引言
原文链接:https://www.anthropic.com/engineering/writing-tools-for-agents
为什么 Anthropic 的文章很重要, 几乎是必读的?
因为 Anthropic 的工具,无论是 web、客户端的 claude 、claude code 以及其他的工具都有全世界大量的真实用户使用,他们的博客是团队分享自己在工程上遇到的真实问题和解决方案。是经得起验证、交过学费的、第一手的、宝贵的经验,值得所有 AI 领域的相关从业者学习。
传统软件开发中,我们编写的函数或 API 是确定性的:相同输入必然产出相同输出。而 AI Agent(基于大语言模型的自主智能体)具有非确定性——即使起点相同,每次响应可能不同。这意味着为 Agent 设计工具的软件接口,与传统为开发者设计 API 有本质区别。Anthropic 强调,工具是连接确定性系统与非确定性 Agent 之间的新型软件契约。当用户问“今天要带伞吗?”,Agent 可能调用天气查询工具,也可能基于常识直接回答,甚至先问用户所在地。一些情况下 Agent 会幻觉出不存在的工具或误用工具。这就要求我们重新思考软件开发方法:设计给 AI Agent 用的工具,不能仅按传统 API 方式,而要考虑 Agent 的行为特点和局限。
这篇文章的核心论点是:为非确定性(Non-deterministic)的 AI 智能体设计工具,必须摒弃传统面向确定性系统的 API 设计思维,转而采用一种以“模型-工具协同”为中心、以“上下文效率”为导向的新范式。这不仅仅是技术选型问题,更是一种方法论的转变。
工具开发的迭代流程
原型、评估与 AI 协作优化

1. 快速原型本地测试
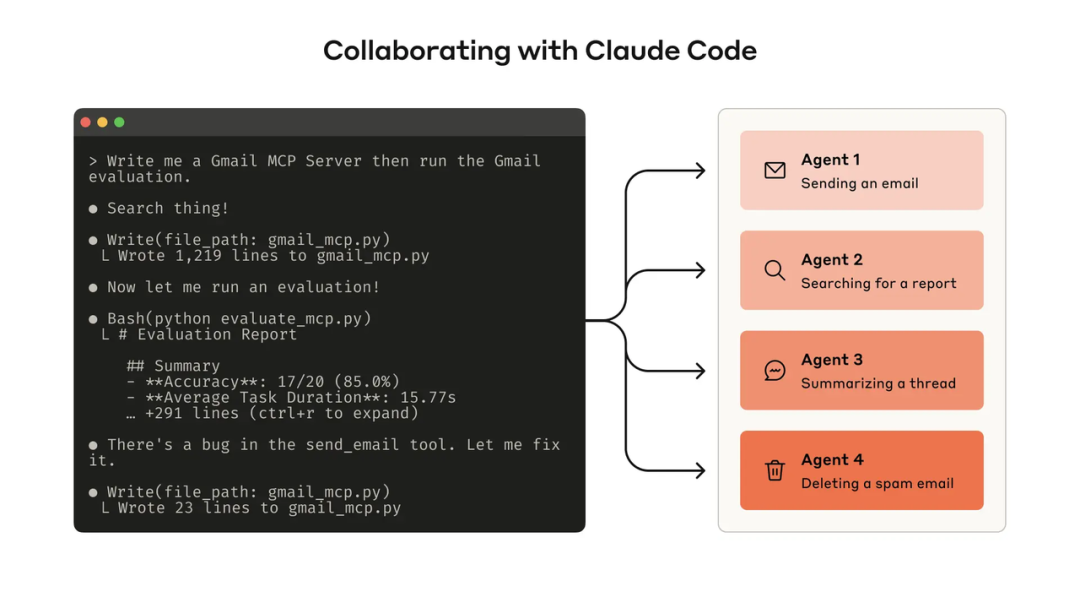
首先构建工具的原型并在本地进行测试。尽早上手试验可以发现哪些工具对 Agent 来说顺手,哪些不太“趁手”。开发者可以借助 Claude Code 这类助手来一次性生成工具代码
2. 生成大规模评估任务
在原型基础上,设计贴近真实场景的评估任务集,并利用 AI Agent 协助生成大量多样且复杂的测试用例。这些评估任务应源自实际业务流程和数据(如公司内部知识库、日志系统等),避免过于简化的“沙盒”场景。
优秀的测试任务通常需要 Agent 跨多步调用多个工具才能完成。例如:“为客户 Sarah 撰写挽留方案:找出她要退出的原因,并给出有说服力的挽留优惠,以及任何需要注意的风险因素。” 这样的任务可能涉及查询客户信息、检索历史记录、综合分析原因并生成方案,远比简单的单步查询更能考察 Agent 对工具的灵活运用。
3. 运行评估并收集指标
编写脚本程序化地跑通所有评估任务,让 Agent 在每个任务中使用工具完成要求。在系统提示中明确要求 Agent 输出结构化答案(用于核对正确性)以及思考过程和反馈,以触发模型的链式思考 (CoT) 便于分析。对每轮评估记录是否成功完成任务、用时、工具调用次数、消耗的 token 数量、错误情况等关键指标。
4. 分析结果诊断问题
把评估过程中 Agent 的推理过程和反馈当作宝贵信息,找出工具集的薄弱环节。观察哪些任务上 Agent 陷入困惑,哪些工具没被正确调用。特别要留意 Agent 输出/反馈中“没有说出”但实际存在的问题——模型有时不会直白指出所有困扰,需要开发者读懂言外之意。同时分析量化指标:例如若观察到某个工具被反复无效调用,可能说明工具描述不清或参数设计不合理;如果多次出现返回结果超长甚至截断,说明需要优化分页或过滤机制。
5. Agent 协作改进工具
充分利用 AI Agent 本身的能力来改进工具。Anthropic 建议将所有评估对话的完整记录拼接起来,交给如 Claude Code 这样的 Agent 模型,请它协助分析改进。实践证明,Claude 非常善于阅读大量交互日志,一次性提出修改方案,批量重构工具的实现和描述,使其更一致和高效。事实上,Anthropic 博客中的很多最佳实践,正是通过反复让 Claude 优化内部工具而总结出来的。每轮修改后再次运行评估,对比新旧版本在任务成功率等指标上的提升,确保改进确有效果。同时准备额外的测试集验证没有过拟合于训练任务。Anthropic 分享的实验显示:经过 Claude 自动优化后的工具,相比人类工程师初版,实现了显著性能提升,并且在隐藏测试集上也有更好表现。
高效 Agent 工具设计的五大原则
1. 审慎选择工具
质量远比数量重要!!
谨慎选择实现哪些工具(少而精):更多的工具并不一定带来更好效果。一个常见误区是把现有软件功能或 API 简单封装成大量工具接口,却不考虑这些工具是否真正适合 Agent 使用
技术原理
这一原则的背后是大语言模型(LLM)固有的两大限制:有限的上下文窗口(Context Window)和在庞大选择空间中进行决策的“认知负荷”。工具过多不仅会迅速消耗宝贵的上下文空间,还会因为“选择悖论”导致模型混淆,无法准确调用最合适的工具。
深层分析
文章提出的 “避免无效的 ‘包 API’ 式工具” 是一个关键洞见。简单的 API 封装(例如 list_users)对于模型来说是低效的,因为它需要模型在上下文中自行进行后续的过滤和处理,这是一种“上下文浪费”。
高效的工具应该具备更高的抽象层次,将一个典型工作流中的多个步骤整合起来(例如将 list_users, get_user_details, get_user_recent_activity 合并为 get_customer_context)。这种设计将计算任务从模型的“脑内”(上下文)转移到了工具的“体外”(确定性代码),极大地提升了效率和准确性。
跨领域印证
这与 Manus 团队提到的“动态动作空间管理”思想异曲同工。尽管实现方式不同(Manus 通过状态机和 logits mask 来约束可用工具),但其本质都是为了减少模型在特定时刻需要考虑的工具数量,从而降低决策难度,避免产生幻觉。
2. 清晰的命名空间
为模型建立心智模型
清晰划分工具的命名空间:当 Agent 面对几十上百个工具时,明确的命名规范有助于划定工具边界,减少混淆。Anthropic 推荐给相关工具加统一前缀(或后缀)进行分组。例如,以服务名称为前缀:asana_search、asana_create用于 Asana 相关操作;或按资源类型命名:gitlab_issue_search、gitlab_issue_update等。这种命名分组使得工具名称本身蕴含分类信息,Agent 更容易选择正确的工具。
技术原理
LLM 在理解工具时,严重依赖工具名称和描述所提供的语义信息。命名空间(如 asana_projects_search)通过创建清晰的层次结构和归属关系,帮助模型构建关于工具集的“心智模型”。这降低了工具功能的模糊性,使得模型在面对“搜索”这类泛化指令时,能更准确地定位到特定领域的工具。
深层分析
这是一种针对 LLM“注意力机制”的优化。统一的前缀或后缀就像路标,引导模型的注意力快速聚焦到相关的工具子集上。Anthropic 提到前缀和后缀的选择会对性能产生不可忽略的影响,这表明模型的内部表征对这种结构化信息非常敏感,需要通过实验评测来确定最优方案。
3. 返回有意义的上下文
信噪比是关键
工具只返回高价值的信息:设计工具的输出时,要聚焦有用的上下文,过滤掉冗余细节,避免把大量无关信息塞回给 Agent
技术原理
工具返回给模型的信息,构成了下一次决策的基础。返回充满低级技术标识符(如 UUIDs)或大量无关数据的内容,等同于向上下文中注入“噪声”。模型需要消耗额外的 Token 和推理能力去解析这些噪声,从而增加了出错的概率。
经验表明,Agent 对自然语言描述或可读标识的理解远胜过对晦涩代码或 ID 的理解。因此,尽量让工具返回语义清晰、直接有助于后续决策的内容。例如,与其返回内部用的 UUID、数据库键值,不如返回对象的名称、简要描述,必要时附带可读的短 ID。Anthropic 团队甚至发现,将纯数字型的 UUID 转换成更有语义的标识符(哪怕是简单的递增编号),都能显著减少 Claude 在检索任务中的幻觉错误。当然,在某些场景下 Agent 最终仍需要那些技术 ID 来调用下一个工具(比如搜索到用户“Jane”后,需要传递其 user_id 给消息发送工具)。对此,可以让工具提供多种格式的输出:例如增加一个 response_format 参数,允许 Agent 选择“简洁”或“详细”模式。详细模式下返回全面信息(包括 ID 等字段),简洁模式下只返回对人有用的内容。下面的代码片段展示了如何用枚举来控制工具响应的详细程度:
⚡ 代码片段enum ResponseFormat { DETAILED = "detailed", CONCISE = "concise" }
深层分析
文章强调了自然语言标识符和可读字段的重要性,这迎合了 LLM 的本质——它是一个语言模型,对自然语言的处理能力远超于对抽象符号的处理能力。此外,提供多种响应格式(如 concise vs detailed)是一种精巧的设计,它将控制权交还给了 Agent,允许其根据任务的下一步需求,动态管理上下文的粒度,实现了灵活性和效率的平衡。
4. 优化返回信息的 Token 效率
优化工具输出的 Token 效率:在确保信息有用的同时,还要关注返回内容的长度控制。Agent 每轮可用的上下文长度是有限的,过长的工具输出既可能浪费 token 成本,也会挤占后续推理空间。针对任何可能返回大量数据的工具,建议实施分页、范围查询、结果过滤或截断等机制,并设定合理的默认参数避免一次返回过多内容。
技术原理
这是前一个原则在“量”上的延伸。上下文窗口是所有 Agent 最稀缺的资源。高效的工具必须是“上下文友好”的。
深层分析
除了常见的分页、截断等方法,这篇文章的精髓在于将“上下文管理”的思维融入工具设计中。例如,一个设计良好的 search_logs 工具不仅返回匹配的日志,还会附带周边上下文,这避免了模型为获取上下文而进行的多次、无效的 read_file 调用。
跨领域印证
这一点与 Manus 文章中提出的“文件系统作为终极上下文”的观点完美契合。两者都认识到,不能将所有信息都塞入模型的直接上下文中。Manus 将文件系统视为一个可供 Agent 按需读写的、近乎无限的外部记忆体;而 Anthropic 则通过优化工具输出来减少对直接上下文的占用。本质上,都是在为有限的上下文窗口“减负”。
5. 通过提示工程提升工具说明的质量
工具描述即 API 文档
将提示工程用于工具描述:最后但同样重要的是,要精心撰写每个工具的描述和规范,把它当作提示词工程的一部分。
技术原理
对于 LLM Agent 而言,工具的描述(docstring)和参数定义就是它的“API 文档”。这份文档的清晰度、准确性和无歧义性,直接决定了模型能否正确理解和使用该工具。
深层分析
Anthropic 将此过程类比为“给新同事写文档”,这是一个非常精准的比喻。这意味着需要明确定义术语、解释参数间的关系、提供示例,并预见可能的误解。文章还揭示了一个重要的实践:利用 Agent 本身来分析评测结果并重构优化工具描述。这是一个强大的“AI 辅助 AI 开发”的闭环,通过自动化评测和迭代,持续提升工具对模型的“可读性”和“可用性”。

综合评价
从“调用”到“协同”的范式转变
整篇文章的核心思想是,开发者不应再将 Agent 视为一个被动的函数调用者,而是一个非确定性的合作伙伴。工具的设计目标是最大化这种合作的效率,降低沟通成本(即上下文消耗)和误解(即错误调用)。
上下文工程是基石
无论是 Anthropic 对工具设计的五个原则,还是 Manus 提出的七个教训,其核心都在于“上下文工程”(Context Engineering)。 如何塑造、管理和优化输入给模型的上下文,最终决定了 Agent 的行为、效率和稳定性。这包括了工具定义、历史对话、工具返回结果以及错误信息等一切输入。
评测驱动的迭代是唯一通路
文章强调了构建贴近真实场景的评测任务,并利用 Agent 自身的推理反馈来持续迭代的重要性。这是一个“快速原型 -> 协作生成评测 -> 自动化评测 -> 迭代优化”的闭环。这承认了 Agent 开发的实验科学属性,不存在一蹴而就的完美设计,只能通过系统性的评测来不断逼近最优解。
错误信息是一种宝贵的反馈信号
Anthropic 和 Manus 都强调了返回清晰、可操作的错误信息的重要性。这不仅是给开发者看的,更是给 Agent 看的。一个好的错误信息应该告诉 Agent“为什么错了”以及“如何修正”,这使得 Agent 具备了自我纠错和从失败中学习的能力,极大地增强了系统的鲁棒性。
总结
以上五条原则可概括为:意图明确、边界清晰、高效精简、反馈友好、描述完善。遵循这些原则设计的工具,往往更符合 AI Agent 的“心智模型”,让它能像人类一样直观理解如何运用工具来解题。值得一提的是,这些经验并非 Anthropic 一家的特殊发现——许多从事 Agent 研发的团队都在逐步摸索出类似的规律,并将其视为构建强大 Agent 系统的基石
Anthropic 的这篇文章提供了一套非常实用且深刻的 Agent 工具设计框架。对于任何致力于构建高性能、高可靠性 AI Agent 的研究团队来说,这五大原则以及背后贯穿的“上下文工程”和“评测驱动”思想,都应成为核心的设计准则。