
引言
当前,智能 Agent 的开发正面临两条截然不同的路径选择。一方面,高代码方式通过 SDK 和 API 编码提供灵活性,但带来了巨大的复杂性负担——开发者需要深入理解模型集成、工具调用、记忆管理和分布式协调等复杂概念,显著提高了开发门槛和维护成本。另一方面,像百炼,Dify、Coze 为代表的低代码平台以其出色的易用性迅速占领市场,通过可视化界面让用户能够快速构建 “Model+Prompt+MCP+RAG+Memory” 的标准 Agent 模式。
高代码与低代码
高代码
优势
●控制粒度高:检索、重排、记忆淘汰策略、工具容错、并发/一致性都能精细掌控。
●可移植/可替换:模型、向量库、存储、消息队列可按需换,避免深度锁定。
●性能上限高:可针对热路径做缓存/批量化/并行/算力亲和等优化。
●合规友好:易于纯内网/私有化落地,满足数据边界与审计需求。
劣势
●上手成本高:需要理解模型行为、工具协议、状态管理、分布式、测试/评测。
●开发周期长:原型到生产的路径更长,对团队工程能力要求高。
●维护复杂:提示/数据/评测/日志/灰度与回滚都要自己做治理。
适用场景
●对稳定性、性能、合规要求高的核心业务流程(客服、风控、运维、知识中枢)。
●强定制:复杂工具链(多后端系统、定制检索策略、多段对话状态机)。
●内网/私有化:外网受限、需与既有基建深度耦合(监控、鉴权、审计)。
低代码
优势
●速度快:原型与迭代极快,业务同学也能参与搭建与验收。
●门槛低:抽象好了调用、编排、上下文缓存、简单评测与发布。
●运维成本低:平台内置监控/日志/版本管理(能力视平台而定)。
劣势
●可扩展性受限:复杂状态机、精细化检索/重排、跨域事务一致性等较难。
●性能上限有限:难做深度批处理、算力亲和、跨服务并行等工程优化。
●供应商/能力锁定:某些特性依赖平台实现,迁移成本较高。
●私有化差异:部分平台更偏 SaaS;若需纯内网,要筛选支持私有化/离线模型的方案。
适用场景
●探索/验证期:快速做 PoC、AB 实验、用户调研与演示。
●中轻量业务:知识问答、表单处理、运营活动、内部助理等非关键路径。
●混合团队:产品/运营可直接改提示与流程,工程只需提供数据/工具接口。
场景选型
高代码和低代码有各自的特点和适用场景,那我们该如何决策呢?下面是一个快速决策矩阵:
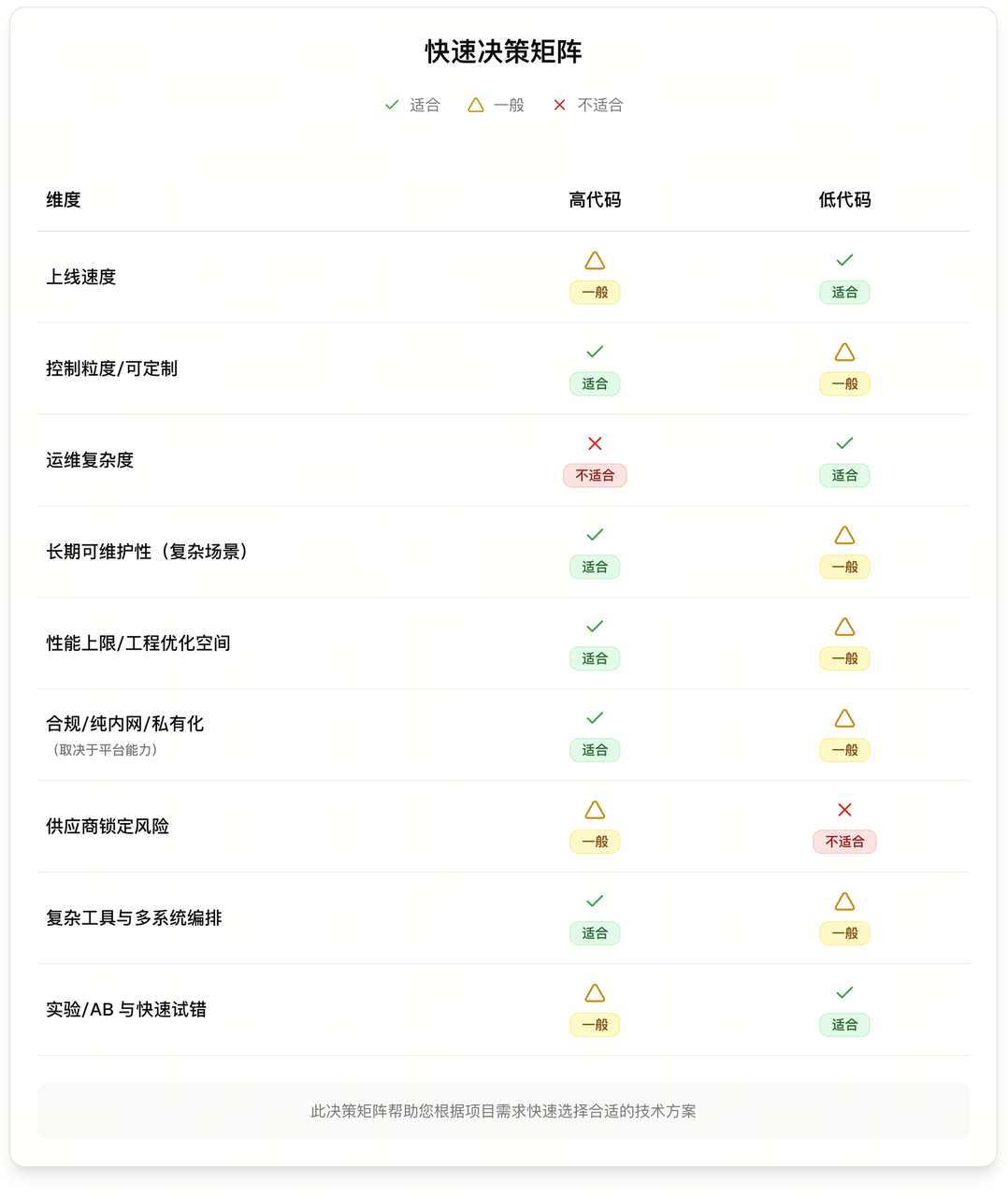
总结来说:要“快试错”选低代码,要“硬落地”选高代码;两者并不对立,适合“原型低代码 + 核心高代码”的混合路线。
具体来说:
●2 周内交付可用原型、验证需求是否真实 → 低代码
●承载 7×24 核心业务,SLA/审计/内网合规很硬 → 高代码
●大量业务同学参与、频繁改提示与流程 → 低代码 +(必要时)接入自研工具
●把 RAG/记忆/工具编排做成“组织级能力层” → 高代码(沉淀为平台/服务)
●先做 Demo,再逐步把关键链路“工程化” → 低→高的混合迁移
这里需要注意的是,要避免反模式:
●把复杂状态机硬堆在低代码画布里,后期难以维护与回放。
●过早全高代码,导致验证周期太长、需求未定先造轮子。
●忽视提示/知识/评测的版本化与可回滚。
混合实践
对于我们来说,现在正好处于一个 “混合迁移” 的阶段,我们即在使用低代码平台 Dify,也在某些具体的场景下感到了 Dify的不适。所以对于某些项目要进行必要的工程化迁移和改造,具体思路是:
●前台用低代码(业务侧快速改动、AB/评测、需求验证);
●后台用高代码沉淀“能力层”(RAG 服务、工具/MCP、回溯评测、观测/追踪、策略引擎)。
●平台只做编排与呈现,能力层提供稳定 API。
●形成“能力可复用、前台可迭代、核心可控”的结构。
一句话总结:低代码赢在速度,高代码赢在确定性;用低代码把事儿“做成”,再用高代码把事儿“做稳且做大”。
LangChain
概念说明
提到 LangChain 我们要先厘清一下概念,因为这里有两个概念:
第一,LangChain Inc. 是一家总部位于美国旧金山的前沿人工智能技术公司。公司成立于 2022 年,由 Harrison Chase 和 Ankush Gola 共同创立,2023 年正式独立成立公司实体。 公司注册于 2023 年 1 月 31 日,总部地址位于加利福尼亚州旧金山市 Decatur 街 42 号。

第二,LangChain 还是一个用来开发基于 LLM 的 AI 应用框架。
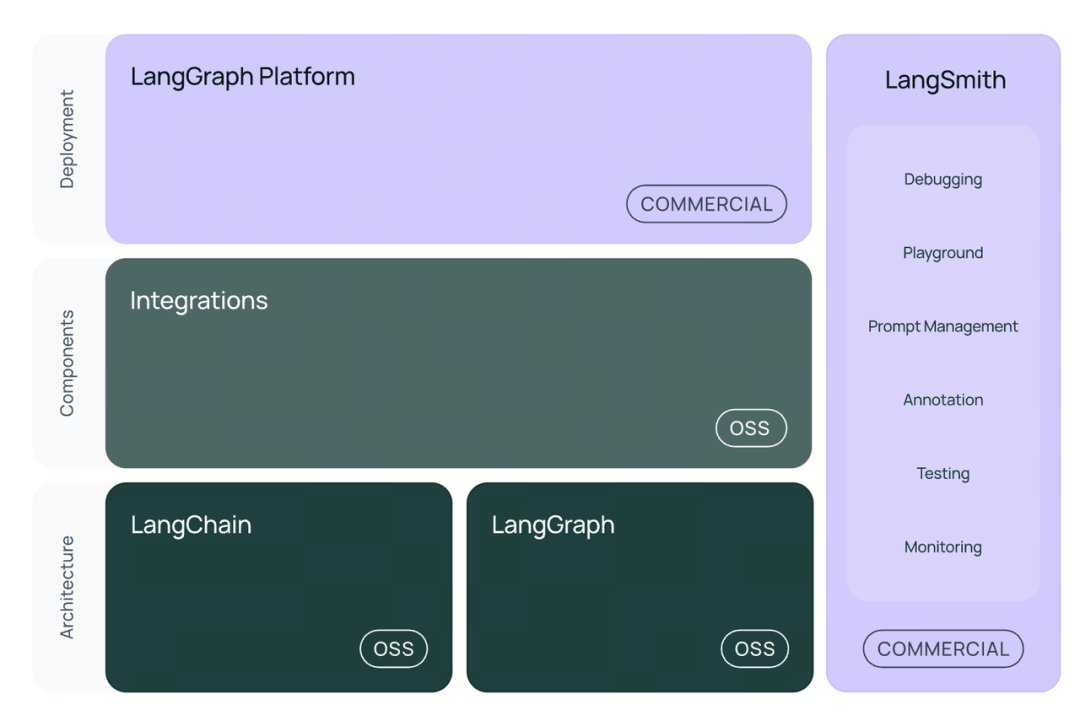
从 LangChain 公司官网和官方文档提供的产品架构图中可以看出,LangChain公司提供的主要产品有:
●开发框架
○LangChain(OSS-免费开源软件)
○LangGraph(OSS-免费开源软件)
●平台
○LangSmith (COMMERCIAL-商业收费)
○LangGraph Platform (COMMERCIAL-商业收费)
在下文中如无特殊说明,LangChain 一律指代第二个概念,即开源的开发框架。
大模型应用开发核心矛盾
当下的 LLM 本身如同一个 “博学但无手无脚的大脑”,它无法感知实时信息、无法操作外部工具、也无法与我们的私有数据交互。这个 “从 “模型能力” 到 “应用能力” 的鸿沟” 正是所有 LLM 应用开发者面临的首要难题。
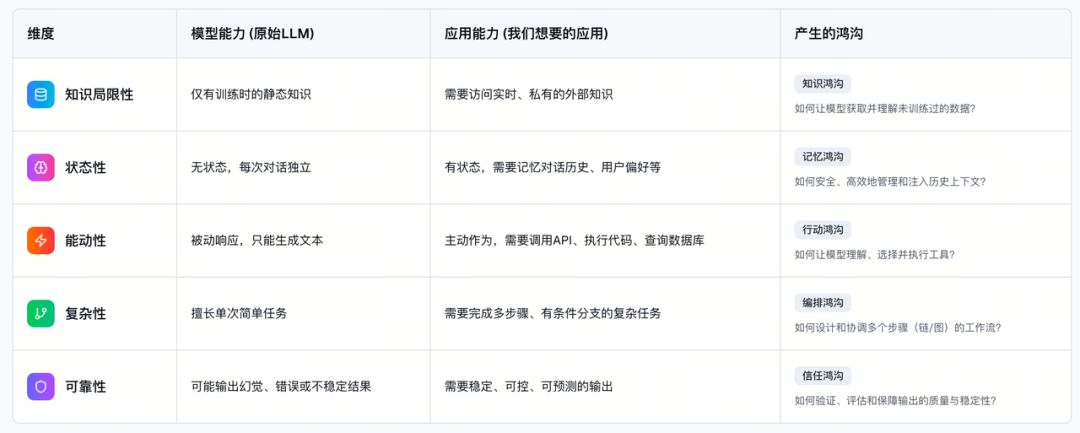
LangChain 不是一个 “新发明”,而是一个 “高效的连接器和编排器”。它的战略价值在于,它是当前弥合 “模型能力” 与 “应用能力” 鸿沟的最成熟的工程化解决方案之一。
框架介绍
LangChain 的核心思想是“链”,它将 LLM 应用程序的各个组件连接在一起,形成一个完整的工作流。这种模块化的方法可以将复杂的人工智能系统分解为可重用的部分。LangChain 提供了一系列工具和抽象,帮助开发人员将 LLM 与外部数据源(如数据库、API等)连接起来,从而创建功能更强大的应用程序。
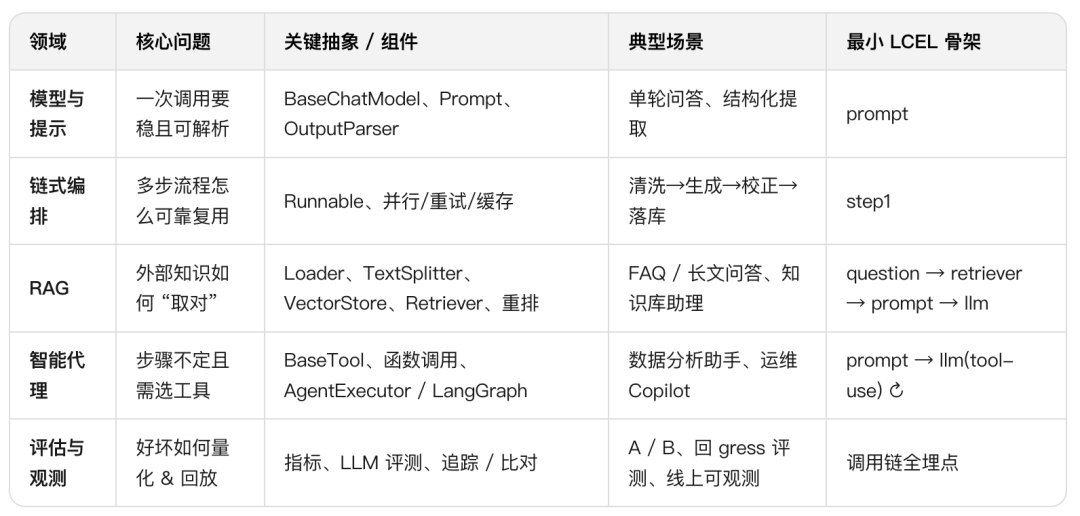
LangChain 能够解决的五类问题
LangChain 能够解决五个核心领域(按复杂度递增)
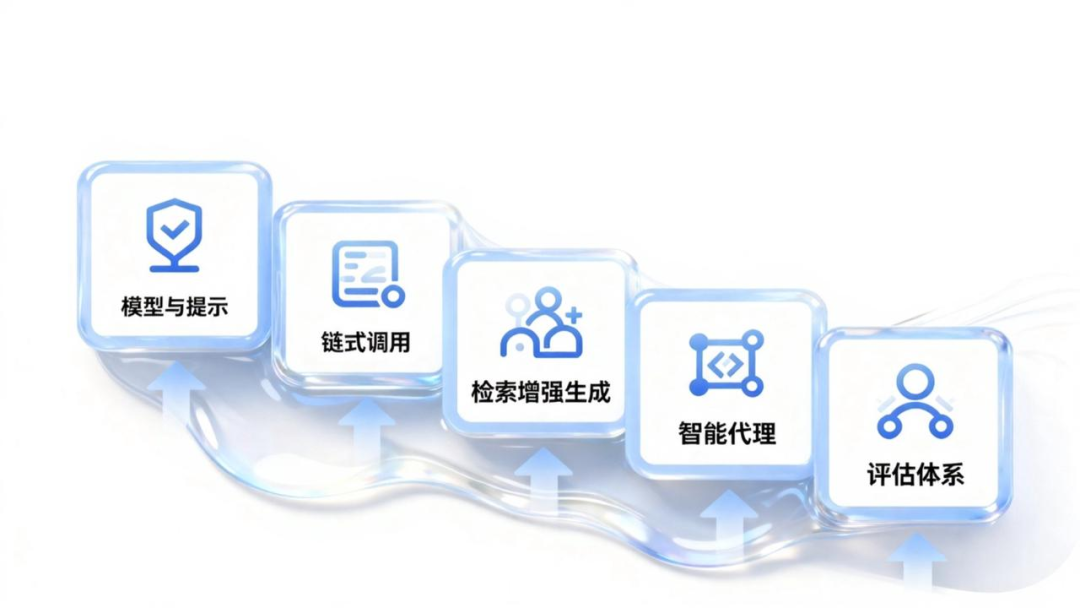
1. 模型与提示(I / O 层)
要解决什么? 稳定、可替换地调用任意 LLM,并拿到可解析、可复用的输出。
关键点:BaseChatModel、ChatPromptTemplate、OutputParser、LCEL invoke/stream/batch。
一般来说入门 LangChain 都是从第一层起步:prompt | llm | parser
1⚡ python片段# pip install -U langchain langchain-openai
2from langchain_core.prompts import ChatPromptTemplate
3from langchain_core.output_parsers import StrOutputParser
4from langchain_openai import ChatOpenAI
5
6prompt = ChatPromptTemplate.from_messages([
7 ("system", "你是精炼的中文助手。"),
8 ("human", "用一句话解释:{topic}")
9])
10
11chain = prompt | ChatOpenAI(model="gpt-4o-mini") | StrOutputParser()
12print(chain.invoke({"topic": "LCEL 是什么?"}))
2. 链式编排(流程层)
要解决什么? 把多个步骤(清洗→生成→解析→后处理)按顺序 / 并行可靠执行。
关键点:Runnable 统一协议、| 管道、并行 map、重试与超时、缓存
适用:流程确定、依赖明确的任务(如格式转换、规则后处理、批处理)。
1⚡ python片段# pip install -U langchain langchain-openai
2from langchain_core.runnables import RunnableLambda
3from langchain_core.prompts import ChatPromptTemplate
4from langchain_core.output_parsers import StrOutputParser
5from langchain_openai import ChatOpenAI
6
7pre = RunnableLambda(lambda x: {"q": x["q"].strip()[:200]}) # 预处理:清理&截断
8post = RunnableLambda(lambda s: s.rstrip("。") + "。") # 后处理:补全句号
9
10prompt = ChatPromptTemplate.from_messages([
11 ("system", "用简洁中文回答。"),
12 ("human", "把这些要点合成一句话:{q}")
13])
14
15chain = pre | prompt | ChatOpenAI(model="gpt-4o-mini", temperature=0) | StrOutputParser() | post
16print(chain.invoke({"q": "LCEL, Runnable, invoke/batch/stream"}))
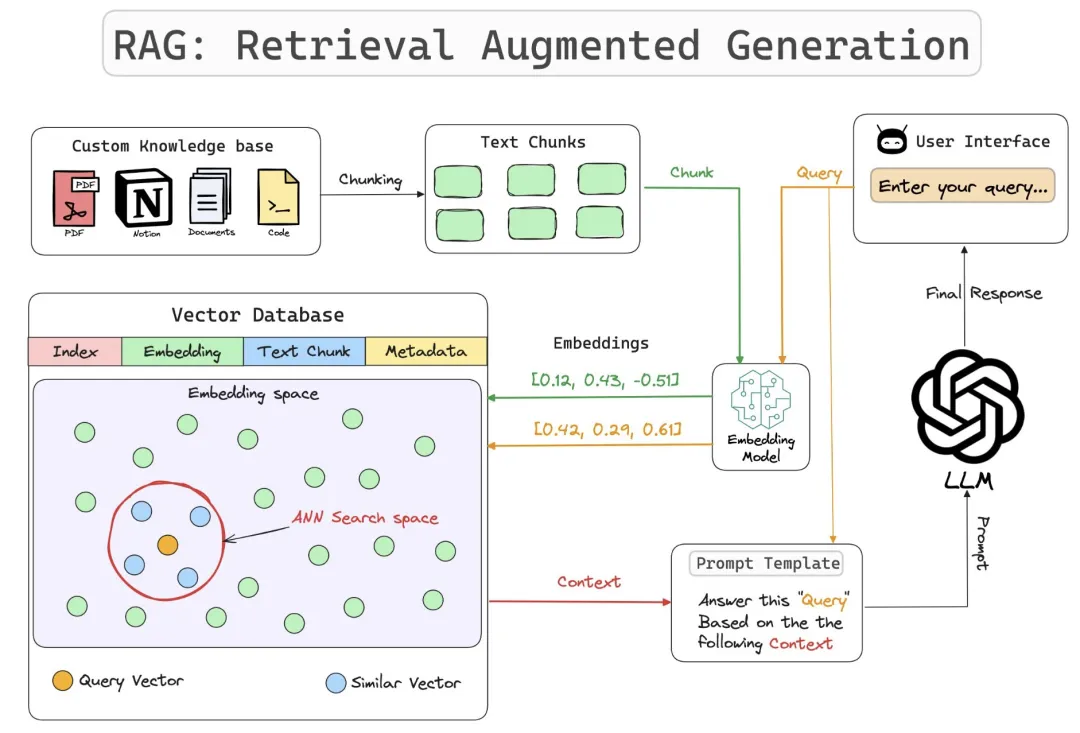
3. 检索增强生成 RAG(数据层)
要解决什么? 当模型 “知道的不够”,要从外部资料中取对内容。
关键点:Loader/TextSplitter → Embeddings → VectorStore → Retriever(可带重排 / 压缩)。
1⚡ python片段# pip install -U langchain langchain-openai langchain-community faiss-cpu
2
3from langchain_openai import ChatOpenAI, OpenAIEmbeddings
4from langchain_core.prompts import ChatPromptTemplate
5from langchain_core.output_parsers import StrOutputParser
6from langchain_core.runnables import RunnablePassthrough, RunnableLambda
7from langchain_community.vectorstores import FAISS
8
9# 1) 准备示例知识(演示使用;实际替换为你的文档)
10texts = [
11 "LCEL 是 LangChain 的可组合执行协议,用 | 串联组件(prompt、llm、parser)。",
12 "RAG(检索增强生成)通过向量检索把外部资料接入模型,以降低幻觉并注入最新知识。"
13]
14vs = FAISS.from_texts(texts, OpenAIEmbeddings())
15retriever = vs.as_retriever(k=3)
16
17# 2) RAG Prompt(把检索到的资料塞进上下文)
18prompt = ChatPromptTemplate.from_messages([
19 ("system", "你是知识助手,必须基于提供的资料回答。"),
20 ("human", "问题:{question}\n\n资料:\n{context}\n\n请用中文简洁作答,并在句末用[]引用关键词。")
21])
22
23# 3) 组合:question → retriever → prompt → llm → parser
24format_docs = RunnableLambda(lambda docs: "\n\n".join(d.page_content for d in docs))
25chain = (
26 {"context": retriever | format_docs, "question": RunnablePassthrough()}
27 | prompt
28 | ChatOpenAI(model="gpt-4o-mini", temperature=0)
29 | StrOutputParser()
30)
31
32print(chain.invoke("什么是 RAG?"))
4. 智能代理(自主层)
要解决什么? 目标不完全明确、步骤不固定,需要选择工具、反复试探(行动 - 观察 - 反思)。
关键点:BaseTool/工具调用、函数调用、AgentExecutor(或用 LangGraph 做有状态策略)、记忆 / 护栏。
1⚡ python片段# pip install -U langchain langchain-openai
2from langchain_openai import ChatOpenAI
3from langchain_core.tools import tool
4from langchain_core.messages import SystemMessage, HumanMessage, ToolMessage
5
6# 1) 定义一个可被模型调用的工具(OpenAI Tool Calling)
7@tool
8def multiply(a: int, b: int) -> int:
9 "精确乘法"
10 return a * b
11
12# 2) 绑定工具,让模型自行决定是否调用
13llm = ChatOpenAI(model="gpt-4o-mini", temperature=0).bind_tools([multiply])
14
15# 3) 行动-观察-再思考(最小一次循环)
16msgs = [
17 SystemMessage("你是严谨助手,涉及计算必须调用工具,不要心算。"),
18 HumanMessage("先算 12×34,再把结果乘以 2,给出最终数值即可。"),
19]
20
21ai = llm.invoke(msgs) # 行动:模型决定要不要调用工具
22msgs.append(ai)
23for tc in ai.tool_calls: # 观察:执行工具并把结果回传给模型
24 out = multiply.invoke(tc["args"])
25 msgs.append(ToolMessage(str(out), tool_call_id=tc["id"]))
26
27final = llm.invoke(msgs) # 再思考:基于工具结果给最终答案
28print(final.content)
5. 评估与观测(质量层)
要解决什么? 度量 “是否正确/有用/鲁棒”,以及在真实流量中看得见链路与瓶颈。
关键点:基准指标(EM/F1/检索命中率)、LLM 判分、回放/对比、LangSmith(或自建追踪)。
1⚡ python片段# pip install -U langchain langchain-openai
2from langchain_openai import ChatOpenAI
3from langchain_core.prompts import ChatPromptTemplate
4from langchain_core.output_parsers import StrOutputParser
5from langchain.evaluation import load_evaluator
6
7# 被评对象:最小 QA 链(LCEL)
8qa = (ChatPromptTemplate.from_template("用一句话回答:{q}")
9 | ChatOpenAI(model="gpt-4o-mini", temperature=0)
10 | StrOutputParser())
11
12q = "LCEL 是什么?"
13ref = "LCEL 是 LangChain 的统一执行协议,用 | 将组件串联成可组合管道。"
14
15pred = qa.invoke({"q": q})
16
17# LangChain 自带评估器:按“准确&简洁”两条标准打分+给理由
18evaluator = load_evaluator(
19 "labeled_criteria",
20 llm=ChatOpenAI(model="gpt-4o-mini", temperature=0),
21 criteria={"accuracy": "是否与参考一致且不捏造", "conciseness": "是否一句话且清晰"}
22)
23grade = evaluator.evaluate_strings(input=q, prediction=pred, reference=ref)
24
25print("答案:", pred)
26print("评分:", grade.get("score"), "理由:", grade.get("reason"))
总结如下:
架构图
LangChain 是一个以组合性为核心哲学的大语言模型应用开发框架

其设计理念是 “通过组合性构建LLM应用”,具体来说:
1.可组合性 (Composability):所有组件都是 Runnable,可以像乐高积木一样组合;使用 LCEL(LangChain Expression Language)轻松构建复杂流程
2.标准化接口 (Standardization):统一的输入输出接口;一致的同步/异步/批处理/流式处理方法
3.可扩展性 (Extensibility):通过继承基类轻松添加新实现;插件化架构,易于集成第三方服务
4.类型安全 (Type Safety):使用泛型和类型提示;编译时类型检查,减少运行时错误
架构层次
LangChain 采用严格的分层架构,从底层的核心抽象到上层的应用组件,确保了良好的模块化和可扩展性。
1⚡ text片段LangChain
2├── langchain-core/ # 核心抽象层
3│ ├── language_models/ # 基础模型抽象
4│ ├── runnables/ # LCEL 核心
5│ ├── prompts/ # 提示抽象
6│ └── ...
7│
8├── langchain/ # 主实现层
9│ ├── llms/ # LLM 实现
10│ ├── chat_models/ # Chat 实现
11│ ├── chains/ # 链实现
12│ └── ...
13│
14└── langchain-community/ # 社区集成
15 └── partners/ # 第三方集成
16 ├── openai/
17 ├── anthropic/
18 └── ...
模块结构
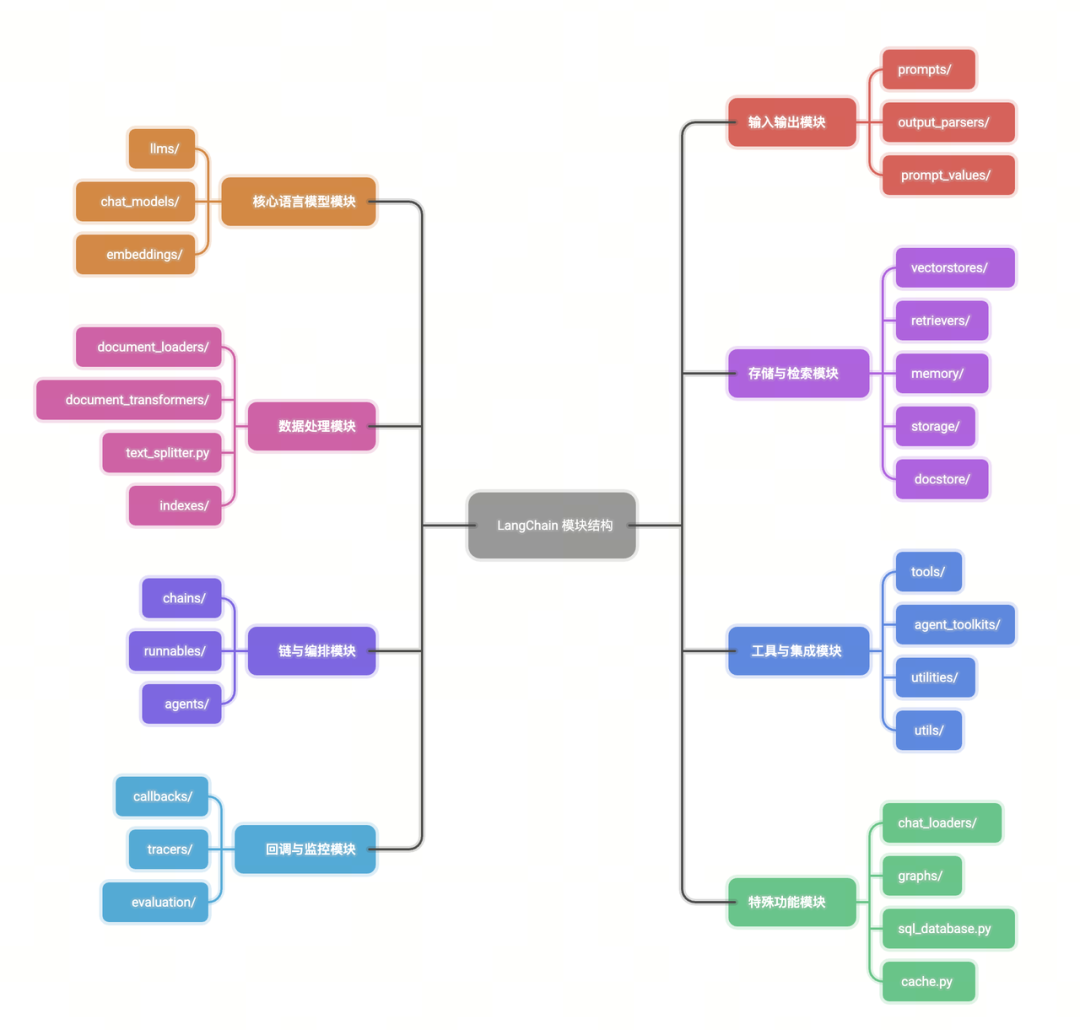
LangChain 主要包含以下模块:
1.核心语言模型模块
○llms/ - 传统 LLM(85+ 个实现)
○chat_models/ - 对话模型(35+ 个实现)
○embeddings/ - 嵌入模型(51+ 个实现)
2.输入输出模块
○prompts/ - 提示模板
○output_parsers/ - 输出解析器(23+ 种)
○prompt_values/ - 提示值处理
3.数据处理模块
○document_loaders/ - 文档加载器(166+ 种)
○document_transformers/ - 文档转换器
○text_splitter.py - 文本分割
○indexes/ - 索引管理
4.存储与检索模块
○vectorstores/ - 向量数据库(76+ 种)
○retrievers/ - 检索器(78+ 种)
○memory/ - 记忆管理(39+ 种)
○storage/ - 存储抽象
○docstore/ - 文档存储
5.链与编排模块
○chains/ - 各种链(144+ 个文件)
○runnables/ - 可运行组件
○agents/ - 智能体(146+ 个文件)
6.工具与集成模块
○tools/ - 工具集(186+ 种)
○agent_toolkits/ - 工具包
○utilities/ - 实用工具(59+ 个)
○utils/ - 辅助函数
7.回调与监控模块
○callbacks/ - 回调处理器(46+ 种)
○tracers/ - 追踪器
○evaluation/ - 评估工具(32+ 个)
8.特殊功能模块
○chat_loaders/ - 聊天记录加载
○graphs/ - 图处理
○sql_database.py - SQL 数据库支持
○cache.py - 缓存管理
Runnable 抽象
LangChain 的架构精髓在于 Runnable 接口 —— 一个"可以被调用、批处理、流化、转换和组合的工作单元" 。这个抽象提供了六种核心执行模式:
●invoke/ainvoke: 单次同步/异步执行
●batch/abatch: 并行同步/异步批处理执行
●stream/astream: 同步/异步流式输出执行

所有组件都实现 Runnable 接口,从检索器到代理系统 ,确保了组件间的无缝互操作性,使得 LangChain 组件具有极高的可组合性。
1⚡ 代码片段# 示例:链式组合
2chain = prompt | model | parser
LCEL:声明式表达语言
LangChain Expression Language (LCEL) 是框架的"声明式方法构建生产级程序" 。通过管道操作符(|)实现组件的优雅组合,天然支持异步、批处理和流式操作,这使得基于LCEL的程序能够更好地扩展以处理更高的并发负载。
LCEL 不仅仅是语法糖。它是一种声明式的编程范式。开发者只需声明 “数据如何流动”,而框架负责处理底层的执行、流式传输、并行化和日志记录。
1⚡ python片段# pip install -U langchain langchain-openai
2
3from langchain_core.prompts import ChatPromptTemplate
4from langchain_openai import ChatOpenAI
5from langchain_core.output_parsers import StrOutputParser
6
7# 1) Prompt:定义输入模板
8prompt = ChatPromptTemplate.from_messages([
9 ("system", "你是精炼、可靠的中文助手。"),
10 ("human", "用一句话回答:{question}")
11])
12
13# 2) LLM:任意 OpenAI 兼容服务均可(公有云/企业网关/vLLM 等)
14llm = ChatOpenAI(
15 model="gpt-4o-mini", # 换成你的模型名即可
16 api_key="YOUR_KEY", # 也可用环境变量 OPENAI_API_KEY
17 base_url="http://localhost:8000/v1" # 选填:本地或内网的 OpenAI 兼容地址
18)
19
20# 3) Parser:把模型返回的消息对象转成纯字符串
21parser = StrOutputParser()
22
23# LCEL:像搭乐高一样用“|”把组件串起来
24chain = prompt | llm | parser
25
26# ——最简单的单次调用(演示用)——
27print(chain.invoke({"question": "LCEL 是什么?"}))
28
29# ——可选:流式演示(边生成边打印)——
30for chunk in chain.stream({"question": "给出一条使用 LCEL 的建议"}):
31 print(chunk, end="")
32print()
33
34# ——可选:批量演示(一次处理多条)——
35print(chain.batch([
36 {"question": "一句话解释 LangChain"},
37 {"question": "一句话解释 LCEL 的优势"}
38]))
Schema 与类型系统
LangChain 的类型系统建立在 Python 的类型提示和 Pydantic模型之上,提供了一套完整的类型定义来支持 LLM 应用开发。LangChain 的类型系统具有以下特点:
1.强类型: 基于 Python 类型提示和 Pydantic,提供编译时和运行时类型检查
2.可组合: 通过 Runnable 接口实现组件的灵活组合
3.可序列化: 所有核心类型都继承自 Serializable
4.灵活性: 支持多种 Schema 定义方式(Pydantic、TypedDict、JSON Schema)
5.流式支持: 原生支持同步、异步、批处理和流式处理
6.标准化: 统一的输入输出类型定义,便于组件互操作
Pydantic 由 Samuel Colvin 创建,核心思想是:“使用类型注解定义数据模型,Pydantic 自动帮你验证和转换数据。” 它基于 Python 3.6+ 的类型提示系统(如 str, int, List, Optional 等),通过定义继承自 BaseModel 的类,来描述期望的数据结构。
想象一下,你正在指挥一个非常聪明但有点 “随心所欲” 的机器人。如果你只是模糊地说 “给我找点关于猫的资料”,它可能会给你一篇科学论文,一张猫的图片,或者一段猫叫的音频。这太不可预测了。LangChain 的 Schema 和类型系统,就像是给这个机器人的一套精确的 “指令图纸” 和 “数据表格”。它让你能够用一种机器人能精确理解的方式下达指令,并要求它以你想要的、规整的格式返回结果。下面我们通过几个场景和代码例子,来看看这些 “图纸” 和 “表格” 是怎么工作的。
场景 1: 从简单的闲聊到有角色区分的对话
一开始,我们和 AI 的交互很简单,就是 “一问一答”。
最基础的类型: Text (字符串): 这就是最原始的交互方式。
1⚡ 代码片段# 这其实就是最基础的文本 Schema
2my_question = "你好,你叫什么名字?"
3ai_response = "我是AI助手。"
但这很快就不够用了。在一个持续的对话中,AI 需要知道哪句话是谁说的,才能更好地理解上下文。
进阶类型: ChatMessage
ChatMessage 就是为了解决这个问题而生的 “对话表格”。它规定了每条消息都应该有 role (角色) 和 content (内容) 两列。主要角色有:
○SystemMessage: 系统指令。给 AI 设定一个 “人设” 或总体的行为准则。
○HumanMessage: 你的话。
○AIMessage: AI 的话。
每个元素都有明确的role 和content。 这让 AI 不再混乱,能够更好地进行多轮对话。
场景 2: 我需要 AI 给我一个结构化的数据,而不是一段话
假设你想让 AI 帮你生成用户信息,并存入数据库。如果你只对它说 “生成一个用户,名叫张三,25 岁,邮箱是 zhangsan@email.com”,它可能会返回:
●" 好的,用户信息如下:姓名:张三,年龄:25,邮箱:zhangsan@email.com"
●" 张三,25 岁,邮箱 zhangsan@email.com"
●" 这是一个名叫张三的用户,他今年 25 岁了,你可以通过 zhangsan@email.com 联系到他。"
这些都是字符串,程序很难处理!我们需要的是一个干净的、可以直接用的 JSON 对象。这时,我们就要给 AI 一张 “图纸”,告诉它我们想要的输出格式。在 LangChain 中,最常用的 “绘图工具” 就是Pydantic 库。
1⚡ python片段# 伪代码,演示核心逻辑
2from langchain_core.pydantic_v1 import BaseModel, Field
3from langchain_core.output_parsers import JsonOutputParser
4from langchain_openai import ChatOpenAI
5from langchain_core.prompts import PromptTemplate
6
7# 1. 用 Pydantic 画一张“图纸”,定义你想要的输出结构
8classUserProfile(BaseModel):
9 name: str = Field(description="用户的全名")
10 age: int = Field(description="用户的年龄")
11 email: str = Field(description="用户的电子邮件地址")
12 is_active: bool = Field(description="用户账户是否活跃")
13
14# 2. 创建一个输出解析器,告诉它要用哪张“图纸”
15parser = JsonOutputParser(pydantic_object=UserProfile)
16
17# 3. 在提示中,告诉AI要按照“图纸”的格式来回答
18prompt = PromptTemplate(
19 template="""
20 根据下面的用户信息,生成一个JSON对象。
21 用户信息:{user_info}
22 {format_instructions}
23 """,
24 input_variables=["user_info"],
25 # 把“图纸”的说明书(格式指令)插入到提示中
26 partial_variables={"format_instructions": parser.get_format_instructions()}
27)
28
29# 4. 创建模型并链接所有部分
30# model = ChatOpenAI(temperature=0)
31# chain = prompt | model | parser
32#
33# response = chain.invoke({"user_info": "创建一个用户,名叫李四,30岁,邮箱是 lisi@email.com,账户是活跃的。"})
34
35# 期望的 response 会是一个干净的 Python 字典,而不是字符串
36# print(response)
37#
38# 输出:
39# {'name': '李四', 'age': 30, 'email': 'lisi@email.com', 'is_active': True}
看到妙处了吗?通过定义UserProfile 这个 Schema,我们强制 AI 的输出符合我们预设的结构,让它的输出变得 100% 可预测和可用。
场景 3: 让 AI 使用我们定义的工具
假设你想让 AI 能够查询天气。AI 本身是不知道今天天气的,但你可以提供一个查询天气的函数(工具)给它。但是,AI 怎么知道这个函数是干嘛的?需要哪些参数?
LangChain 的 @tool 装饰器可以自动读取你函数的 “类型提示”(Type Hinting) 和文档字符串 (docstring),并把它们变成一份 AI 能看懂的 “工具说明书”。
1⚡ python片段# 伪代码,演示核心逻辑
2from langchain_core.tools import tool
3
4@tool
5def search_weather(city: str, unit: str = "celsius") -> str:
6 """
7 根据城市名称查询实时天气。
8 :param city: 城市的名字,例如:北京
9 :param unit: 温度单位,可以是 'celsius' (摄氏度) 或 'fahrenheit' (华氏度)
10 """
11 # 这里的代码会真实地去调用天气API
12 if city == "北京":
13 return f"北京现在的天气是 25°{unit}"
14 elif city == "上海":
15 return f"上海现在的天气是 28°{unit}"
16 else:
17 return f"抱歉,我查询不到 {city} 的天气。"
18
19# 当你把这个工具提供给一个支持工具调用的AI模型时,
20# LangChain会自动生成类似这样的“说明书”给AI看:
21# Tool Name: search_weather
22# Tool Description: 根据城市名称查询实时天气。
23# Tool Arguments:
24# - name: city, type: string, description: 城市的名字,例如:北京
25# - name: unit, type: string, description: 温度单位,可以是 'celsius' (摄氏度) 或 'fahrenheit' (华氏度)
26
27# 当你问AI:“北京今天天气怎么样?”
28# AI会分析你的问题,发现需要查询天气,然后查看它手上的“工具说明书”。
29# 它会找到 search_weather 工具,并自动生成调用参数:{"city": "北京", "unit": "celsius"}
30# 然后执行函数,得到结果,最后把结果用自然语言告诉你。
这里的 city: str 和 unit: str 就是 Schema 的一部分,它明确规定了工具需要什么类型的输入。文档字符串 “”"…""" 则成了 AI 理解工具功能的关键。
核心抽象组件
LangChain 的架构围绕以下几个基本抽象组件构建,这些抽象组件共同构成了 LangChain 的核心架构,让开发者能够快速构建复杂的 LLM 应用。每个组件都有明确的职责,通过 Runnable 接口相互连接,形成了一个强大而灵活的框架。
Language Models (语言模型)
提供文本生成、对话、推理等核心 AI 能力
●BaseLanguageModel: 所有语言模型的基类,它继承自 RunnableSerializable,并定义了语言模型交互的通用接口 。它通过其 generate_prompt() 方法接受 PromptValue 对象 。
●BaseChatModel: 对话模型(GPT-4、Claude)- 处理消息序列
●BaseLLM: 文本生成模型 - 处理字符串输入输出
Prompts (提示模板)
输入构造层,支持变量替换、少样本示例、消息格式化
●BasePromptTemplate: 动态构造模型输入
●ChatPromptTemplate: 构造对话消息序列
●PromptTemplate: 构造文本提示
Messages (消息)
对话交互的基本单元
●BaseMessage: 所有消息的基类
●HumanMessage: 用户消息
●AIMessage: AI 回复
●SystemMessage: 系统指令
●ToolMessage: 工具调用结果
Documents (文档)
知识存储的基本单元,是 RAG(检索增强生成)的基础数据结构
●Document: 包含 page_content(内容)和 metadata(元数据)
●用于表示任何文本数据:网页、PDF、数据库记录等
Retrievers (检索器)
知识检索层,RAG 架构的核心组件
●BaseRetriever: 是文档检索系统的抽象基类,它实现了 Runnable 接口以实现可组合性。它定义了基于查询检索相关文档的标准接口。
●连接向量数据库、搜索引擎、数据库等
Vector Stores (向量存储)
语义搜索的基础设施
●VectorStore: 向量数据库的抽象接口
●存储和检索文档的向量表示
●支持相似度搜索、混合搜索等
Embeddings (嵌入)
文本向量化,提供了嵌入模型的抽象接口,定义了将文本转换为向量表示的方法。它要求实现 embeddocuments() 和 embedquery() 方法。是语义搜索和相似度计算的基础。
●Embeddings: 将文本转换为向量表示
●支持各种嵌入模型(OpenAI、Hugging Face 等)
Output Parsers (输出解析器)
结构化输出,确保模型输出符合预期格式
●BaseOutputParser: 解析模型输出为结构化数据
●PydanticOutputParser: 解析为 Pydantic 模型
●JsonOutputParser: 解析为 JSON
Tools (工具)
BaseTool 是供智能体(Agents)使用的工具(Tools)的抽象基础,继承自 RunnableSerializable,并为与外部系统交互提供了标准化接口 。是 Function Calling 和 Agent 的基础。
●BaseTool: 定义模型可调用的外部功能
●让模型能执行计算、查询数据库、调用 API 等
Callbacks (回调)
观察和控制执行流程,提供执行过程的可见性
●BaseCallbackHandler: 监听和响应执行事件
●用于日志记录、调试、监控、流式输出等
Memory/Cache (记忆/缓存)
状态管理,对话历史管理、会话状态保持
●BaseCache: 缓存 LLM 响应,避免重复调用
●BaseStore: 键值存储抽象
对照表
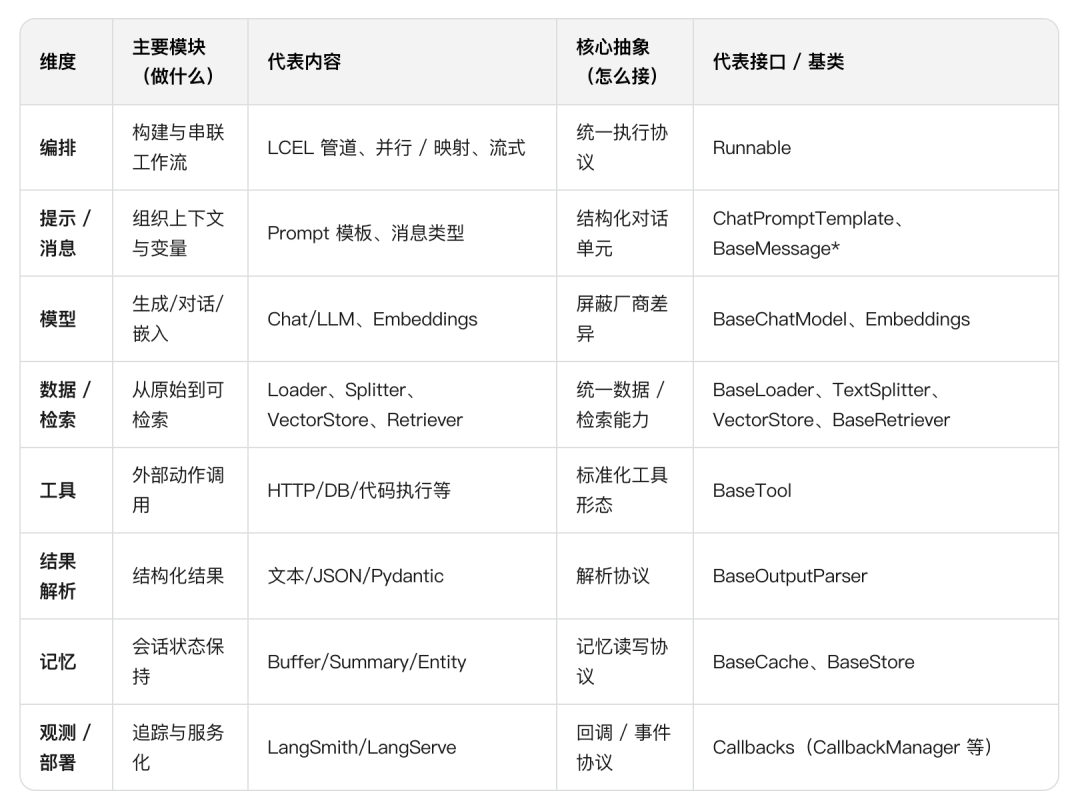
这里是一个快速对照表,来将上文的 LangChain 模块与核心抽象组件之间做个对应。
模块就像房间(客厅/厨房/卧室),抽象就像插座与标准接口(任意电器都能插上电并协同工作)。
●主要模块 = 按 “职能分区” 的功能板块(编排、模型、检索、Agent、记忆、部署等),回答 “系统里有哪些能力”。
●核心抽象 = 跨模块通用的接口 / 基类(如 Runnable、BaseChatModel、BaseRetriever…),回答 “各模块如何被替换与拼装”。
Agent
LangChain 框架完全可以构建 Agent,并且这是它自诞生以来最核心、最吸引人的功能之一。经典的 Agent(如 ReAct 范式)通过 AgentExecutor 实现一个 “思考 -> 行动 -> 观察” 的循环。LLM 在这个循环中扮演决策者,决定下一步调用哪个工具(Tool)。对于绝大多数单 Agent 任务,LangChain 的原生 Agent 完全够用。
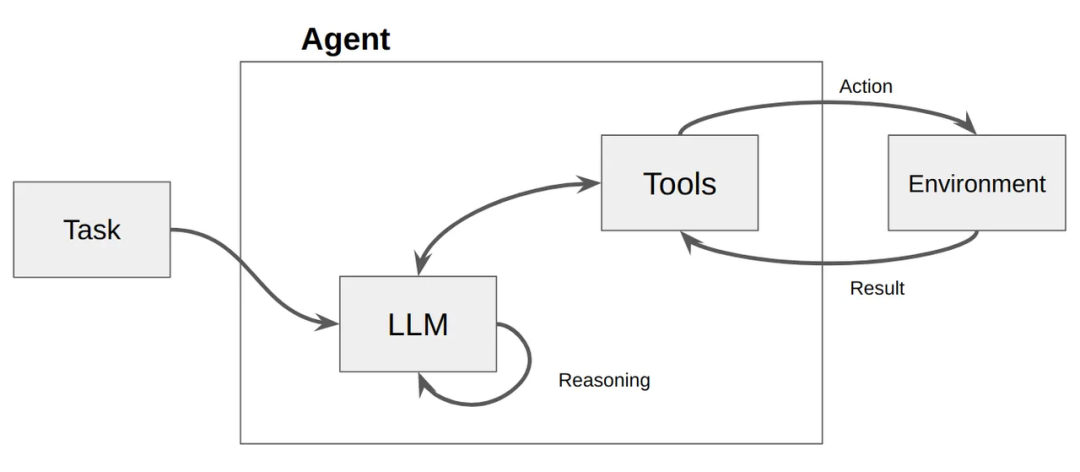
但是,当 Agent 的逻辑变得极其复杂,例如:
1.需要循环和分支: 当流程不是线性,而是需要在多个步骤之间来回跳转。
2.需要多 Agent 协作: 例如,一个 “分析师 Agent” 生成报告,交给 “代码生成 Agent” 编写代码,再由 “测试 Agent” 进行验证,如果测试失败,流程需要返回给 “分析师 Agent” 重新分析。
3.需要持久化的状态管理: 在复杂的交互中,需要精确控制每一步的状态。
这时 LangGraph 框架应运而生。它将 Agent 的工作流显式地定义为一个 状态图 (State Graph)。每个节点是一个工作单元(一个 LLM 调用或一个工具调用),每条边是状态的转移。它不是取代了 LangChain Agent,而是为构建更强大、更可控的 “状态化 Agent 系统” 提供了新的范式。
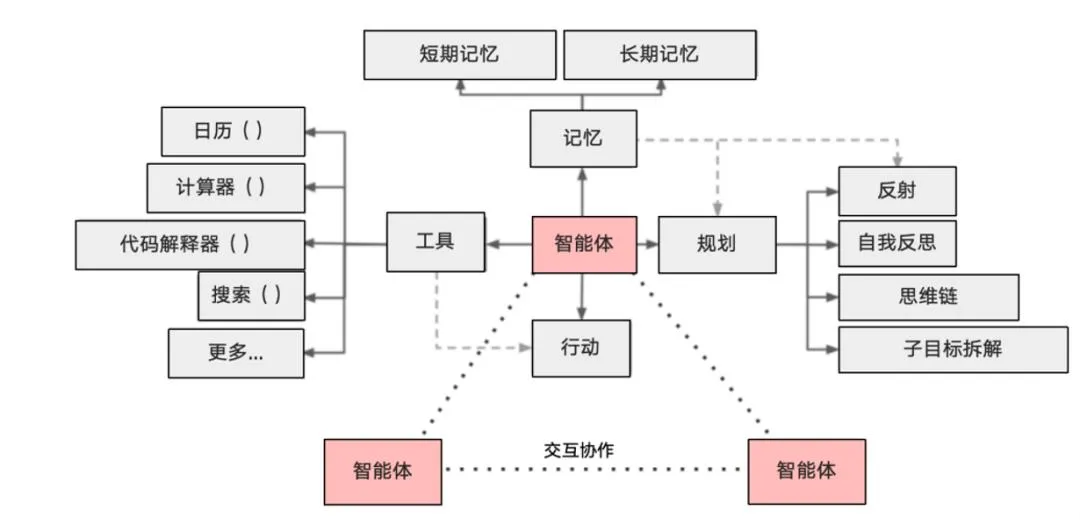
LangGraph
LangGraph 可以独立使用,但它也可以无缝集成到任何 LangChain 产品中。
LangGraph 提供了比 LangChain 更底层、更灵活的控制能力,特别适合需要状态管理、人机协作和复杂流程编排的场景。而 LangChain 则更适合快速原型开发和简单的链式处理任务。两者可以协同使用:LangChain 的组件可以作为 LangGraph 的节点,但 LangGraph 也可以完全独立于 LangChain 使用。
如果不用 LangGraph 开发,选择其他框架,推荐使用 CrewAI。
LangGraph 架构
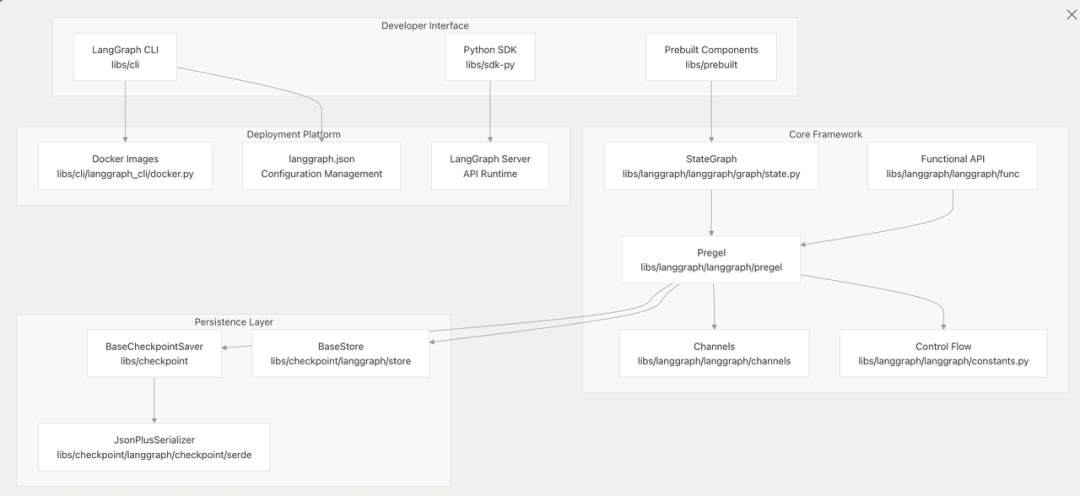
LangGraph 的执行流程遵循以下算法:
LangChain 与 LangGraph 适用场景对比:
LangChain 与 LangGraph 代码对比
LangChain(使用 AgentExecutor):
1⚡ python片段# pip install -U langchain langchain-openai
2import os
3from datetime import datetime
4
5from langchain_openai import ChatOpenAI
6from langchain_core.tools import tool
7from langchain_core.prompts import ChatPromptTemplate
8from langchain.agents import create_tool_calling_agent, AgentExecutor
9
10# ========== Tools ==========
11@tool
12def multiply(a: float, b: float) -> float:
13 """Return a*b."""
14 return a * b
15
16@tool
17def get_time(fmt: str = "%Y-%m-%d %H:%M:%S") -> str:
18 """Return current local time formatted by fmt."""
19 return datetime.now().strftime(fmt)
20
21tools = [multiply, get_time]
22
23# ========== LLM ==========
24llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
25
26# ========== Agent ==========
27prompt = ChatPromptTemplate.from_messages([
28 ("system", "You are a concise tool-using agent. Use the tools when helpful. Reply in Chinese."),
29 ("human", "{input}")
30])
31
32agent = create_tool_calling_agent(llm, tools, prompt)
33executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
34
35# ========== Demo ==========
36res = executor.invoke({
37 "input": "先用 multiply 计算 7×12,再调用 get_time 给出当前时间。答案只要一行。"
38})
39print("Final:", res["output"])
我来画出详细的流程图,展示这个 LangChain Agent 的执行过程:
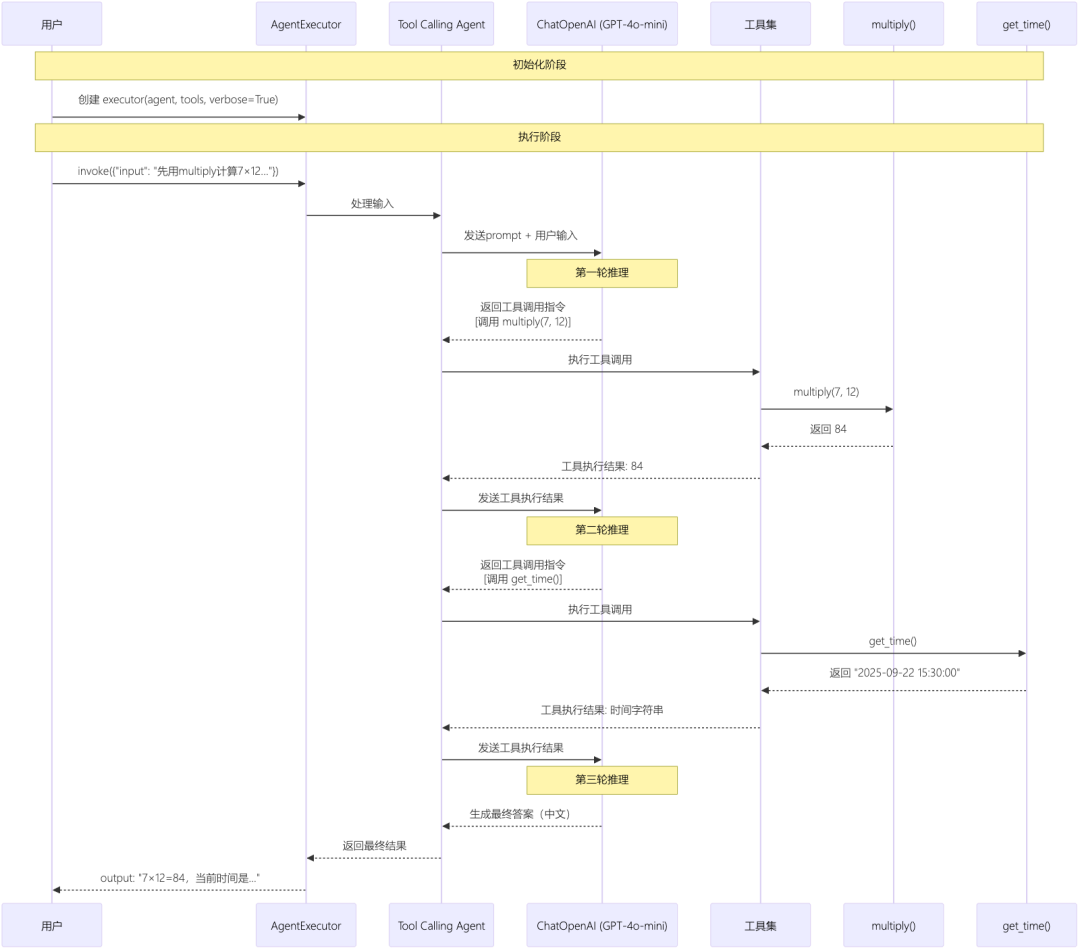
LangGraph 代码:
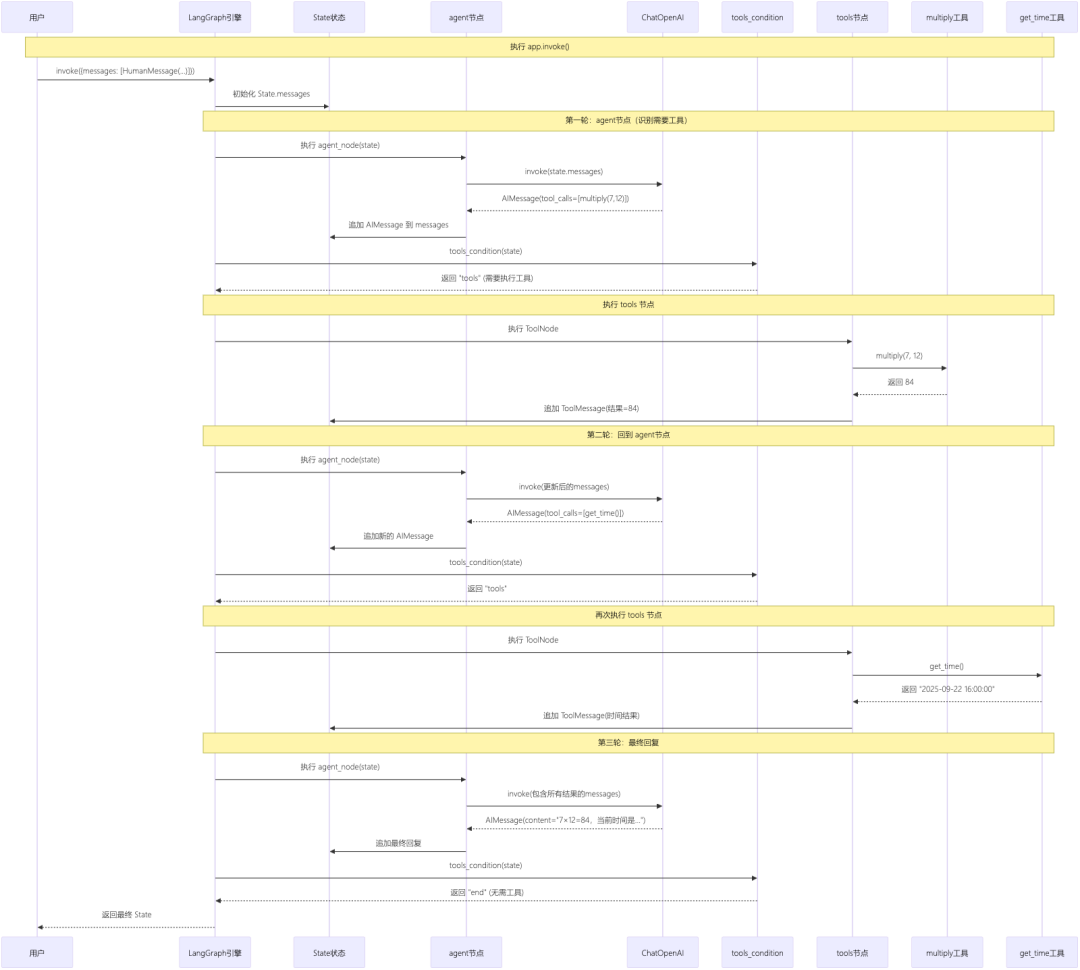
1⚡ python片段# pip install -U langgraph langchain langchain-openai
2from datetime import datetime
3from typing import Sequence
4from typing_extensions import TypedDict
5
6from langchain_core.tools import tool
7from langchain_core.messages import AnyMessage, HumanMessage
8from langchain_openai import ChatOpenAI
9
10from langgraph.graph import StateGraph, END # END 表示图的终点
11from langgraph.prebuilt import ToolNode, tools_condition # 预置的“工具节点”和“是否需要走工具”的路由函数
12
13# ===== 工具定义:用 @tool 自动生成 JSON Schema,便于模型函数调用 =====
14@tool
15def multiply(a: float, b: float) -> float: # 定义乘法工具
16 return a * b
17
18@tool
19def get_time(fmt: str = "%Y-%m-%d %H:%M:%S") -> str: # 定义获取时间工具
20 return datetime.now().strftime(fmt)
21
22tools = [multiply, get_time] # 工具列表(给模型/工具节点用)
23
24# ===== 绑定工具到模型:让 LLM 知道有哪些可调用的函数(工具) =====
25llm = ChatOpenAI(model="gpt-4o-mini", temperature=0).bind_tools(tools)
26# bind_tools(...) 的效果:
27# 1) 把 tools 的参数签名/描述转成 JSON Schema 给模型;
28# 2) 让模型在需要时产生 tool_calls(函数调用)结构,而不是直接“胡说答案”。
29
30# ===== 定义“状态”的数据结构:LangGraph 的节点之间传的就是这个 State =====
31classS(TypedDict):
32 messages: Sequence[AnyMessage] # 一串消息(人类/AI/工具消息),作为“对话上下文”
33
34# ===== 定义一个“模型节点”:输入 State,调用 LLM,输出一条 AI 消息 =====
35def agent_node(state: S):
36 # 关键:把现有 messages(含用户、人类消息、工具结果等)喂给 LLM
37 ai_msg = llm.invoke(state["messages"]) # 可能返回带 tool_calls 的 AIMessage
38 return {"messages": [ai_msg]} # LangGraph 会把这条消息合并到全局 state
39
40# ===== 搭建“有向图”:节点 + 边,决定执行路径 =====
41g = StateGraph(S) # 新建一个“状态图”,S 是状态类型(结构)
42
43# ——① 注册节点(起名叫 "agent" 和 "tools")——
44g.add_node("agent", agent_node) # 把上面的函数包装成一个图节点
45g.add_node("tools", ToolNode(tools)) # 预置的工具节点:会读取 AI 的 tool_calls 并执行
46
47# ——② 设置“入口节点”:从哪个节点开始跑——
48g.set_entry_point("agent") # ★ 从 "agent" 开始(也就是先问一次模型)
49# 解释:这句相当于“第一步进图先走哪个节点”。如果不设,编译时会报错或不知道从哪开始。
50
51# ——③ 配置“条件边”:根据模型输出决定接下来走哪条边——
52g.add_conditional_edges(
53 "agent", # 从 "agent" 节点出来时
54 tools_condition, # 用预置的判断函数:看 AIMessage 是否包含 tool_calls
55 {"tools": "tools", "end": END} # 如果需要工具→去 "tools";否则→直接结束
56)
57# 解释:tools_condition 会检查最新一条 AI 消息。
58# - 若模型产生了函数调用(tool_calls),返回路由键 "tools"
59# - 若没有需要的工具调用,返回路由键 "end"
60# 这行把路由键映射为真正的边:“tools”→去 tools 节点,“end”→走到 END(图的终点)。
61
62# ——④ 把工具节点执行完后的边接回“agent”,形成闭环——
63g.add_edge("tools", "agent")
64# 解释:当 tools 节点执行完所有函数调用,会把结果(ToolMessage)追加到 state.messages,
65# 然后回到 "agent" 再问一次模型。直到模型不再发起新的 tool_calls。
66
67# ——⑤ 编译成可运行的“应用”对象——
68app = g.compile()
69# 解释:compile() 会把上面定义的节点/边/合并策略等打包成可执行的图(可 invoke/stream)。
70
71# ===== 运行:给一条人类消息,按图的“入口节点”开始执行 =====
72final = app.invoke({
73 "messages": [HumanMessage(content="先用 multiply 计算 7×12,再调用 get_time 报当前时间。只要一行中文。")]
74})
75# 解释:invoke 会:
76# step1: 进入入口 "agent" → LLM 读到 HumanMessage,判断要不要调用工具;
77# step2: 如果需要工具 → 路由到 "tools" 执行(得到 ToolMessage)→ 回到 "agent";
78# step3: 重复 step1~2,直到不需要工具 → 按条件边路由到 END → 返回最终状态。
79
80print(final["messages"][-1].content) # 打印最后一条 AI 的自然语言回复
LangGraph 详细执行流程:
竞品
如果不使用 LangChain 开发 AI/LLM 应用,以下是主要的替代框架选择:
以下是按要求整理的表格内容:
| 框架 | 定位/标签 | 语言/平台 | 核心优势关键词 | 典型场景 | 🔎RAG | 👥Agent | 🏢企业 | 🎯输出控制 | 🪶轻量 |
|---|---|---|---|---|---|---|---|---|---|
| LlamaIndex | RAG 与数据检索专家 | Py/TS | 多索引策略、查询路由、强检索、结构/非结构数据 | 知识库问答、文档分析、RAG | ★★★★★ | ★★☆☆☆ | ★★★☆☆ | ★★☆☆☆ | ★★★☆☆ |
| CrewAI | 多智能体团队协作 | Py | 角色/任务、顺序/并行/层级协作、社区活跃 | 多智能体系统、内容流水线、任务分解 | ★★☆☆☆ | ★★★★★ | ★★★☆☆ | ★★☆☆☆ | ★★★☆☆ |
| Semantic Kernel | 企业级 AI 编排 | C#/Py/Java | 技能/规划器、Azure 深度集成、微软背书 | 企业应用、复杂规划、微软技术栈 | ★★★☆☆ | ★★★☆☆ | ★★★★★ | ★★☆☆☆ | ★★☆☆☆ |
| Haystack | NLP/搜索系统专家 | Py | Pipeline 清晰、文档处理强、评测完善、重隐私 | QA 系统、语义搜索、信息抽取 | ★★★★☆ | ★★☆☆☆ | ★★★★☆ | ★★☆☆☆ | ★★★☆☆ |
| AutoGen | 自动化对话与代码生成 | Py | 代码生成/执行、多 Agent 对话、自动化流程、人机协作 | 代码生成、数据分析自动化、技术任务 | ★★☆☆☆ | ★★★★☆ | ★★★☆☆ | ★★☆☆☆ | ★★★☆☆ |
| Guidance | 精确输出控制 | Py | 模板语言、强格式约束、轻量高效 | 结构化输出、格式化生成、提示工程 | ★☆☆☆☆ | ★☆☆☆☆ | ★★★☆☆ | ★★★★★ | ★★★★☆ |
还有一些新兴 / 特色框架:
以下是按要求整理的表格内容:
| 框架 | 定位/标签 | 语言/平台 | 核心优势关键词 | 典型场景 | 🔎RAG | 👥Agent | 🏢企业 | 🎯输出控制 | 🪶轻量 |
|---|---|---|---|---|---|---|---|---|---|
| LiteLLM | 统一 LLM API | Py | 100+ 模型统一接口、超轻量、零依赖 | 简单 LLM 调用、多模型切换、原型 | ★☆☆☆☆ | ★☆☆☆☆ | ★★★☆☆ | ★★☆☆☆ | ★★★★★ |
| DSPy | 声明式/自动提示优化 | Py | 可学习模块、自动调参、学术完善 | 指标导向优化、研究/实验 | ★★★☆☆ | ★★☆☆☆ | ★★☆☆☆ | ★★★☆☆ | ★★★☆☆ |
| txtai | 轻量 Transformers 框架 | Py | HF 生态、内置向量库、性能好 | 轻量语义搜索、嵌入式应用 | ★★★☆☆ | ★☆☆☆☆ | ★★☆☆☆ | ★★☆☆☆ | ★★★★☆ |
| MetaGPT | “AI 软件公司”模拟 | Py | 角色分工、项目级生成、代码产出 | 自动化软件开发、代码生成 | ★☆☆☆☆ | ★★★★☆ | ★★☆☆☆ | ★★☆☆☆ | ★★☆☆☆ |
在实际开发中,如不用 LangChain, 选型范围会缩小到最流行的几个竞品,比如:
●🦙 LlamaIndex:原名 GPT-Index,是一个开源的数据框架,专门用于构建大型语言模型 (LLM) 应用。它主要解决了如何将 LLM 与外部数据有效连接的问题,使开发者能够创建更强大的知识密集型应用。
●🚢 CrewAI:多智能体团队协作框架,CrewAI 是一个轻量、快速的 Python 框架,完全从零构建,与 LangChain 或其他代理框架完全无关。它为开发者提供高级别的简洁性和精确的底层控制,非常适合创建适用于任何场景的自主 AI 代理。
●🔧 Haystack:一个端到端的大型语言模型(LLM)框架,它允许你构建由 LLM、Transformer 模型、向量搜索等功能驱动的应用程序。
●🚀 AutoGen:用于创建能够自主行动或与人类协作的多智能体AI应用的框架
需要注意的是:这些框架不是互斥的,可以组合使用(如 LlamaIndex + CrewAI)
推荐学习路径
掌握灵魂 ——LCEL (LangChain Expression Language)
这是当前 LangChain 的绝对核心,也是最佳实践的开端。忘记很多旧的、高阶的 Chain 对象,从 LCEL 开始。
实践: 构建你第一个,也是最重要的 LCEL 链:
1⚡ python片段from langchain_core.prompts import ChatPromptTemplate
2from langchain_openai import ChatOpenAI
3from langchain_core.output_parsers import StrOutputParser
4
5# 1. 定义提示模板 (Prompt)
6prompt = ChatPromptTemplate.from_template("请给我讲一个关于{topic}的笑话。")
7# 2. 初始化模型 (Model)
8model = ChatOpenAI()
9# 3. 定义输出解析器 (Parser)
10output_parser = StrOutputParser()
11
12# 4. 使用管道符 | 链接起来
13chain = prompt | model | output_parser
14
15# 5. 执行链
16result = chain.invoke({"topic": "程序员"})
17print(result)
这个 | 管道符就是 “数据流” 的体现。invoke 的输入字典首先流入 prompt 变成一个完整的提示,然后流入 model 得到模型的响应,最后流入 output_parser 提取出字符串结果。
构建最核心的应用 ——RAG
理解了 LCEL 后,构建一个基础的 RAG 应用来贯穿大部分核心组件。
实践:
1.加载 (Load): 使用 TextLoader 或 PyPDFLoader 加载一个本地文件。
2.分割 (Split): 使用 RecursiveCharacterTextSplitter 将文档分割成块 (Chunks)。
3.存储 (Store): 使用 OpenAIEmbeddings 创建嵌入,并使用 FAISS 或 Chroma 等向量数据库进行存储。
4.检索 (Retrieve): 从向量数据库创建一个 retriever 对象。
5.生成 (Generate): 使用 LCEL 将检索到的内容、用户问题和模型调用组合成一个完整的 RAG 链。这比使用旧的 RetrievalQA 链更能让你理解内部原理。
进入高阶 ——Agents
当你的应用需要与外部世界交互(如调用 API、查询数据库)时,才需要 Agent。
实践:
1.定义一两个简单的 Tool,例如一个用于数学计算的工具,一个用于获取当前日期的工具。
2.选择一个 Agent 类型 (如 createopenaitools_agent)。
3.使用 AgentExecutor 来运行它,观察它如何根据你的问题选择工具、执行并返回结果。
常见陷阱与挑战
抽象泄漏 (Leaky Abstraction)
定义: 一个 “抽象” 旨在隐藏底层实现的复杂性。当这个抽象无法完全隐藏底层细节,导致你必须理解底层是如何工作的才能正确地使用它或排查问题时,就发生了 “抽象泄漏”。
LangChain 中的具体例子 (以旧版的 RetrievalQA 链为例):
●美好的抽象: RetrievalQA 链看起来很简单,你只需要给它一个 llm 和一个 retriever,它就能帮你完成 RAG。你期望它能 “神奇地” 工作。
●泄漏的现实:
a.Prompt 在哪里? 你发现问答效果不好。为什么?因为 RetrievalQA 内部使用了一个默认的、隐藏的 Prompt 模板 (类似 “Use the following pieces of context to answer the user’s question…")。这个默认模板可能不适合你的模型(比如某些中文模型),或者不符合你的业务场景。
b.文档如何组合? 当 retriever 返回了 4 个文档块 (Chunks) 时,这些文档是如何被塞进最终的 Prompt 里的?是简单拼接吗?如果超过了模型的上下文窗口怎么办?RetrievalQA 有一个 chaintype 参数(如 stuff, mapreduce)来控制这个行为。
问题的根源: 为了解决上述问题,你被迫去阅读 LangChain 的源码,去理解 RetrievalQA 内部隐藏的 Prompt 和文档组合逻辑。这时,RetrievalQA 这个本应让你省心的 “高级抽象”,反而成了你理解和调试的障碍。抽象 “泄漏” 了底层的实现细节。
如何应对?
拥抱 LCEL: LCEL 在很大程度上解决了这个问题。通过 prompt | model | parser 的方式, Prompt 是显式的,数据流是清晰的。你可以完全控制每一个环节,没有 “魔法” 和隐藏的逻辑。这是一种更 “白盒” 的构建方式,虽然初看起来代码多了一点,但可控性和可调试性大大增强。当然还有一种方案就是 “取其精华,去其糟粕”,LangChain 框架引入后,只用必要的部分组件,其余需要灵活处理的部分,全手写。
调试的 “黑盒感”
问题: 链的最终输出不符合预期,但中间过程完全不可见,不知道是 Prompt 错了、检索出的文档错了,还是模型理解错了。
解决方案: LangSmith。这是解决此问题的标准答案。设置环境变量 LANGCHAINTRACINGV2=“true” 即可开始追踪。用不了 LangSmith 的话,也可以用开源的 langfuse 替代。
对简单任务过度设计
问题: 你的任务只是需要根据一个模板调用一次 OpenAI API。这种情况下,引入 LangChain 的 LLMChain 相比直接使用 openai 库的 client.chat.completions.create(),增加了不必要的复杂性。
解决方案: 保持务实。如果你的应用逻辑非常简单,就是一个单一的 LLM 调用,那么直接使用原生 SDK 可能更清晰、更轻量。当且仅当你需要编排多个步骤(如 RAG)、管理记忆、或使用 Agents 时,LangChain 的价值才能最大化。
LangChain 的版本演进
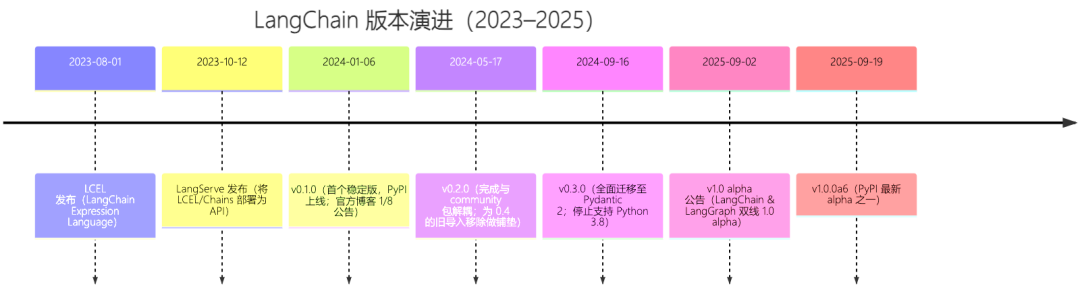
v1.0 alpha:和 v0.x 的关键差异
v1.0 alpha(2025-09)是 LangChain 的一次 “面向长期” 的大改版
核心变化
●消息模型统一:新增 .content_blocks(标准化的 “内容块” 视图),把不同厂商的 “推理、引用、服务端工具调用、多模态” 等表示成 同一种类型,减少 provider 差异带来的胶水代码;对旧 .content 后向兼容。
●Agent 重心调整:create_agent() 成为默认入口,底层基于 LangGraph 的图式运行时(持久化、流式、人审 / 中断、错误处理更规范)。
●包面积极度收敛:langchain 更聚焦 “标准接口 + 预置 Agent / 链”;历史面迁到 langchain-legacy,便于兼容老代码再慢慢重构。
●默认行为与平台要求:
○Python 需 ≥3.10;Chat 模型返回类型固定为 AIMessage;OpenAI Responses API 的默认输出版本调整(可用 LCOUTPUTVERSION=v0 退回);Anthropic max_tokens 默认值上调。
○JS / TS 侧:核心原语(createAgent、ToolNode、tool、消息类型)直接从 langchain 导出;Node.js 需 ≥20;大量老子路径导出清理。
三个常见场景
1.“会用工具、可结构化返回” 的 Agent
v0.x(典型写法):构建 Agent + Executor,再自己管结构化解析 / 二次调用
1⚡ python片段# 旧式(示意):AgentExecutor + 自行处理结构化输出
2from langchain_openai import ChatOpenAI
3from langchain.agents import AgentExecutor, initialize_agent
4from pydantic import BaseModel
5
6class Weather(BaseModel):
7 temperature: float
8 condition: str
9
10llm = ChatOpenAI(model="gpt-4o-mini")
11tools = [get_weather]
12
13agent = initialize_agent(tools, llm, agent="zero-shot-react-description")
14result = agent.run("What's the weather in SF?")
15# 再用正则/二次调用或手写解析把 result 转成 Weather(...)
v1.0 alpha(新写法):一个入口 create_agent,在主循环里直接产出结构化结果(避免多一次 LLM 调用、少走弯路)
1⚡ python片段from langchain.agents import create_agent
2from pydantic import BaseModel
3
4class Weather(BaseModel):
5 temperature: float
6 condition: str
7
8agent = create_agent(
9 "openai:gpt-4o-mini", # 也可传入已实例化 model
10 tools=[get_weather],
11 response_format=Weather # 结构化输出内建
12)
13out = agent.invoke({"messages": [{"role": "user", "content": "Weather in SF?"}]})
14print(out["structured_response"]) # -> Weather(...)
2.“跨厂商、多模态/推理/引用” 的消息处理
v0.x:不同厂商字段名不同(如 reasoning、thinking、citations、server tool 等),常见一堆 if provider == … 的分支。
v1.0 alpha:直接读 .content_blocks(统一、强类型),必要时再序列化回标准块。
1⚡ python片段from langchain_core.messages import AIMessage
2
3msg = some_llm.invoke("Explain with sources & brief reasoning")
4# v1 统一读取:
5for block in msg.content_blocks:
6 if block["type"] == "reasoning":
7 use_reasoning(block["reasoning"])
8 if block["type"] == "text" and "annotations" in block:
9 use_citations(block["annotations"])
3.“工具错误/人审/长对话摘要” 的生产级控制
v0.x:这些能力多靠自写回调或外层控制流拼起来。
v1.0 alpha:内置 Middleware 三钩子(beforemodel / modifymodelrequest / aftermodel)+ 现成中间件(摘要、人审、Anthropic Prompt Caching),还能 “跳转 / 中断”。
1⚡ python片段from langchain.agents import create_agent
2from langchain.agents.middleware import SummarizationMiddleware, HumanInTheLoopMiddleware
3
4agent = create_agent(
5 "openai:gpt-4o",
6 tools=[...],
7 middleware=[
8 SummarizationMiddleware(max_tokens_before_summary=4000),
9 HumanInTheLoopMiddleware(tool_configs={"write_file": {"allow_approve": True}})
10 ],
11)
LangSmith 🦜️⚒️
●解决 LLM 应用开发中最头疼的调试、追踪和评估问题,这是其商业化的核心(收费)。一个应用越复杂,就越离不开 LangSmith,形成用户粘性。
●LangSmith = LLM 应用的 “一体化可观测 + 评测平台”:用来给 Agent / RAG / 多模态应用做 全链路追踪(Tracing)、 离 / 在线评测(Evals)、 监控告警、 成本与时延看板、Prompt 协作等;既可配合 LangChain / LangGraph,也支持非 LangChain 项目、OTEL 接入。
可以开源免费的 langfuse 替代 LangSmith
LangServe 🦜️🏓
●打通 “最后一公里”,让开发者能一键将用 LangChain 构建的应用 API 化
●LangServe 可以把 LangChain 的 Runnable/Chain 一键暴露成 REST API 的开源库,基于 FastAPI + Pydantic,自带 /invoke、/batch、/stream、/streamlog、/streamevents 等端点、自动推断 I / O Schema、内置 Playground,并可把追踪接到 LangSmith
收费吗?
库本身不收费。但其许可证限制: 不得把 LangServe 作为托管 / 托管式服务提供给第三方(SaaS)。也就是说,你可以用它部署自己的应用,但不能把 “LangServe 平台” 卖给其他公司用。另外,LangChain 官方更推荐新项目用 LangGraph Platform(LangServe 只接受社区 bug 修,不再收新特性)。如果要 “托管式平台”,那是另一条产品线(付费)
LangChain 的使用争议
关于 LangChain 最开始的时候是一片盛赞,几乎全是正面评价,但随着开发者使用的深入,不断有负面评价出现。
LangChain 在使用上的主要争议,或者说让开发者后来“抛弃” 它的主要原因有:
1.API 频繁改、文档滞后,维护成本高
○2023–2025 年间最常见吐槽:接口 / 导入路径经常变、语义化版本执行不严、文档跟不上,导致线上项目要反复改代码与迁移;社区讨论与帖子里这一点重复被提及。官方后来在 0.2 才引入 “版本化文档”以缓解这个痛点。Reddit
2.抽象层过重/“抽象泄漏”
○本来想简化 LLM 应用,但 层层抽象(Chains/Agents/Memory/Tools…) 让简单事变复杂;当跨供应商(OpenAI/Anthropic)或多模态/工具调用时,还是要理解底层差异并写分支, 抽象并未完全 “挡住细节”,很多人因此更倾向 “直接调 API / 自己拼装”。
3.性能 / 成本开销与 “隐形调用”
○经验帖里常见:token 使用低效、默认批量/重试/校验带来额外请求与延迟;默认设置偏原型友好,不一定适合生产(缓存、批处理、上下文裁剪都要自己细调)。DEV Community
4.调试与可观测性难(不用配套工具时)
○没接追踪时,多层封装中的报错 / 耗时难以定位,“像在雾里调试”;不少团队因此上了自家的可观测或放弃高阶封装。
5.学习曲线与 “过度框架化”
○许多工程团队反映:学习成本与收益不匹配,做简单的 RAG / 工作流时,直接 SDK + 少量自写代码更快可控;把 LangChain 当工具库(utility)用反而更顺。
6.生态分拆、选择困难与 “框架漂移”
○LangChain/ LangGraph/ LangServe/ LangSmith 产品边界不断演进;多数对比文章建议:流程化任务用 LangChain,复杂状态 / 多轮 agent 用 LangGraph—— 很多团队索性选更贴合场景的替代或 “手写”。DEV Community
上面这些点,不是说 LangChain “不能用”,而是在规模化、稳定性要求高的团队里,可预期性 / 可控性往往比 “快速堆组件” 更重要。
负面评价
这里我引用一些具体的负面评价,通过开发者真实的体验和文章来了解一下 LangChain 的问题。
为什么我们不再使用 langchain 来构建我们的AI代理
●来源: https://octomind.dev/blog/why-we-no-longer-use-langchain-for-building-our-ai-agents
●结论:作者最初喜欢 LangChain 因为其丰富组件和易用性,但后来因其抽象复杂、灵活性差而不推荐。
初期为何喜欢使用 LangChain
作者在项目初期选择 LangChain,主要因为它具备以下优点:
●丰富的工具和组件:LangChain 提供了大量现成的模块,能快速搭建 LLM 应用。
●易于集成:框架承诺“让开发者一个下午就能从想法变成可运行代码”,适合原型开发和快速试错。
●人气高、社区活跃:2023 年 LangChain 热度很高,生态完善,容易找到资料和支持。
这些特性让作者在项目早期能专注于业务逻辑,而不用过多关心底层实现细节。
后期为何不再推荐 LangChain
随着项目复杂度提升,作者逐渐发现 LangChain 带来的问题:
1.抽象层级过多,代码复杂
○LangChain 引入了大量抽象(如 Prompt 模板、输出解析器、链等),让简单任务变得繁琐。
○代码难以理解和维护,调试时需要花大量时间研究框架内部逻辑。
2.灵活性不足,难以定制
○框架对底层细节封装过度,开发者很难根据实际需求修改或扩展功能。
○当需求超出 LangChain 设计假设时,反而成为限制,必须“将需求转化为适合 LangChain 的方案”,而不是直接实现业务逻辑。
3.适应快速变化的 AI 领域能力有限
○AI 和 LLM 领域变化极快,LangChain 的抽象和设计难以跟上新技术和新需求。
○框架的“嵌套抽象”导致开发者需要理解庞大的堆栈和内部机制,增加了认知负担。
4.团队协作和维护成本高
○团队成员需要花大量时间理解和调试 LangChain,而不是专注于功能开发。
○框架的复杂性让代码维护变得困难,影响开发效率。
反思与建议
作者认为,虽然 LangChain 在原型阶段有用,但长期来看,直接用基础库(如 OpenAI API)开发更简单、灵活。大多数 LLM 应用只需少量核心组件,无需复杂框架。对于 AI Agent 等复杂场景,建议在 Agent 模式成熟前保持简单,避免过度依赖抽象。
“一旦我们删除了它,我们就不再需要将我们的需求转化为适合 LangChain 的解决方案。我们只需编写代码即可。”
作者的经历体现了技术选型中“早期便利 vs. 长期灵活性”的权衡,也反映了 AI 应用开发领域对“抽象与简单”的持续思考。
2025 年了,LangChain 还是个无底洞。
https://www.reddit.com/r/LocalLLaMA/comments/1iudao8/langchainisstillarabbitholein_2025/?tl=zh-hans
给研发团队的建议
●“轻 LangChain”:保留少量 LCEL/Runnable 原语(或只用部分解析 / 工具封装),核心链路直接用供应商 SDK 实现,减少抽象层。
●“换轨到 LangGraph”:涉及复杂状态/长对话/人审/错误恢复的 agent,改用图式运行时(LangGraph / 其他工作流框架)。
●“专用 RAG 框架 / 自研”:检索、重排、结构化输出走 LlamaIndex / 自研管线
总之,手写代码是一条自主可控的道路,而梭哈 LangChain 可能会是一条不归路。