.from_defaults(vector_store=vector_store)
10
11 # 检查集合是否为空
12 if chroma_collection.count() == 0:
13 # 如果集合为空,加载文档并创建新的索引
14 documents = SimpleDirectoryReader("./data").load_data()
15 index = VectorStoreIndex.from_documents(documents, storage_context=storage_context)
16 print("已创建新的索引")
17 else:
18 # 如果集合不为空,直接从 vector_store 加载索引
19 index = VectorStoreIndex.from_vector_store(vector_store, storage_context=storage_context)
20 print("已加载现有索引")
21
22 return index
可以看到也很简单。程序运行后,chroma_db 文件夹下会自动创建以下文件:
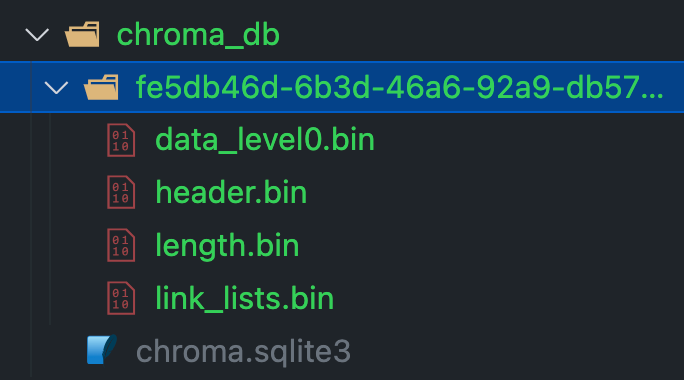
前文中我们提到过 chroma 内置了 SQLite ,这里就体现出来了。
Milvus
在使用 Milvus 前我们需要先安装它。它有多种安装方式,我本地通过 Docker-Compose 安装
1version: '3.5'
2
3services:
4 etcd:
5 container_name: milvus-etcd
6 image: quay.io/coreos/etcd:v3.5.14
7 environment:
8 - ETCD_AUTO_COMPACTION_MODE=revision
9 - ETCD_AUTO_COMPACTION_RETENTION=1000
10 - ETCD_QUOTA_BACKEND_BYTES=4294967296
11 - ETCD_SNAPSHOT_COUNT=50000
12 volumes:
13 - ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/etcd:/etcd
14 command: etcd -advertise-client-urls=http://127.0.0.1:2379 -listen-client-urls http://0.0.0.0:2379 --data-dir /etcd
15 healthcheck:
16 test: ["CMD", "etcdctl", "endpoint", "health"]
17 interval: 30s
18 timeout: 20s
19 retries: 3
20
21 minio:
22 container_name: milvus-minio
23 image: minio/minio:RELEASE.2023-03-20T20-16-18Z
24 environment:
25 MINIO_ACCESS_KEY: minioadmin
26 MINIO_SECRET_KEY: minioadmin
27 ports:
28 - "9001:9001"
29 - "9000:9000"
30 volumes:
31 - ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/minio:/minio_data
32 command: minio server /minio_data --console-address ":9001"
33 healthcheck:
34 test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]
35 interval: 30s
36 timeout: 20s
37 retries: 3
38
39 standalone:
40 container_name: milvus-standalone
41 image: milvusdb/milvus:v2.3.0
42 command: ["milvus", "run", "standalone"]
43 security_opt:
44 - seccomp:unconfined
45 environment:
46 MINIO_REGION: us-east-1
47 ETCD_ENDPOINTS: etcd:2379
48 MINIO_ADDRESS: minio:9000
49 volumes:
50 - ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/milvus:/var/lib/milvus
51 healthcheck:
52 test: ["CMD", "curl", "-f", "http://localhost:9091/healthz"]
53 interval: 30s
54 start_period: 90s
55 timeout: 20s
56 retries: 3
57 ports:
58 - "19530:19530"
59 - "9091:9091"
60 depends_on:
61 - "etcd"
62 - "minio"
63
64networks:
65 default:
66 name: milvus
安装好以后,可以看到它内部有三个容器:
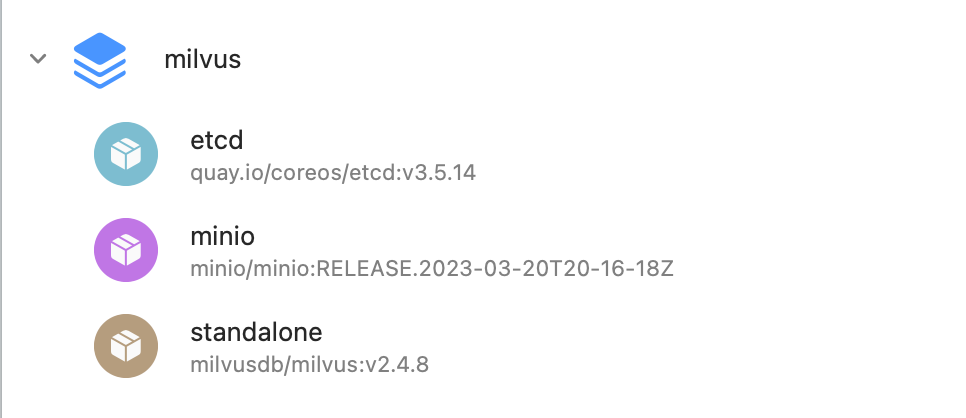
接着我们安装 attu,它的安装比较简单,下载相关平台的安装文件安装即可
attu 安装完成后打开进行 Milvus 的连接:
默认地址是 127.0.0.1:19530
接着,我们来到程序这里,进行连接和使用,同样,要先导入库
1from llama_index.vector_stores.milvus import MilvusVectorStore
然后我们调整一下之前的方法,改写一个新的方法来连接 Miluvs:
1def get_or_create_index(is_create: bool = False):
2 """
3 获取或创建索引
4 overwrite 设置为 False 意味着如果同名的集合已存在,将不会覆盖它。
5 dim 是向量维度,必须与 embedding 模型的维度一致。
6 """
7 vector_store = MilvusVectorStore(
8 uri="http://localhost:19530",
9 dim=256,
10 overwrite=False,
11 collection_name="llamaindex_collection",
12 )
13
14 if is_create:
15 storage_context = StorageContext.from_defaults(vector_store=vector_store)
16 documents = SimpleDirectoryReader("./data").load_data()
17 index = VectorStoreIndex.from_documents(
18 documents, storage_context=storage_context
19 )
20 print("已成功创建并存储新的索引。")
21 else:
22 index = VectorStoreIndex.from_vector_store(vector_store)
23
24 return index
我相信如果你阅读了前文,知道这段代码的重要点在哪里。
当 RAG 应用程序正常运行后,向量数据就被存储到了 Milvus 数据库中:
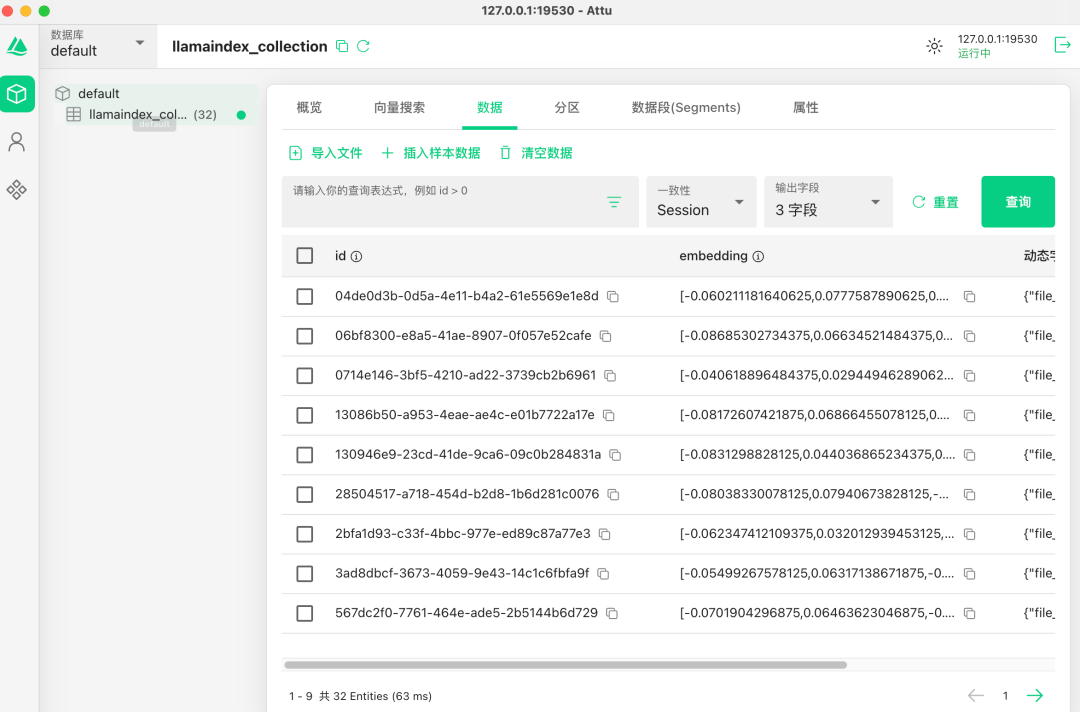
有了 GUI 界面,就比较直观地能感受到向量数据是个什么样子了。
有关在 attu 中进行向量数据的查询等操作可以参数相关文档,本文就不多说了。
使用向量数据库存储以后,我们再次运行查询,速度就很快了,因为第一次运行的时候就已经把文档 embedding 后的向量存储起来了,只需要从 Milvus 中加载查询就可以了,不用再走 http 远程调用。

总结
在本文中,我们深入探讨了如何通过 LlamaIndex 整合智谱 AI 的 GLM-4 和 Embedding-3 模型来构建 RAG 应用,并针对 Embedding-3 模型同步调用导致的性能瓶颈问题,提出了有效的解决方案。我们发现,将文档的向量存储起来,可以显著提高检索速度,避免了重复的 HTTP 同步请求,从而节省了成本和时间。
通过本地文件存储和向量数据库的选型,我们对比了多种向量数据库的特点和性能,最终选择了 Milvus 作为我们的向量数据库。Milvus 以其卓越的性能和易用性脱颖而出,特别是其数据库管理客户端 attu,为初学者提供了友好的图形界面,使得向量数据库的管理和操作变得更加直观和便捷。
在实际应用中,我们通过 Docker-Compose 安装了 Milvus,并利用 attu 进行了连接和操作。通过将向量数据存储到 Milvus 数据库中,我们显著提高了查询速度,因为文档的向量在第一次运行时就已经被存储起来,后续的查询可以直接从 Milvus 中加载,无需再次进行远程 HTTP 调用。
此外,我们还探讨了使用 Chroma 作为向量数据库的方案,它内置了 SQLite,简化了安装和使用过程。通过 LlamaIndex 的 API,我们可以轻松地将向量存储到本地文件或 Chroma 数据库中,进一步增强了 RAG 应用的性能和可扩展性。
总的来说,通过本文的探讨和实践,我们不仅解决了 RAG 应用中的性能问题,还为中大型项目提供了一种高效、可扩展的向量数据存储和管理方案。随着 AI 技术的不断发展,向量数据库在 AIGC 应用架构中的作用将越来越重要,而 Milvus 等向量数据库的选择和应用,将为构建更加智能和高效的 AI 应用提供强有力的支持。
本文所涉及的完整代码在该项目中:https://github.com/xiaobox/llamaindex_test 大家可按需自取