引言
本文我将对 2025 年上半年在技术社区引发大量讨论与转引的一篇名为 《The Second Half》(AI 的下半场)著名博客进行介绍、翻译与分析,希望通过我的介绍和分析能够让各位伙伴对 AI 领域在宏观叙事上有个清晰的了解。以便在今后的学习和研究中有更好的定位和方向。
作者简介
概览
姚顺雨(Shunyu Yao)
姚顺雨是近年“语言智能体(Language Agents)”方向的代表性研究者之一,因提出 ReAct、参与 Tree of Thoughts (ToT)、WebShop、SWE-bench / SWE-agent、τ-bench 等工作受到学界与产业关注;在 2025 年以《The Second Half》一文提出“AI 的下半场应从‘解决问题’转向‘定义问题’,评估将比训练更重要”的观点。其个人主页长期自述为“研究智能体的 OpenAI 研究员”。
教育与经历
●中学阶段获 NOI 信息学银牌、安徽省理科高考第 3 名
●本科:清华大学 交叉信息研究院“姚班”(学生时期就读于姚班,多场高校活动与官方简介均有明确表述)。在校期间担任“姚班学生联合会主席”、清华说唱社联合创始人。
●博士:普林斯顿大学计算机系(导师 Karthik Narasimhan)。博士阶段获普林斯顿研究生院 Harold W. Dodds Fellowship;其博士论文主题为 Language Agents: From Next-Token Prediction to Digital Automation。
●实习/合作经历(学生时期):多场讲座与高校活动页称其曾在 Google、Microsoft、MIT 等从事研究与合作。
代表性研究与贡献
●ReAct(Reason + Act):提出让大模型在“推理轨迹”与“动作”之间交替,从而一边思考一边使用工具/检索/交互,ICLR 2023。此范式被广泛用作后续智能体系统的基础能力模块。arXiv
●Tree of Thoughts(ToT):将“多路径思维”引入复杂问题求解的推理过程中,NeurIPS 2023。NeurIPS Proceedings
●WebShop:一个规模化网页购物交互环境(NeurIPS 2022),推动语言智能体在真实网页环境中的训练与评估。NeurIPS Papers
●SWE-bench(ICLR 2024 Oral)/ SWE-agent(NeurIPS 2024):以前者把“修真实 GitHub issue”作为评测单位,后者设计“Agent-Computer Interface”让代理能像人一样使用电脑完成工程任务,推动贴近实际的软件工程评测与系统化落地。OpenReview NeurIPS Proceedings
●τ-bench(ICLR 2025):强调在真实领域的规则与用户交互下评测语言智能体(工具-代理-用户三方互动),契合其“评估更重要”的研究取向。OpenReview
近期动态(2025 年 9 月)
●已从 OpenAI 离职:彭博社报道称 OpenAI 已确认其离职,但未说明去向。
●去向传闻与澄清:有媒体称其被 腾讯聘用;与此同时,腾讯方面辟谣了“上亿年薪”等细节,并未明确确认其入职与否。因此目前去向仍存不确定性。
原文和翻译
原文
https://ysymyth.github.io/The-Second-Half/
翻译
AI 的下半场
一句话总结:我们正处于人工智能(AI)的中场休息时间。
几十年来,人工智能的发展主要围绕着开发新的训练方法和模型。这一策略卓有成效:从在国际象棋和围棋上击败世界冠军,到在 SAT(学术能力评估测试)和律师资格考试中超越大多数人类,再到斩获国际数学奥林匹克(IMO)和国际信息学奥林匹克(IOI)金牌。在这些载入史册的里程碑——深蓝(DeepBlue)、AlphaGo、GPT-4 及 o 系统模型——背后,是 AI 方法论的根本性创新:搜索、深度强化学习(deep RL)、规模化(scaling)和推理(reasoning)。一切都在随着时间不断进步。
那么,现在究竟有何不同?
简而言之:强化学习(RL)终于奏效了。更准确地说:强化学习终于具备了泛化能力。在经历了数次重要的弯路并累积了一系列里程碑之后,我们终于找到了一个行之有效的“秘方”,能够利用语言和推理解决广泛的强化学习任务。哪怕在一年前,如果你告诉大多数 AI 研究者,同一个“秘方”能够应对软件工程、创意写作、IMO 级别的数学、键鼠操作以及长篇问答等任务,他们可能会觉得你在痴人说梦。这些任务中的任何一个都极其困难,许多研究者穷尽整个博士生涯也只能专注于其中一个狭窄的领域。
然而,这一切确实发生了
那么,接下来会发生什么?AI 的下半场——从现在开始——将把焦点从解决问题转向定义问题。在这个新时代,评估(evaluation)将比训练更加重要。我们将不再仅仅追问“我们能否训练一个模型来解决 X 问题?”,而是要问“我们究竟应该训练 AI 去做什么,以及如何衡量真正的进展?” 要在下半场脱颖而出,我们需要及时转变思维模式和技能组合,或许要更像一名产品经理。
上半场
要理解上半场,只需看看它的赢家。你认为迄今为止最具影响力的 AI 论文是哪些?
我在斯坦福大学的 224N 课程上做过这个小调查,答案不出所料:Transformer、AlexNet、GPT-3 等等。这些论文有何共同之处?它们都提出了某些根本性的突破,用以训练出更好的模型。同时,它们也通过在某些基准测试(benchmarks)上展示出(显著的)性能提升而成功发表。
然而,这背后还有一个潜在的共性:这些“赢家”都是训练方法或模型,而非基准测试或任务。即便是被认为最具影响力的基准测试 ImageNet,其引用量也不及 AlexNet 的三分之一。方法与基准测试之间的这种反差在其他领域更为悬殊——例如,Transformer 模型主要使用的基准是 WMT'14,其相关研讨会报告的引用量约为 1,300 次,而 Transformer 论文的引用量已超过 160,000 次。
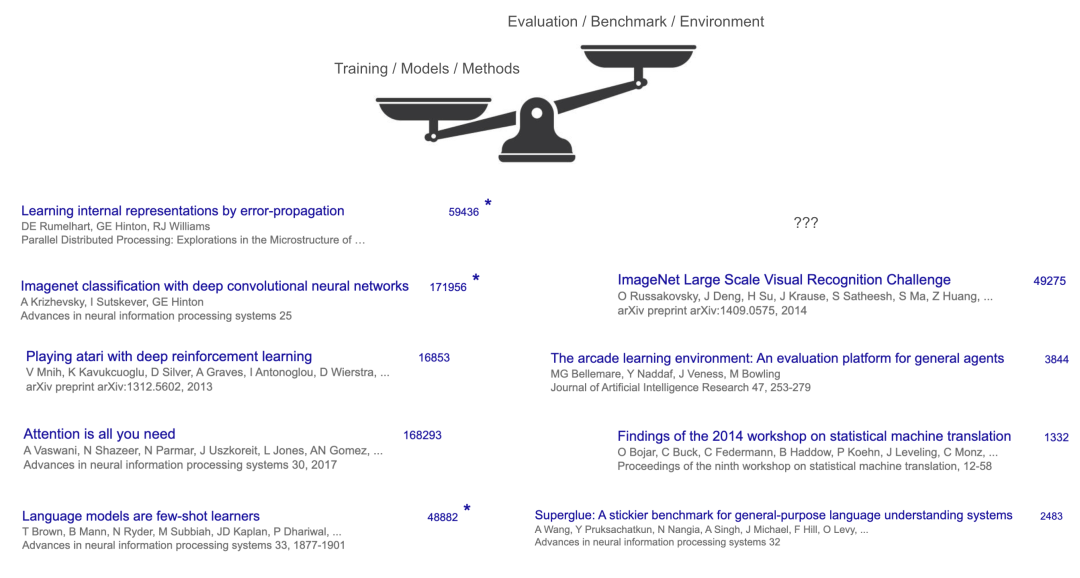
这揭示了上半场的游戏规则:专注于构建新的模型和方法,而评估和基准测试则处于次要地位(尽管它们对于维持论文发表体系的运转是必需的)。
为什么会这样?一个重要原因是,在 AI 的上半场,方法比任务更困难,也更激动人心。从零开始创造一种新算法或模型架构——例如反向传播算法、卷积网络(AlexNet)或 GPT-3 中使用的 Transformer——需要非凡的洞察力和工程能力。相比之下,为 AI 定义任务则往往显得更为直接:我们只是将人类已有的任务(如翻译、图像识别或国际象棋)转化为基准测试。这其中并不需要太多的洞察力,甚至工程量也不大。
此外,方法通常比单个任务更具通用性和广泛适用性,这使其价值尤为突出。例如,Transformer 架构最终推动了计算机视觉(CV)、自然语言处理(NLP)、强化学习(RL)等多个领域的进步,其影响远远超出了最初证明其有效性的那个单一数据集(WMT'14 翻译任务)。一个优秀的新方法之所以能够提升多个不同基准测试的性能,正是因为它既简单又通用,其影响力因此超越了单个任务的范畴。
这场游戏持续了几十年,催生了改变世界的思想和突破,其成果体现在各个领域基准测试性能的不断提升上。那么,为何游戏规则会发生改变?因为这些思想和突破的积累,最终在创造一个解决任务的有效“秘方”上引发了质变。
那个秘方
这个“秘方”是什么?不出所料,其配方包括:大规模语言预训练、规模化(数据和算力),以及推理与行动(reasoning and acting) 的理念。这些词听起来可能像是你在旧金山每天都能听到的流行语,但为何称之为“秘方”?
我们可以通过强化学习(RL) 的视角来理解这一点。RL 常被视为 AI 的“终局之战”——毕竟,从理论上讲,RL 保证能赢得游戏;从经验上看,也很难想象任何超人系统(如 AlphaGo)的诞生能脱离 RL。
在 RL 中,有三个关键组成部分:算法(algorithm)、环境(environment)和先验知识(priors)。长期以来,RL 研究者主要关注算法——即智能体学习方式的智力核心(例如 REINFORCE、DQN、TD-learning、Actor-Critic、PPO、TRPO 等)——而将环境和先验知识视为固定或次要的。例如,Sutton 和 Barto 的经典教科书通篇都在讲算法,几乎没有涉及环境或先验知识。
然而,在深度强化学习时代,环境在经验层面上的重要性变得显而易见:一个算法的性能往往高度依赖于其开发和测试所处的特定环境。如果忽略环境,你可能会构建出一个只在“玩具”环境中表现优异的“最优”算法。那么,我们为何不先弄清楚我们真正想解决的环境是什么,然后再寻找最适合该环境的算法呢?
这正是 OpenAI 最初的计划。它创建了 Gym,一个包含各种游戏的标准 RL 环境,随后又启动了 World of Bits 和 Universe 项目,试图将整个互联网或计算机变成一个游戏。这个计划听起来不错,不是吗?一旦我们将所有数字世界都转化为一个环境,再用聪明的 RL 算法去解决它,我们就拥有了数字化的通用人工智能(AGI)。
计划虽好,但并非完全奏效。OpenAI 在这条道路上取得了巨大进展,利用 RL 解决了 Dota 游戏、机械手控制等问题。但它从未接近解决计算机通用操作或网页浏览的难题,并且在一个领域有效的 RL 智能体也无法迁移到另一个领域。有些东西缺失了。
直到 GPT-2 或 GPT-3 出现之后,我们才发现,那块缺失的拼图是先验知识。你需要强大的语言预训练来将通用的常识和语言知识“蒸馏”到模型中,这些模型随后可以被微调,成为网络(WebGPT)或聊天(ChatGPT)智能体(并改变世界)。事实证明,RL 最重要的部分,或许既不是 RL 算法,也不是环境,而是先验知识——而这些先验知识的获取方式可以与 RL 毫无关系。
语言预训练为聊天任务创造了良好的先验知识,但对于控制计算机或玩视频游戏,效果却不尽相同。为什么?因为这些领域与互联网文本的分布相去甚远,简单地在这些领域上进行监督微调(SFT)或强化学习,其泛化能力很差。我在 2019 年就注意到了这个问题,当时 GPT-2 刚发布,我基于它进行 SFT/RL 来解决文字冒险游戏——由此诞生的 CALM 是世界上第一个基于预训练语言模型构建的智能体。但这个智能体需要数百万步的 RL 训练才能在一个游戏中取得进展,而且无法迁移到新的游戏。尽管这完全符合 RL 的特性,对 RL 研究者来说也见怪不怪,但我却觉得很奇怪,因为我们人类可以轻松地玩一个新游戏,并且在零样本(zero-shot)的情况下表现得好得多。然后,我迎来了人生中最早的“顿悟时刻”之一——我们之所以能够泛化,是因为我们可以选择做的不仅仅是“走向 2 号柜子”、“用 1 号钥匙打开 3 号宝箱”或“用剑杀死地牢里的怪物”,我们还可以选择去思考,比如:“地牢很危险,我需要一把武器来战斗。这里没有现成的武器,也许我需要在锁着的箱子或宝箱里找找看。3 号宝箱在 2 号柜子里,我先去那里把它打开。”
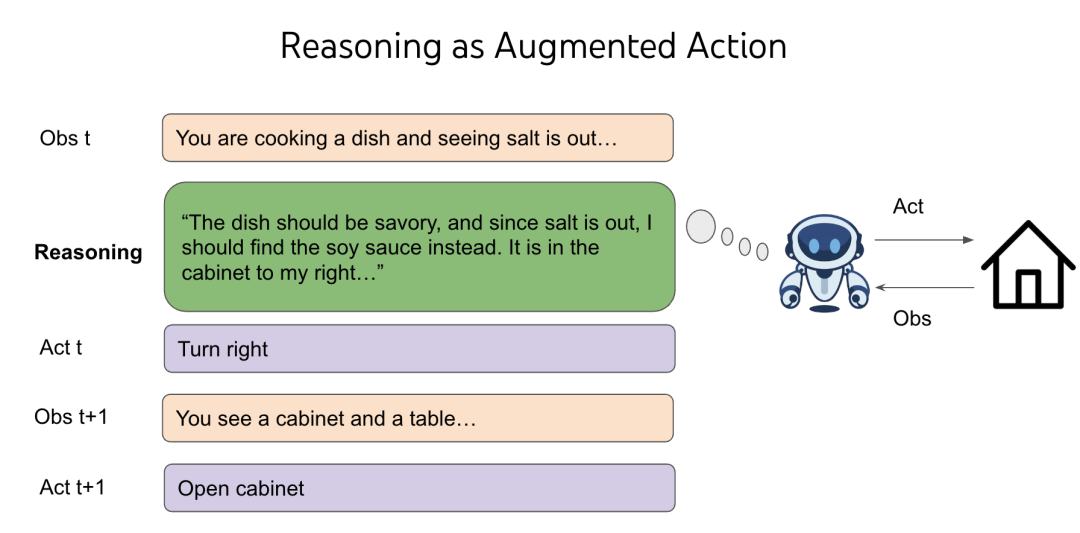
思考,或者说推理(reasoning),是一种奇特的行动——它不直接影响外部世界,但推理的空间却是开放式的、组合爆炸式的无限——你可以思考一个词、一个句子、一整段话,甚至是 10000 个随机的英文单词,而你周围的世界并不会立即发生改变。在经典的 RL 理论中,这简直是一场灾难,会让决策变得不可能。想象一下,你需要在两个盒子中选择一个,其中一个装有 100 万美元,另一个是空的。你的期望收益是 50 万美元。现在,想象我加入了无限个空盒子。你的期望收益就变成了零。但是,通过将推理加入任何 RL 环境的行动空间,我们利用了语言预训练的先验知识来实现泛化,并且能够在测试时为不同的决策灵活分配计算资源。这是一件非常神奇的事情,很抱歉我在这里没能完全解释清楚,或许我需要再写一篇博客来专门阐述。欢迎阅读 ReAct 论文来了解关于智能体推理的最初构想,并感受我当时的一些想法。目前,我的直观解释是:尽管你加入了无限个空盒子,但你在过往的各种游戏中已经见过它们无数次,选择这些空盒子的经验能让你在任何给定的游戏中更好地选中有钱的那个盒子。 我的抽象解释则是:语言通过智能体中的推理来实现泛化。
一旦我们拥有了正确的 RL 先验知识(语言预训练)和 RL 环境(将语言推理作为行动加入),事实证明 RL 算法本身反而是最微不足道的部分。于是,我们看到了 o-系列、R1、Deep Research 的计算机操作智能体,以及未来更多类似的模型。这是多么具有讽刺意味的转折!长期以来,RL 研究者对算法的关心远超环境,更没有人关注过先验知识——所有的 RL 实验基本上都是从零开始。但我们花了几十年的弯路才意识到,也许我们优先级的排序本应完全颠倒。
但正如史蒂夫·乔布斯所说:你无法预见未来的点滴如何串联,只有在回顾过去时,才能将它们连接起来。
下半场
这个“秘方”正在彻底改变游戏规则。回顾一下上半场的游戏:
●我们开发新颖的训练方法或模型来提升基准测试的性能。
●我们创造更难的基准测试,然后继续这个循环。
这场游戏正在被打破,因为:
●这个“秘方”已经将提升基准测试性能的过程标准化和工业化了,不再需要太多新的思想。 随着这个“秘方”的规模化和泛化能力越来越强,你为某个特定任务设计的新方法可能只能带来 5% 的提升,而下一个 o-系列模型即便没有专门针对这个任务,也能带来 30% 的提升。
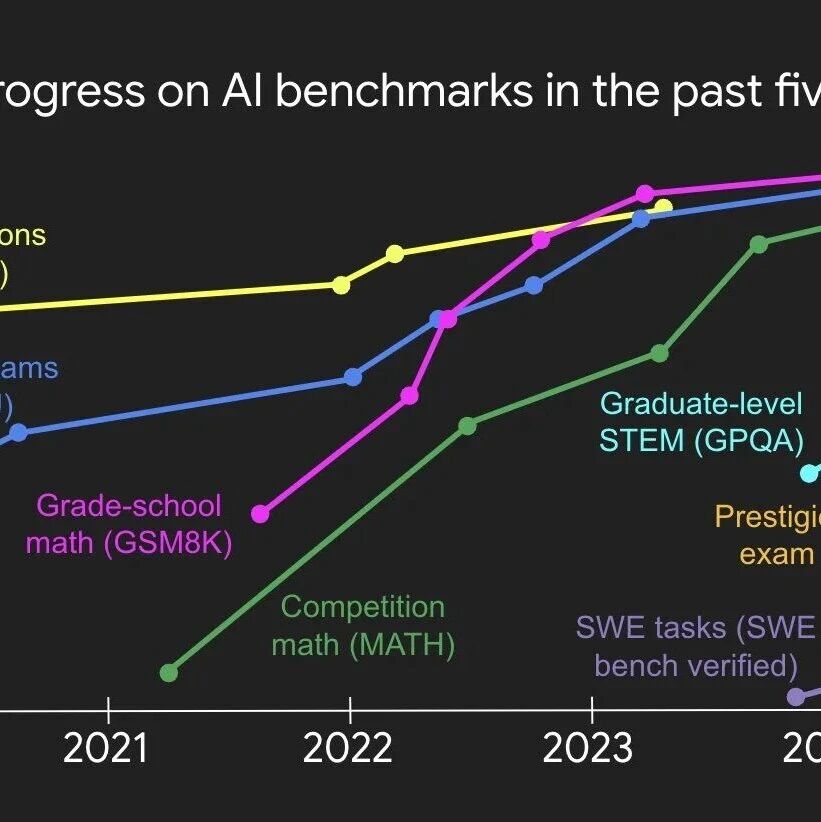
●即使我们创造出更难的基准测试,它们也很快(而且越来越快地)被这个“秘方”所解决。我的同事 Jason Wei 制作了一张精美的图表,很好地展示了这一趋势。
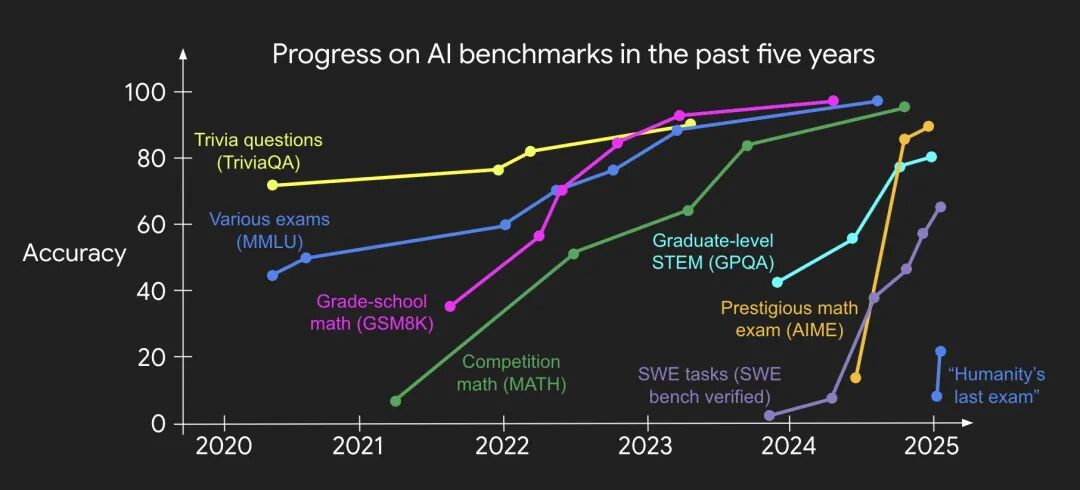
那么,下半场还剩下什么可玩的?如果不再需要新颖的方法,而更难的基准测试也只会被越来越快地解决,我们该做什么?
我认为,我们应该从根本上重新思考评估。这不仅仅意味着创造更新、更难的基准测试,而是要从根本上质疑现有的评估设定,并创造新的设定,从而迫使我们去发明超越现有“秘方”的新方法。这很困难,因为人类有惯性,很少会去质疑基本的假设——你只是想当然地接受它们,而没有意识到它们是假设,而非定律。
为了解释这种惯性,假设你发明了历史上最成功的评估方法之一,它基于人类的考试。这在 2021 年是一个极其大胆的想法,但 3 年后,这个方向已经饱和了。你会怎么做?很可能你会去创造一个更难的考试。或者,假设你解决了简单的编程任务。你会怎么做?很可能你会去找更难的编程任务,直到达到 IOI 金牌的水平。
惯性是人之常情,但问题在于:AI 已经在国际象棋和围棋上击败了世界冠军,在 SAT 和律师资格考试中超越了大多数人类,并在 IOI 和 IMO 中达到了金牌水平。但世界并没有因此发生太大改变,至少从经济和 GDP 的角度来看是这样。
我称之为效用问题(utility problem),并认为这是 AI 领域最重要的问题。
或许我们很快就能解决这个效用问题,或许不能。但无论如何,这个问题的根源可能简单得令人迷惑:我们的评估设定在很多基本方面都与真实世界的设定不同。举两个例子:
1.评估“应该”是自动运行的,所以通常一个智能体接收一个任务输入,自主完成任务,然后获得一个任务奖励。但在现实中,智能体在整个任务过程中必须与人类互动——你不会只给客服发一条超长的信息,然后等 10 分钟,就指望收到一个详尽的回复解决所有问题。通过质疑这种设定,新的基准测试被发明出来,它们要么将真实人类纳入评估环路(如 Chatbot Arena),要么使用用户模拟(如 tau-bench)。

2.评估“应该”是独立同分布(i.i.d.)的。如果你有一个包含 500 个任务的测试集,你会独立地运行每个任务,然后对任务指标取平均,得到一个总指标。但在现实中,你是按顺序解决任务,而非并行。一位谷歌的软件工程师随着对代码库越来越熟悉,解决问题的效率会越来越高,但一个软件工程师智能体在同一个代码库中解决多个问题时,却无法获得这种熟悉度。我们显然需要长时记忆的方法(这类方法也确实存在),但学术界没有合适的基准测试来证明这种需求的必要性,甚至没有足够的勇气去质疑作为机器学习基础的 i.i.d. 假设。
这些假设“一直”以来就是如此,在 AI 的上半场,基于这些假设来开发基准测试并没有问题,因为当智能水平较低时,提升智能通常也能提升效用。但现在,通用的“秘方”在这些假设下几乎是万能的。因此,下半场的新游戏规则是:
●我们开发新颖的、旨在提升现实世界效用的评估设定或任务。
●我们用现有的“秘方”来解决它们,或者通过增加新的组件来增强“秘方”。然后继续这个循环。
这场游戏很困难,因为它很陌生。但它也令人兴奋。上半场的玩家解决的是视频游戏和考试,而下半场的玩家则有机会通过将智能转化为有用的产品,来创建价值数十亿甚至数万亿美元的公司。上半场充满了渐进式的方法和模型,而下半场在某种程度上会过滤掉它们。通用的“秘方”会轻易碾压你的渐进式方法,除非你创造出能打破这个“秘方”的新假设。那时,你才能做出真正改变游戏规则的研究。
欢迎来到下半场!
深度解析
《The Second Half》 提示了我们所处的人工智能时代的一个根本性的范式转移
对“上半场”的深刻反思
上半场的游戏哲学:“更好”等于“更高分”
上半场的竞争逻辑是极其纯粹且清晰的:通过创造更优秀的模型和算法,在公认的、标准化的基准测试(Benchmark)上取得更高的分数。 无论是计算机视觉领域的 ImageNet 挑战赛,还是自然语言处理领域的 GLUE、SuperGLUE 排行榜,整个学术界和工业界都被卷入了一场围绕“SOTA”(State-of-the-Art)的军备竞赛。
这种模式的底层信仰是:智能本身是线性可扩展的,只要模型在基准测试上的表现越好,它在真实世界中的应用潜力就越大。 这在很长一段时间内是正确的。AlexNet 在 ImageNet 上的胜利,直接催生了计算机视觉的黄金十年;Transformer 架构的提出,则奠定了整个大语言模型时代的基础。我们专注于“造锤子”,因为市场上有无数显而易见的“钉子”等着我们去敲。
成功的“惯性”与“范式之疲”的显现
然而,当一个范式取得巨大成功后,它会产生巨大的惯性,这种惯性会掩盖其底层逻辑的悄然变化。我们正面临着“上半场范式”的系统性疲劳,其症状体现在三个方面:
●症状一:能力的商品化与竞争的同质化。“通用秘方”(大规模预训练 + 规模化 + 推理/行动)的出现,是一个颠覆性的事件。它意味着,世界顶级的感知、生成和基础推理能力,正在迅速地从少数巨头的“独门秘籍”变为一种类似水和电的、可按需取用的“基础设施”。无论是通过 API 调用 OpenAI 的模型,还是利用强大的开源模型(如 Llama 系列),任何一个具备基本工程能力的公司,都能站在巨人的肩膀上。这直接导致,单纯依靠基础模型能力本身来构建的护城河,其水位正在以肉眼可见的速度下降。我们正进入一个“后模型时代”,竞争的焦点必然从模型本身转移到更高维度的层面。
●症状二:“效用问题”(The Utility Problem)的尖锐化。这是《The Second Half》一文最核心、也最深刻的洞察。我们看到无数令人惊叹的 Demo:AI 在 SAT、律师资格考试、甚至奥数竞赛中击败人类。但当我们把目光投向宏观经济指标,如劳动生产率的增长,却发现其影响远未达到预期的“奇点”时刻。在企业内部,我们同样能感受到这种“演示与部署之间的鸿沟” 。一个能在测试集上达到 95% 准确率的模型,部署到真实、混乱的业务流程中时,其表现可能会断崖式下跌。这种“高分低能”的现象,深刻地揭示了我们上半场评估体系的根本性缺陷:它奖励的是在无菌实验室里解决抽象问题的能力,而非在真实世界中创造可靠价值的能力。
●症状三:边际成本的急剧攀升与创新动力的衰减。追逐 SOTA 的游戏,其成本正在变得越来越昂贵。将一个模型的性能从 90% 提升到 91%,可能需要消耗双倍的算力和数据。这种投入产出比的急剧下降,使得除了少数资源雄厚的玩家外,大多数公司都无法也不应参与这场“军备竞赛”。更危险的是,对“刷分”的过度关注,可能会扼杀掉那些无法立即在现有基准上体现价值、但却可能开辟全新路径的颠覆性创新。
下半场的本质:在不确定性世界中定义价值
下半场的核心特征是“发散” 。
●问题的本质是不确定的:我们不再有一个清晰的数学目标,而是要解决一个模糊的商业/用户问题。例如,“提升用户对我们产品的满意度”、“降低新员工的培训成本”。这些问题无法用一个简单的分数来衡量。
●环境是动态和复杂的:真实世界是连续的、充满互动的、非结构化的。用户有记忆,任务之间相互关联,一个错误的决策会带来长期的负面影响。
●成功的关键是“定义问题和评价体系”:当所有玩家都用上了相似的“万能锤子”(强大的基础模型),胜负手就不再是锤子本身,而是“你知道应该在哪堵墙上凿个洞,以及你知道怎么才算凿好了” 。
○在哪凿洞? —— 定义问题(Problem Definition)。这需要深入理解业务场景、用户痛点。
○怎么算凿好了? —— 构建评估(Evaluation Design)。这是下半场的核心竞争力。如何设计一套能够真实反映“用户价值”的评估体系,决定了你的 AI 能否在正确的方向上迭代。
构建“下半场”的胜利引擎
如果说上半场的核心产物是“模型”,那么下半场的核心产物则必然是“系统”——一个能够将通用智能与我们独特的业务场景、数据、流程深度融合的智能体(Agent)系统 。我想详细阐述这个系统的架构哲学,它远比“LLM+Prompt”复杂,也坚固得多。
认知核心
这是 Agent 的 “大脑”,通常由一个或多个 LLM/VLM 构成。我们的战略不应是重复造轮子,而是构建一个可插拔、可路由的模型层,能根据任务的成本和复杂度,智能地选择最优模型。它至少要包括以下两部分:
1.模型抽象与路由层:这是架构的基石。我们需要一个统一的接口,能够屏蔽掉不同模型(OpenAI, Anthropic, Google, 开源模型, 自研小模型)的差异。能够根据任务的复杂度、延迟要求、成本预算、安全等级,动态地将请求分发给最合适的模型。例如,一次简单的情感分类任务应该由一个本地化的、低成本的小模型处理;而一次需要复杂多步规划的请求,则路由到最强大的大模型。
2.提示工程平台化(PromptOps):Prompt 是我们与 AI 交流的语言,它不应是散落在代码各处的“魔法字符串”。我们需要一个企业级的 PromptOps 平台,对 Prompt 进行版本化管理、A/B 测试、自动化评估和持续优化。这个平台将是我们沉淀“人机交互知识”的核心资产。
记忆系统
一个没有记忆的 Agent,永远只是一个强大的、但健忘的工具。记忆系统是 Agent 实现个性化、持续进化的关键,也是构建数据飞轮的核心。
●短期工作记忆(Working Memory):这是 Agent 处理当前任务的“内存”。它需要高效地管理对话历史、任务中间状态、工具调用结果等。挑战在于如何在保持长上下文的同时,有效控制成本和延迟。
●长期情景记忆(Long-Term Episodic Memory):这是 Agent 的“人生经历”。每一次成功的交互、每一次失败的尝试、每一个用户的特定偏好,都应该被向量化,并存入一个可供检索的长期记忆库。当 Agent 遇到新任务时,它能“回忆”起过去处理类似情况的经验,从而做出更优的决策。
●长期语义/程序记忆(Long-Term Semantic/Procedural Memory):这是 Agent 的“知识库”和“技能库”。前者存储了我们公司独有的领域知识(如产品文档、行业报告),后者则存储了完成特定任务的标准化流程(SOPs)。这确保了 Agent 的行为不仅是智能的,更是专业和合规的。
工具箱
Agent 的价值最终体现在行动上。工具系统是 Agent 影响物理世界和数字世界的桥梁,其设计的优劣直接决定了 Agent 的能力边界。
同时 tools 也是 Agent 的‘手脚’。我们可以将公司内外部的各种能力无论是调用一个 API、查询数据库、还是执行一个 RPA 脚本都封装成标准化的‘工具’,供 Agent 调用。我们工具箱的丰富性和可靠性,直接决定了我们 Agent 能力的天花板。但这里有几个关键的问题需要关注:
●工具注册与治理:工具如何封装,如何注册,最后如何有效的进行治理 ?
●执行与编排:当 Agent 决定调用工具时,谁来负责安全、可靠地执行,并处理各种现实世界的异常(如 API 超时、数据格式错误、权限不足)?
●安全与审计:如何进行身份验证、权限检查与意图审计 ?
认知能力的深化
在我们构建了认知核心、记忆系统和工具系统之后,一个基础的 Agent 已经可以运转。它能够“看到”(感知)、“记住”(记忆)、并“行动”(工具)。然而,要让 Agent 真正能够胜任企业级的复杂、长周期任务,我们必须直面当前主流 Agent 框架(如 ReAct 模式)的固有限制。
ReAct 模式本质上是一种反应式(Reactive) 的、一步一思考的决策循环。它在处理定义清晰、步骤明确的短任务时表现出色,但在面对一个模糊、宏大、且充满不确定性的长期目标时,往往会陷入局部最优,甚至迷失方向。例如,对于“将本季度用户流失率降低 5%”这样一个战略性目标,简单的“思考-行动”循环是完全不够的。
因此,为了让 Agent 系统具备处理战略级任务的能力,我们需要在认知核心之上,构建一个更为高级的能力层,专注于前瞻性规划(Proactive Planning)和系统性自我校正(Systematic Self-Correction)。这并非一个独立的引擎,而是对现有认知能力的深化与扩展。
从任务执行到任务分解
一个高级 Agent 必须具备将一个高层、模糊的战略意图,分解为一系列具体的、可管理的、有逻辑依赖关系的子任务的能力。这要求我们的系统:
●具备多层次规划能力:对于“为新产品制定一个为期三个月的上市营销计划”这样的任务,Agent 需要能够生成一个结构化的任务树或有向无环图(DAG)。顶层是战略目标,下面分解为市场分析、内容制作、渠道投放、数据监控等多个阶段性任务,每个阶段任务再进一步分解为具体的执行动作,如“调用 API 查询竞品关键词”、“调用内部 CRM 生成潜在客户列表”等。
●能够进行资源与依赖管理:规划出的任务流,必须考虑现实世界的约束,如预算限制、时间窗口、以及任务之间的前后置依赖关系。这使得 Agent 的规划更接近于一个真正的项目管理专家,而不仅仅是一个指令执行器。目前,如 Tree-of-Thought (ToT) 等研究已经展示了探索多路径规划的可行性,而将其工程化、并与企业实际流程相结合,将是我们重要的研发方向。
从执行失败到归因学习
在复杂的真实世界中,失败是常态。一个仅仅在失败时报错的系统是脆弱的。一个鲁棒的 Agent 系统,需要具备从失败中学习和恢复的能力。这要求我们建立一个系统性的错误归因与校正机制。
1.精细化的错误归因:当一个任务失败时,系统不应简单地返回一个“Failed”状态。我们需要一个“事后复盘”模块,能够自动分析完整的执行日志(包括模型的思考链、工具的调用记录、环境的反馈),并像软件工程中的根本原因分析(RCA)一样,将失败定位到具体环节。例如:
a.规划阶段的逻辑错误?(e.g., 错误地估计了任务的依赖关系)
b.工具执行层面的技术故障?(e.g., 某个 API 超时或返回了非预期的格式)
c.环境理解阶段的认知偏差?(e.g., 错误地解析了网页上的某个信息)
d.还是基础模型的知识局限或幻觉?
2.将经验转化为可复用的知识:在完成归因后,系统应将这次失败的案例——包括问题描述、失败路径、根本原因和(如果可能的话)正确的解决方案——进行结构化处理,并存入长期记忆库。这相当于为我们的 Agent 系统建立了一个可不断增长的“错题本”。未来在遇到类似情景时,Agent 可以检索这些经验,从而主动规避已知的陷阱。
总之,将前瞻性规划与自我校正能力,深度集成到 Agent 系统中,其战略意义在于:它将 Agent 从一个被动的“任务执行者”,升级为一个具备一定自主性、能够处理复杂战略目标、并从经验中持续进化的“问题解决伙伴”。这虽然是当前 AI Agent 领域最具挑战性的前沿方向之一,但它也恰恰是构建长期、可持续技术壁垒的关键所在。
下半场的“北极星”
如果我们认同“下半场”的逻辑,那么结论是显而易见的:评估体系的设计,是未来最重要、最核心、最能构建壁垒的竞争力。
让我们用一个具体的例子来说明。假设我们用一个 AI Agent 来辅助客服。上半场的评估指标可能是“平均处理时长 ”或“首次回复准确率”。为了优化这些指标,Agent 可能会倾向于快速给出标准答案并关闭工单。表面上看,效率提升了。但真实情况可能是,用户的复杂问题并未得到根本解决,导致他不得不再次、甚至多次联系我们,最终的客户满意度和忠诚度反而下降了。这是一个典型的“指标陷阱”:我们优化了一个代理指标,却损害了最终的商业目标。
所以我们的目标应该是构建一个能够衡量真实、长期、商业价值的评估引擎。至于具体怎么做,说实话,我不知道,凭我的设想,它应该包括:
●高保真业务仿真环境:为我们的核心业务流程,构建一个“数字孪生” 。在这个环境中,我们可以模拟数百万次的用户交互、各种罕见的边缘案例、甚至是恶意的攻击行为。这使得我们可以在 Agent 上线前,对其进行低成本、高效率、全方位的压力测试和迭代优化。
●人机回环竞技场:这是一个内部平台,让我们的一线业务专家成为 Agent 的“金牌教练”。他们可以在平台上,对 Agent 在真实(或模拟)任务中的表现进行打分、纠错、甚至提供更优的决策范例。这些高质量的、蕴含着人类专家隐性知识的数据,是我们将 Agent 从“可用”提升到“卓越”的最宝贵燃料。
●长期价值归因分析:与数据分析团队紧密合作,建立严谨的因果推断模型,将 Agent 的引入,与最终的业务北极星指标(如客户 LTV 的提升、运营成本的降低、用户流失率的下降)进行强关联。这使得我们能够用商业语言,清晰地证明 AI 的价值。
●引入“Agent-业务-Fit” (ABF) 的概念:或许我们应该像评估“产品-市场-Fit” (PMF) 一样,为每个 Agent 项目建立一个衡量其与业务契合度的成熟度模型。它包括了从任务成功率、操作可靠性、成本效益,到用户接受度、业务流程融合度等多个维度的综合评分。
最后
AI 的 “下半场” 已经悄然而至,这既带来了巨大的挑战,也蕴含着前所未有的机遇。它挑战的是我们过去的成功经验和思维惯性。然而下半场的 AI,其智能的源泉,也正是我们日复一日工作中积累的、那些无法被量化、但却无比宝贵的领域知识和专业智慧。