给 AI 用的搜索引擎
“给 AI 用的搜索引擎” 是一个专门为软件程序(尤其是人工智能模型)设计的接口,让它们能够以编程方式请求、接收和理解来自网络的信息。
为什么 AI 需要这样的搜索引擎?
大型语言模型(如 GPT、Gemini 等)本身非常强大,但它们存在一些固有局限。搜索引擎是克服这些局限性的关键工具。
1.克服 “知识截止日期”
○问题:AI 模型的知识不是实时的。它的知识被 “冻结” 在它训练数据截止的那个时间点。例如,一个在 2023 年训练的模型不知道 2024 年发生的新闻。
○解决方案:当被问及一个新事件时,AI 可以使用搜索引擎 API 查询最新的新闻和信息,然后根据这些实时信息来生成答案。
○例子:你问 AI:“昨天的股市收盘价是多少?” AI 无法直接回答,但它可以调用一个金融搜索引擎 API,获取数据后再告诉你。
2.提高事实准确性,减少 “幻觉”
○问题:AI 有时会 “一本正经地胡说八道”,即编造一些看似合理但实际上是错误的信息,这被称为 “幻觉” (Hallucination)。
○解决方案:在回答需要精确事实的问题时,AI 可以先通过搜索引擎进行事实核查。它将搜索到的可靠来源(如维基百科、官方新闻稿)作为其回答的基础,而不是凭空捏造。
○例子:你问 AI:“X 公司的 CEO 是谁?” AI 不会直接猜测,而是会先搜索 “X company CEO”,找到官方信息后再给出准确答案。
3.提供信息来源和可信度
○通过搜索引擎,AI 不仅能给出答案,还能提供它获取信息的来源链接。这大大增强了答案的可信度,也允许用户自行验证。证许多现代的 AI 问答产品(如 Perplexity AI, Google’s Gemini)都会在回答下方附上参考链接。
4.执行需要实时数据的复杂任务
○问题:许多现实世界的任务依赖于动态变化的信息。
○解决方案:AI 代理 (AI Agent) 可以利用搜索引擎来完成任务。
○例子:一个 “旅行规划 AI” 需要查询实时的航班价格、酒店空房情况、目的地天气预报等。它会通过调用多个不同的搜索服务 API 来收集所有这些信息,然后为你制定一个完整的旅行计划。
“给 AI 用的搜索引擎” 本质上是将互联网从一个为人类视觉设计的、非结构化的信息海洋,转变成一个为机器准备的、结构化的、可查询的知识库。它赋予了 AI 模型一双能 “看到” 并 “理解” 当前世界的眼睛,使其能够突破自身训练数据的限制,变得更加准确、实时、可信和强大。
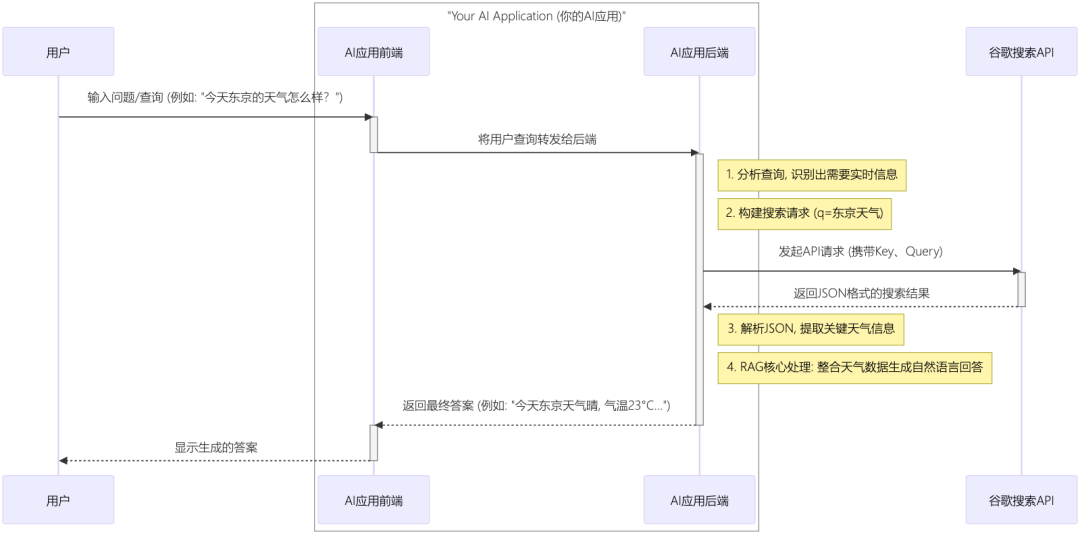
流程示意
以下为一个 AI 应用 Action 的示意图:
供应商
提供 web search 能力的供应商有很多,我们选择了几家知名和流行的厂商作为选型参考:
●Tavily :https://www.tavily.com/
●SerpApi:https://serpapi.com/
●Serper API:https://serper.dev/
●Exa.ai:https://exa.ai/
●Ollama Web Search:https://docs.ollama.com/capabilities/web-search
●Jina.ai DeepSearch:https://jina.ai/deepsearch/
●Brave Search:https://brave.com/search/api/
Tavily
Tavily 是一个面向 LLM 与 AI 智能体的 “Web 接入层”—— 提供实时网络搜索与内容提取的 API,常用于 RAG(检索增强生成)和各类智能体工作流,目标是把 “上网检索→抓取→清洗→结构化” 的繁琐流程封装成简单、可控的接口。
核心 API
●Search:发送查询;可调搜索深度、时间范围、域名白/黑名单等,返回已清理的相关片段与链接,并可选生成简短回答/返回图片结果。
●Extract:按给定 URL 抽取网页全文(可选 Markdown 或纯文本,也可返回图片),便于直接供模型使用。
●Crawl:图式并行爬取整站(带内置抽取与智能发现),适合做站点级信息收集。
●Map(Beta):生成站点地图/URL 列表,可设置深度、广度及路径/域名过滤。
适用场景与优势
●给 RAG、聊天助手、数据富集等提供实时、可追溯的外部信息;返回结果强调带来源引用与面向 LLM 的片段,以降低幻觉并提升可审计性
●官方定位是 “为智能体提供上网能力的基础层”,强调速度、稳定性与与开发者 / 智能体工作流的适配。
生态与集成
提供官方 Python/JavaScript SDK 与在线 Playground;并与 LangChain、LlamaIndex 等框架集成,便于直接接入现有 Agent / RAG 管道。
接入示例:
1⚡ python片段"""
2Tavily Search API - 超简洁版
3"""
4
5import os
6from dotenv import load_dotenv
7from tavily import TavilyClient
8
9load_dotenv()
10
11# 创建客户端
12client = TavilyClient(api_key=os.getenv("TAVILY_API_KEY"))
13
14# 搜索
15query = input("搜索: ")
16response = client.search(query=query)
17
18# 打印结果
19print(response)
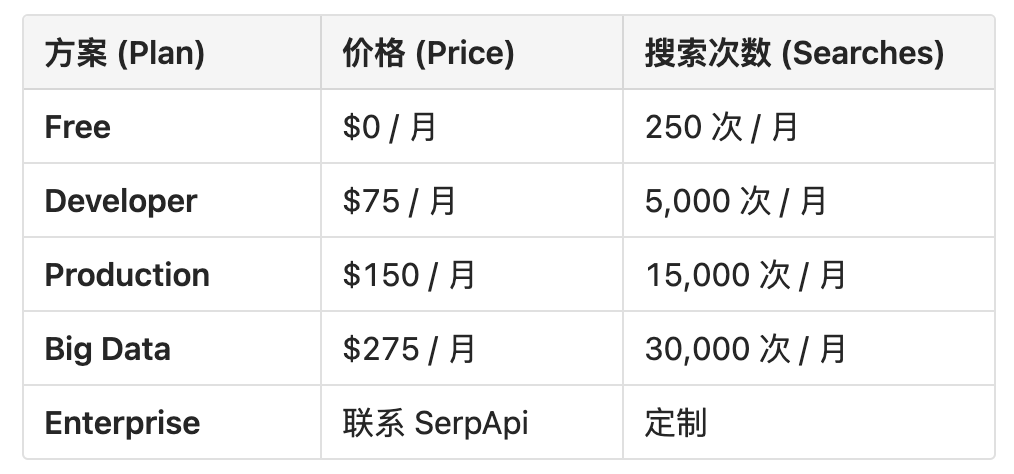
价格与配额
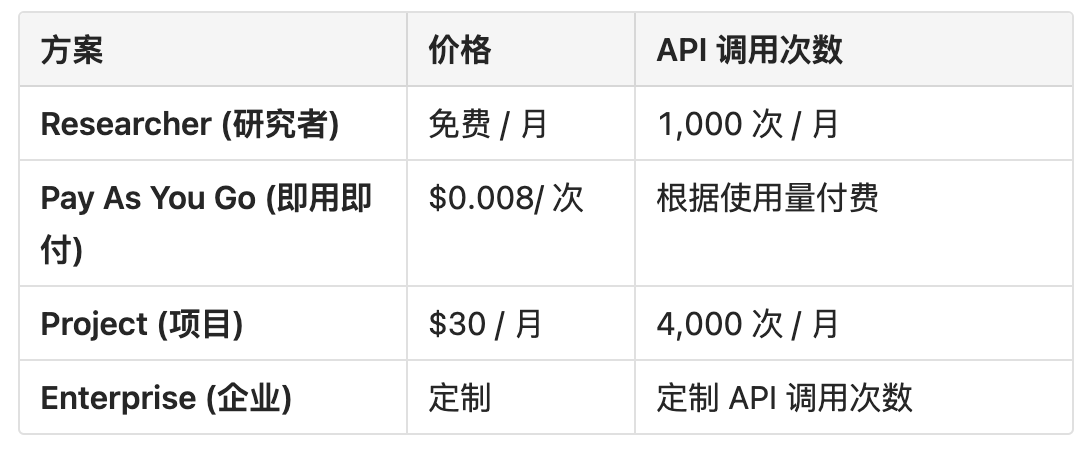
SerpApi
SerpApi 是一个付费的第三方 API 服务,它能让你实时地抓取并解析来自 Google、Bing、Baidu 等多个主流搜索引擎的搜索结果页面(SERP),并以结构化的 JSON 格式返回给你。
你可以把它理解成一个 “超级加强版” 的、非官方的搜索引擎 API。它解决的核心问题是:官方的 Google API 返回的结果有限且不完整,而自己去抓取(Scrape)Google 又极其困难。 SerpApi 就是填补这个鸿沟的商业解决方案。
可以看到它的 API 还是很丰富的:
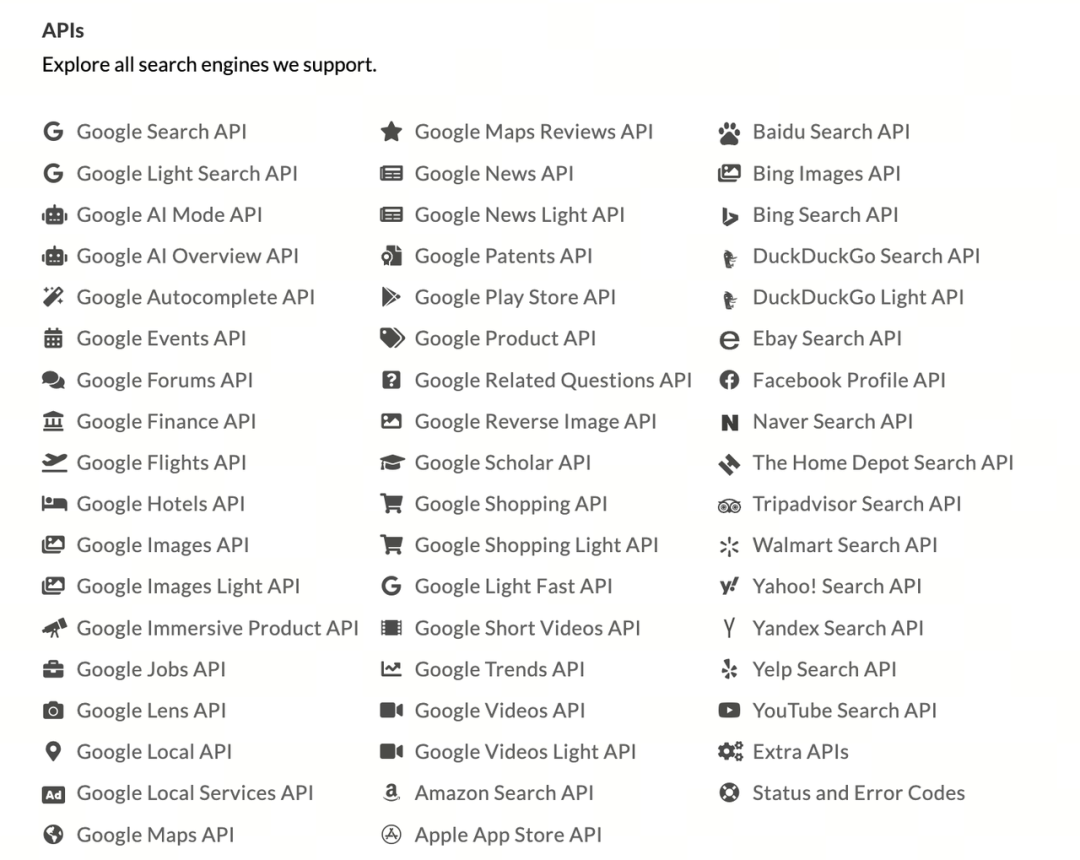
SerpApi 和 Tavily AI 都是服务于 AI 应用的搜索 API,但它们在哲学、目标和返回内容上有着根本性的不同。用一个简单的比喻来开始:
●SerpApi 像是给了你的 AI 一整箱乐高积木的原始零件。它提供了关于搜索结果页面的所有原始、详细、未经处理的数据。
●Tavily AI 像是给了你的 AI 一个根据说明书预先拼好了大半的乐高模型。它为你完成了搜索、筛选、阅读和总结的步骤,直接提供给 AI 一个接近最终答案的、简洁的信息包。
核心 API
SerpApi 的核心是一个简单而强大的 REST API,其本质是 “搜索结果页面即服务” (SERP as a Service) 。
●工作机制: 你通过一个标准的 GET 请求,向 SerpApi 的端点(Endpoint)发送查询,它会返回一个结构化的 JSON 对象,该对象完整地描述了真实搜索引擎的结果页面。
●关键参数:
○api_key: (必需) 用于账户认证的密钥。
○engine: (必需) 指定要查询的搜索引擎。这是其强大功能的体现,例如 google, Maps, google_jobs, bing, baidu, duckduckgo, youtube, amazon 等。
○q: (必需) 你要搜索的关键词。
○location: (可选, 但非常重要) 模拟搜索的地理位置。你可以传递一个具体的城市名、国家,甚至精确的地理坐标,来获取高度本地化的结果。例如,你可以轻松模拟一出来自东京涩谷的搜索请求。
○gl & hl: 分别指定搜索的国家(geolocation)和语言(host language),例如 gl=jp 和 hl=ja 来获取日本的日语结果。
○start, num: 用于翻页,控制搜索结果的偏移量和数量。
●核心产出: API 的输出是其最核心的价值 —— 一个经过深度解析的、结构化的 JSON。这个 JSON 不仅包含自然搜索结果(蓝链),还精确地解析了页面上几乎所有的动态元素,包括:
○广告 (Ads)
○知识图谱 (Knowledge Graph)
○本地包 / 地图包 (Local Pack)
○相关问题 (People Also Ask)
○购物结果 (Shopping Results)
○图片和视频轮播 (Carousels)
适用场景与优势
SerpApi 的价值在于它为需要高质量、真实搜索引擎数据的用户解决了最棘手的技术难题。
●适用场景:
○SEO / SEM 行业: 监控关键词排名、跟踪竞争对手的广告投放策略、分析 SERP 页面特性。
○市场研究与商业智能: 聚合来自 Google Shopping 或 Amazon 的商品价格、分析特定行业的市场趋势、监控品牌在网络上的提及。
○AI 与大语言模型 (LLM): 作为 AI Agent 的 “眼睛”,为其提供高质量、实时的外部世界信息源,用于需要完整页面上下文的 RAG(检索增强生成)系统或事实核查。
○本地化服务: 验证本地商家的地图排名、聚合特定区域的服务信息。
●核心优势:
○数据的完整性与真实性: 最大的优势。它提供的是真实用户所见的完整页面镜像,而非官方 API 提供的阉割版数据。
○规避所有抓取障碍: 用户无需担心 IP 封锁、代理管理、浏览器指纹以及最令人头疼的 CAPTCHA(人机验证)。SerpApi 在后端完全处理了这些问题。
○强大的本地化和定制能力: location 参数功能强大,可以实现全球任意地点的精准模拟搜索。
○广泛的平台支持: 一个 API 接口即可访问全球几十个主流的搜索引擎和电商平台。
生态与集成
SerpApi 非常注重开发者体验,已经建立了一个成熟的生态系统,使其能够轻松地集成到现有工作流中。
●官方编程语言库: 提供了对主流语言的官方支持,包括 Python, Node.js, Ruby, Java, PHP, Go, C# 等。这使得开发者可以在几分钟内就开始调用 API,而无需手动构建 HTTP 请求。
●与 AI 框架的深度集成: 在当前的 AI 浪潮中,SerpApi 已成为标准工具之一。它被深度集成到 LangChain 和 LlamaIndex 等主流 AI 开发框架中,通常作为一个开箱即用的 Tool 或 Wrapper 存在,方便 AI Agent 直接调用。
●无代码 / 低代码平台集成: 支持 Zapier, Make (原 Integromat) 等自动化平台,让非程序员也能利用其强大的数据抓取能力来构建自动化流程。
●完善的文档与工具: 提供了交互式的 API 文档(Playground),用户可以在网页上直接测试各种参数组合,并实时查看返回的 JSON 结果,极大地降低了学习和调试成本。
接入示例:
1⚡ python片段"""
2SerpApi Search API - 超简洁版
3Google 搜索引擎爬取 API
4"""
5
6import os
7from dotenv import load_dotenv
8from serpapi import GoogleSearch # type: ignore[import-untyped]
9
10load_dotenv()
11
12# 创建搜索参数
13query = input("搜索: ")
14params = {
15 "q": query,
16 "api_key": os.getenv("SERPAPI_API_KEY"),
17 "num": 5, # 返回 5 条结果
18}
19
20# 执行搜索
21search = GoogleSearch(params)
22results = search.get_dict()
23
24# 打印结果
25print(f"\n🔍 搜索结果: {query}\n")
26print("=" * 60)
27
28# 显示有机搜索结果
29organic_results = results.get("organic_results", [])
30for idx, result in enumerate(organic_results, 1):
31 print(f"\n【{idx}】 {result.get('title', '无标题')}")
32 print(f"🔗 {result.get('link', '')}")
33 print(f"📝 {result.get('snippet', '无描述')}")
34
35print("\n" + "=" * 60)
36print(f"✅ 共找到 {len(organic_results)} 条结果")
价格与配额
Serper
Serper.dev 在搜索引擎 API 市场中扮演了一个非常独特的、具有破坏性的角色。你可以将 Serper.dev 理解为一个主打极致速度和极具竞争力的低廉价格的挑战者。它专注于做好一件事 —— 提供 Google 搜索结果 —— 并力求比任何竞争对手都更快、更便宜。
Serper.dev 的存在就是为了解决 SerpApi 等传统服务存在的两个痛点:响应慢和价格贵。
1.速度 (Speed): Serper.dev 的首要卖点是其极低的延迟。它通过自建的、高度优化的反向代理和缓存系统,能够在极短时间内返回 Google 的搜索结果。对于需要实时交互的应用(例如,与用户对话的 AI 聊天机器人),这种低延迟是至关重要的。
- 成本效益 (Cost-Effectiveness): 这是它最大的颠覆之处。Serper.dev 的定价策略非常激进,其单位搜索成本远低于 SerpApi。它提供了一个极其慷慨的免费套餐,并且付费套餐的价格也很有吸引力,这使得它对个人开发者、初创公司和需要大规模搜索但预算有限的项目极具诱惑力。
实测下来,Serper确实是最快的。
核心 API
●API 类型: 同样是简单易用的 REST API。
●端点: 主要提供 /search 端点用于网页搜索,以及 /images 等用于图片搜索的特定端点。
●关键参数: 与 SerpApi 非常相似,包括 q (查询), gl (国家), hl (语言), location (地理位置) 等,使其易于上手和迁移。
●核心产出: 返回与 SerpApi 类似、结构清晰的 JSON 对象,其中包含了 Google SERP 的主要元素,如自然结果、广告、知识图谱、相关问题等。
适用场景与优势
●适用场景:
○实时 AI 对话应用: 当 AI 需要在对话中快速查找信息时,Serper 的低延迟可以避免让用户感到明显的等待。
○大规模数据采集: 当项目需要百万级别的搜索量时,Serper 的低成本优势会变得极为显著。
○初创公司和独立开发者: 慷慨的免费套餐和低廉的付费门槛,使其成为验证想法(MVP)和开发早期产品的理想选择。
○任何以 Google 搜索为主要信息源且对成本和速度敏感的应用。
●核心优势:
○快: 无与伦比的响应速度。
○省钱: 极低的单位搜索成本和慷慨的免费额度。
○简单: API 设计直观,专注于核心功能,没有过多复杂选项。
生态与集成
●与 AI 框架的集成: Serper.dev 同样是 LangChain 和 LlamaIndex 生态系统中的一等公民。它作为一个标准的 Tool 或 Wrapper 被广泛支持,许多教程和项目都因其性价比而推荐使用它。
●编程语言支持: 虽然可能没有像 SerpApi 那样提供十几种语言的官方库,但由于其 API 简单,通过任何支持 HTTP 请求的语言(如 Python, Node.js)进行集成都非常容易。
●社区认知度: 在 AI 开发者社区中,Serper.dev 因其出色的性价比而广为人知,并经常被推荐为 SerpApi 的首选替代品。
接入示例:
1⚡ python片段"""
2Serper.dev Search API - 超简洁版
3更快更便宜的 Google 搜索 API
4"""
5
6import os
7import requests # type: ignore[import-untyped]
8from dotenv import load_dotenv
9
10load_dotenv()
11
12# API 配置
13API_KEY = os.getenv("SERPER_API_KEY")
14API_URL = "https://google.serper.dev/search"
15
16# 搜索
17query = input("搜索: ")
18response = requests.post(
19 API_URL,
20 headers={"X-API-KEY": API_KEY, "Content-Type": "application/json"},
21 json={"q": query, "num": 5},
22)
23
24results = response.json()
25
26# 打印结果
27print(f"\n🔍 搜索结果: {query}\n")
28print("=" * 60)
29
30for idx, result in enumerate(results.get("organic", []), 1):
31 print(f"\n【{idx}】 {result.get('title', '无标题')}")
32 print(f"🔗 {result.get('link', '')}")
33 print(f"📝 {result.get('snippet', '无描述')}")
34
35print("\n" + "=" * 60)
36print(f"✅ 共找到 {len(results.get('organic', []))} 条结果")
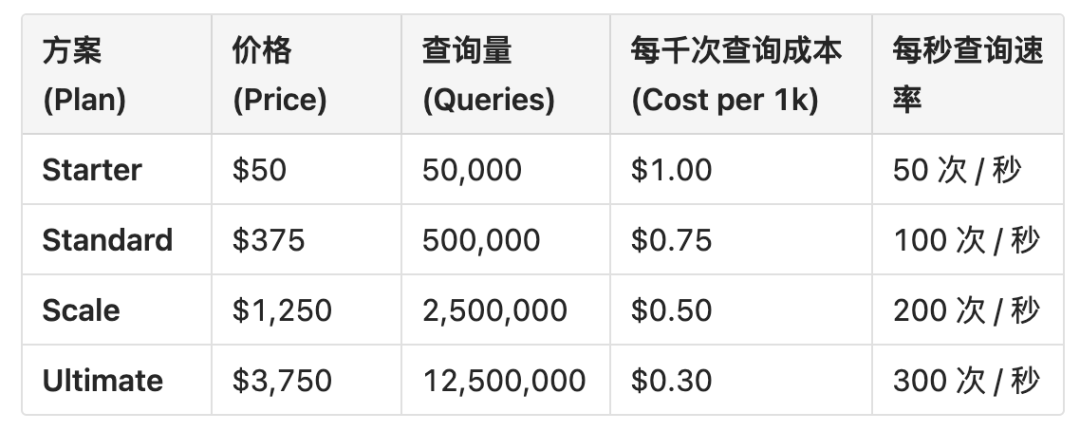
价格与配额
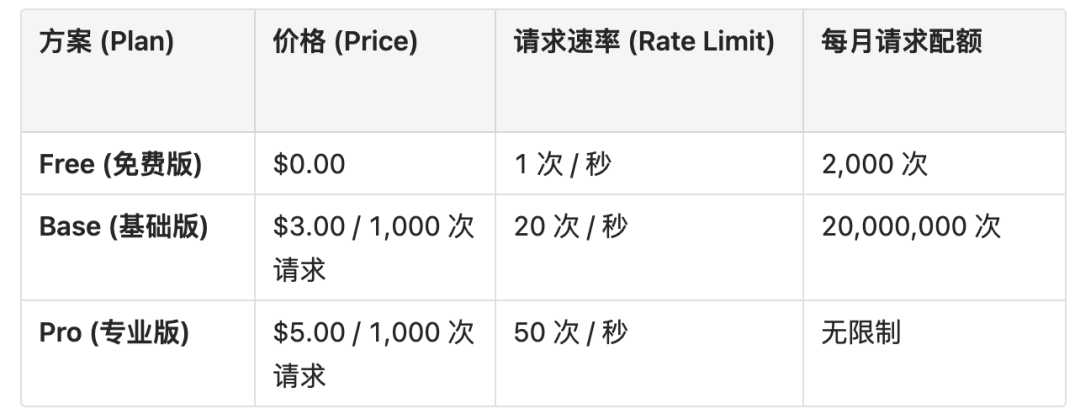
这是 Serper.dev 最闪亮的标签。
●免费套餐: 提供每月 2,500 次的免费搜索,足以满足大多数个人项目和小型应用的开发与测试需求。
●付费模式: 订阅制。其付费套餐的性价比极高,例如,每月支付少量费用(例如 10 美元)就可以获得数万次的搜索量,这个数量在 SerpApi 上可能需要花费高出数倍甚至一个数量级的费用。
●定价哲学: 薄利多销。通过低价吸引大量用户,尤其是在 AI 应用爆发增长的背景下,这种策略非常成功。
Exa.ai
如果我们说 SerpApi / Serper 是对传统关键词搜索引擎的 “API 化”,Tavily 是为 AI “优化答案”,那么 Exa.ai (其前身为 Metaphor) 则是一种完全不同类型的搜索引擎。它不是一个传统的 “关键词搜索引擎” 的 API 封装,而是一个为 AI 和大型语言模型 (LLM) 从头构建的 “神经搜索引擎” 或 “概念搜索引擎”。
核心理念:搜索 “概念”,而非 “关键词”
Exa.ai 最根本的不同在于它的搜索方式。它不依赖于你输入精确的关键词,而是让你用自然语言描述你想要找的 “那种” 内容。Exa 的底层是一个大型的 Transformer 模型,它被训练来理解网页内容之间的关系和 “意义”,而不是仅仅索引它们的文字。
举个例子来理解这种差异:
●传统关键词搜索 (SerpApi/Serper/Tavily): 你想找一些关于日本小众旅行地的深度文章,你可能会输入关键词:“日本 深度游 博客” 或 “Japan hidden gems travel blog”。
○返回的结果会是那些包含了这些关键词的页面,质量良莠不齐。
●Exa.ai 概念搜索: 你可以直接告诉它你的意图: “请给我找一些关于日本旅行的、写得像诗一样优美的个人博客,内容要侧重于当地文化体验,而不是热门旅游景点。”
○Exa 会理解 “诗一样优美”、“侧重文化体验”、“非热门景点” 这些抽象概念,然后返回那些在内容和风格上与你的描述相匹配的链接,即使这些页面中根本没有出现你用到的描述词。
Exa.ai 不是用来替代 Google 搜索的,而是为需要进行深度研究、发现和内容探索的 AI 系统提供了一种全新的、更强大的工具。如果说 SerpApi / Serper 是给了 AI 一张 “地图”,Tavily 是给了 AI 一个 “向导”,那么 Exa.ai 则是给了 AI 一个拥有直觉和品味的 “图书管理员” 或 “研究伙伴”。它开启了让 AI 从 “信息检索者” 向 “知识发现者” 转变的可能性。
核心 API
Exa 的 API 设计完全体现了其 “概念驱动” 的哲学,主要有三个强大的端点:
1./search: 核心的搜索功能。接收一个自然语言描述作为查询,返回一个按相关性排序的链接列表。
2./findSimilar: 极具特色的功能。你给它一个 URL,它会返回一串内容和风格上都与这个 URL “相似” 或 “同类” 的其他链接。这对于构建推荐引擎或进行深度研究非常强大。
3./contents: 检索和内容提取功能。你给它一个或多个搜索结果的 ID,它能直接返回这些页面的干净、去除了广告和无关元素的文本内容,可以直接作为上下文喂给 LLM。这相当于集成了搜索和内容抓取两步。
适用场景与优势
●适用场景:
○高级 AI 研究代理 (Agent): 构建能够进行深度、开放式研究的 AI 代理,而不仅仅是查找孤立的事实。
○内容发现与推荐: 帮助用户发现他们可能喜欢但难以用关键词描述的新博客、文章或资源。
○高质量 RAG: 为 RAG 系统寻找特定领域、特定风格或特定深度的高质量信息源,以提升生成内容的质量。
○个人知识管理: 根据一篇你喜欢的文章,发现更多类似的高质量内容来拓展你的知识边界。
●核心优势:
○超越关键词的理解力: 能够理解抽象的意图和概念,找到 “隐藏的宝藏”。
○发现高质量内容: 其模型倾向于发现更高质量、更独特的内容,而不是被 SEO 优化的普通页面。
○独特的 “相似性” 搜索: /findSimilar 功能是独一无二的,开辟了新的应用可能性。
○端到端的内容获取: /contents API 将搜索和内容提取无缝衔接,极大简化了 RAG 流程。
生态与集成
Exa.ai 在 AI 开发者社区中,尤其是在那些探索 Agentic AI 和高级 RAG 的前沿开发者中,声名鹊起。
●AI 框架: 它是 LangChain 和 LlamaIndex 的官方集成工具,被认为是构建复杂研究型 Agent 的首选工具之一。
●社区定位: 它被社区视为一个 “专家级” 工具,用于解决传统搜索引擎无法处理的、更偏向 “探索与发现” 而非 “查找与验证” 的任务。
接入示例:
1⚡ python片段"""
2Exa.ai Search API - 超简洁版
3专为 AI 设计的语义搜索引擎
4"""
5
6import os
7from dotenv import load_dotenv
8from exa_py import Exa # type: ignore
9
10load_dotenv()
11
12# 创建客户端
13client = Exa(api_key=os.getenv("EXA_API_KEY"))
14
15# 搜索
16query = input("搜索: ")
17results = client.search_and_contents(query, num_results=5, text=True)
18
19# 打印结果
20print(f"\n🔍 搜索结果: {query}\n")
21print("=" * 60)
22
23for idx, result in enumerate(results.results, 1):
24 print(f"\n【{idx}】 {result.title}")
25 print(f"🔗 {result.url}")
26 if result.text:
27 snippet = result.text[:200].replace("\n", " ")
28 print(f"📝 {snippet}...")
29
30print("\n" + "=" * 60)
31print(f"✅ 共找到 {len(results.results)} 条结果")
价格与配额
●定价模型: 采用基于用量的定价模式。通常会有一个免费的开发者额度,用于测试和小型项目。
●计费方式: 它的计费可能比其他服务稍复杂,因为它有不同的 API 端点。通常,一次 /search 或 /findSimilar 调用会消耗一定数量的 “API 单元”,而一次 /contents 调用(因为它涉及实际的网页抓取和解析)会消耗更多的 “API 单元”。
●成本考量: 相对于 Serper 这样的低成本关键词搜索,Exa 的单次查询成本更高。它的价值不在于便宜,而在于它能做到其他搜索引擎做不到的事情。
Ollama Web Search
Ollama 公司官方直接提供了一个云端 Web 搜索 API 服务。个人用户完全免费
核心 API
●服务类型: 一个由 Ollama 公司直接运营和维护的托管式 (Managed) REST API。
●核心功能: 接收用户的自然语言查询,访问互联网,并返回相关的搜索结果。Ollama 在后端处理了所有的复杂性,包括选择搜索引擎、处理反爬虫、解析结果等。对用户来说,它是一个单一、可靠的入口。
●简易性: API 的设计极致简约,如您的代码所示,只有一个端点、一种认证方式和一个核心参数,几乎没有学习成本。
适用场景与优势
●适用场景:
○快速原型开发: 开发者可以立刻为他们的应用添加联网搜索功能,而无需注册和配置多个服务。
○Ollama 生态内的应用: 与在本地运行的 Ollama 模型无缝集成,是官方推荐的、最简单的联网方式。
○任何需要简单、免费搜索功能的项目: 由于其易用性和免费特性,它适用于各种轻量级的 AI 聊天、RAG 应用或自动化脚本。
●核心优势:
○极致简化 (Extreme Simplicity): 这是其最大的优势。开发者不再需要 “Ollama + 第三方搜索 API” 的组合,只需要一个 Ollama 账户和 API 密钥,即可搞定一切。
○免费或极低成本: 根据您的信息,免费提供这一点使其在成本上无与伦比。
○无缝的生态集成: 作为官方服务,它能保证与 Ollama 的其他产品(无论是本地运行的开源工具还是未来可能推出的云端服务)达到最完美的兼容性。
○单一供应商: 无需管理多个供应商的账户、API 密钥和账单,降低了管理复杂性。
生态与集成
●核心定位: 它是 Ollama 自身生态系统的官方、原生搜索解决方案。它的主要目标是服务于使用 Ollama 运行模型的广大开发者。
●通用性: 尽管它与 Ollama 生态紧密相连,但从您的代码可以看出,它是一个标准的 REST API,可以被任何应用程序、任何编程语言独立调用,完全不依赖于本地的 Ollama 运行环境。
●未来潜力: 这种模式为 Ollama 未来的发展铺平了道路,例如推出官方托管的 LLM 推理服务,并与此搜索服务打包,提供一站式的 “模型 + 搜索” 解决方案。
接入示例:
1⚡ python片段"""
2Ollama Web Search - 超简洁版
3文档: https://docs.ollama.com/capabilities/web-search
4"""
5
6import os
7import requests
8from dotenv import load_dotenv
9
10load_dotenv()
11
12# API 配置
13api_key = os.getenv("OLLAMA_API_KEY")
14url = "https://ollama.com/api/web_search"
15
16# 搜索
17query = input("搜索: ")
18response = requests.post(
19 url, headers={"Authorization": f"Bearer {api_key}"}, json={"query": query}
20)
21
22# 打印结果
23print(response.json())
价格与配额
●当前模式: 根据您的信息和代码示例,该服务目前是免费提供的。
●可能的未来: 行业内常见的模式是提供一个非常慷慨的免费层级(Free Tier),足以满足绝大多数个人开发者和小型项目的需求。对于超出免费额度的大规模商业应用,未来可能会推出付费的专业版套餐(Pro Tier),提供更高的请求速率限制、更大的请求量和更强的技术支持。
Jina AI DeepSearch
Jina AI 是一家专注于神经搜索(Neural Search)和多模态 AI 的公司,他们的 DeepSearch 服务是其核心产品之一。DeepSearch 与我们之前讨论的 SerpApi、Serper、Tavily,甚至 Exa.ai 都有所不同,它更侧重于语义理解和基于向量嵌入(Embeddings)的内容搜索,而不是简单地抓取关键词或提供预设的答案摘要。
可以将 DeepSearch 理解为一个允许你构建和查询自己的语义搜索引擎的平台。它不仅仅是帮你 “搜索 Google”,更是帮你 “理解和搜索你自己的数据,以及整个网络上与你概念相关的数据”。
Jina AI 的 DeepSearch 代表了搜索引擎的未来方向之一:从基于字符串匹配的 “关键词搜索” 转向基于语义理解和概念匹配的 “神经搜索”。它对于需要构建能够真正 “理解” 用户意图并发现深层相关内容的 AI 应用来说,是一个强大而高级的工具。如果你的项目需要超越传统搜索的语义能力,尤其是在处理非结构化数据、进行深度内容发现和构建智能 RAG 系统时,DeepSearch 是一个非常值得考虑的选择。
核心 API
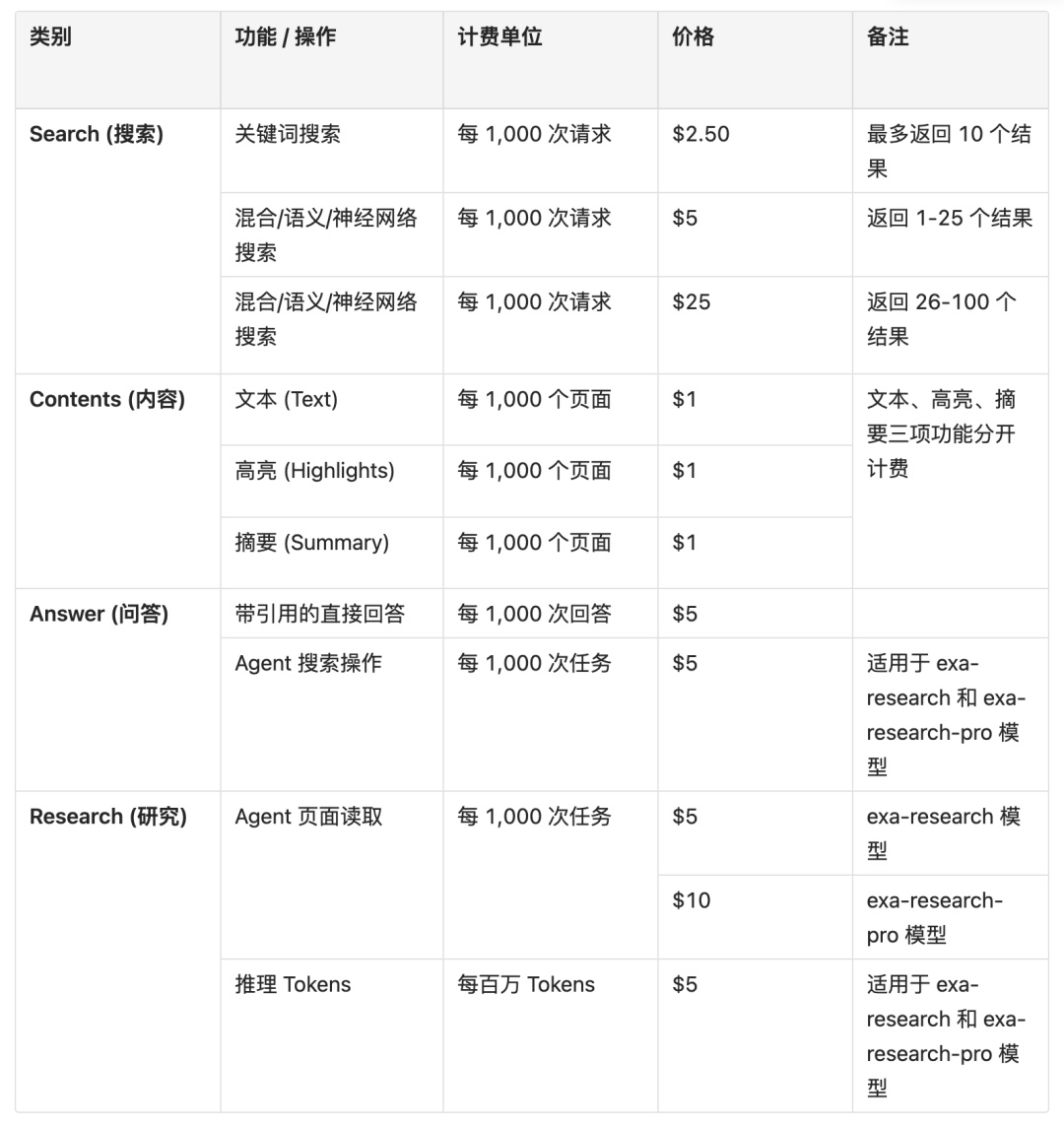
Jina AI DeepSearch 的核心是一个强大的神经搜索 API,其能力基于向量嵌入和语义匹配。
●核心理念: 它不依赖于关键词匹配,而是通过将文本、图像、视频等各种模态的数据转化为高维向量(Embeddings)。当用户发起查询时,查询本身也被转化为向量,然后在大规模的向量数据库中进行语义相似性匹配,找到概念上最相关的内容。
●主要功能:
○语义搜索: 用户可以用自然语言描述其意图或提供一个内容片段(文本、URL),DeepSearch 会返回语义上最相关的内容,即使这些内容不包含任何关键词。
○多模态搜索: 能够处理和搜索不同类型的数据,理论上包括文本、图片、音频、视频等(尽管其网页搜索功能主要集中在文本和图片上)。
○自定义数据集索引: 用户可以将自己的数据(例如公司的文档库、产品目录、内部知识库)上传并索引到 DeepSearch 中,构建一个完全语义化的内部搜索引擎。
○网页抓取与索引: DeepSearch 提供了抓取网页并将其内容向量化的能力。这意味着你可以用它来构建一个基于语义的、针对特定网站或整个网络的索引。
○上下文增强: 返回的不仅仅是链接,通常还会包含抓取到的、与查询相关的页面文本片段,非常适合作为 LLM 的上下文。
●产出: API 会返回一个包含相关结果的列表,每个结果通常包括:原始 URL、页面标题、抓取到的相关文本片段,以及一个表示语义相关性的得分。
适用场景与优势
DeepSearch 的优势在于其深度语义理解能力,使其在传统关键词搜索力不从心的地方大放异彩。
●适用场景:
○高级 RAG 系统: 为 LLM 提供高度相关的、语义化的上下文。当 LLM 需要的不是 “包含这些关键词的页面”,而是 “概念上与此主题最接近的深度分析” 时,DeepSearch 就能发挥作用。
○内部知识库搜索: 企业可以利用它构建一个能够理解员工自然语言提问、并提供最相关内部文档的搜索引擎。
○内容推荐与发现: 基于用户阅读过的内容(URL 或文本),通过语义相似性发现更多高质量、风格或主题相似的内容。
○创新型搜索引擎: 构建更智能、更具洞察力的搜索引擎,例如根据产品描述找到最相似的产品,或根据图片找到相关描述的文本。
○开放域问答: 提供超越关键词匹配的、更智能的答案来源。
●核心优势:
○语义理解: 最核心的优势。它理解查询和内容背后的 “意义”,而非表面的词语。这避免了 “关键词陷阱” 和同义词问题。
○高质量的相关性: 能够发现传统搜索难以找到的、但在概念上高度相关的内容。
○多模态潜力: 为未来处理更复杂的多模态信息奠定基础。
○高度可定制: 允许用户索引自己的数据,构建定制化的神经搜索体验。
○解决 “搜索长尾” 问题: 对于非常具体、小众、难以用关键词描述的查询,其语义匹配能力更强。
生态与集成
Jina AI 在开源社区和 AI 框架中都有很强的存在感,DeepSearch 也受益于此。
●Jina 生态系统: Jina AI 提供了包括 Jina Core (构建神经搜索应用的框架)、DocArray (用于处理多模态数据的库) 等一系列工具。DeepSearch 是这个生态中的一个商业化服务。
●与 LLM 框架集成: 作为先进的搜索解决方案,DeepSearch 也被集成到 LangChain 和 LlamaIndex 等主流的 AI 框架中,作为 Retriever(检索器)或 Tool(工具)使用。
●开发者工具: Jina AI 提供了易于使用的客户端库和详细的文档,方便开发者快速集成其 API。
接入示例:
1⚡ python片段"""
2Jina AI DeepSearch API - 超简洁版
3AI 驱动的深度搜索引擎
4"""
5
6import os
7import requests # type: ignore[import-untyped]
8from dotenv import load_dotenv
9
10load_dotenv()
11
12# API 配置
13API_KEY = os.getenv("JINA_API_KEY")
14API_URL = "https://s.jina.ai/"
15
16# 搜索
17query = input("搜索: ")
18headers = {
19 "Authorization": f"Bearer {API_KEY}",
20 "Accept": "application/json",
21}
22
23response = requests.get(f"{API_URL}{query}", headers=headers)
24results = response.json()
25
26# 打印结果
27print(f"\n🔍 搜索结果: {query}\n")
28print("=" * 60)
29
30data = results.get("data", [])
31for idx, result in enumerate(data[:5], 1):
32 print(f"\n【{idx}】 {result.get('title', '无标题')}")
33 print(f"🔗 {result.get('url', '')}")
34 description = result.get("description", result.get("content", ""))
35 if description:
36 snippet = description[:200].replace("\n", "")
37 print(f"📝 {snippet}...")
38
39print("\n" + "=" * 60)
40print(f"✅ 共找到 {len(data)} 条结果")
价格与配额
相较于关键词抓取服务(如 Serper),或者纯粹的答案摘要服务(如 Tavily),由于其底层的向量嵌入和语义匹配计算成本较高,DeepSearch 的单次查询或数据处理成本可能相对更高。但其提供的是更高的价值和更深层次的语义理解。
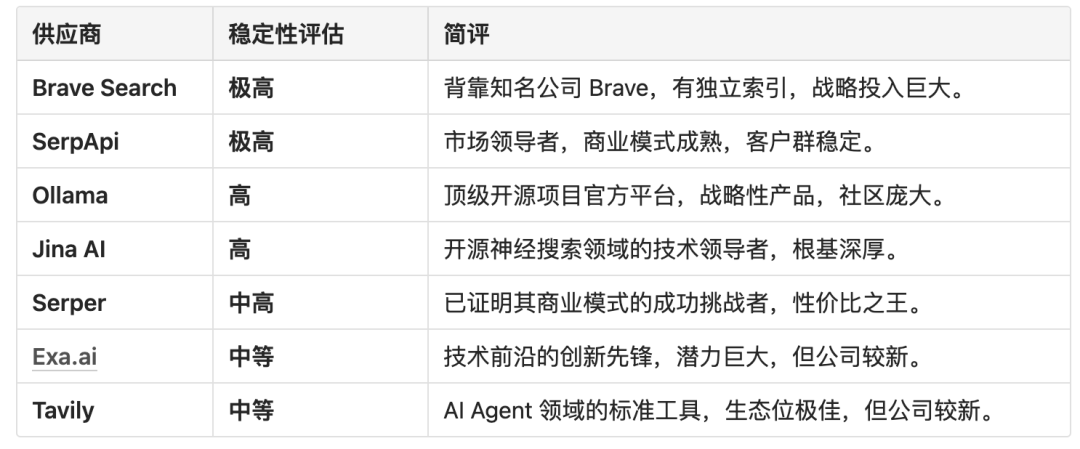
Brave Search
Brave Search 代表了搜索引擎领域中一股独特而强大的力量:真正的独立性。与我们之前讨论的许多依赖于 Google 或 Bing 数据的服务不同,Brave 从头构建了自己独立的网络索引,这使其在市场上独树一帜。
Brave Search 的诞生源于对 Google 和 Bing 在搜索领域双头垄断的担忧。其核心使命是提供一个不依赖于大型科技公司、注重隐私、并能提供无偏见结果的替代品。它的 API 让你能够以编程方式访问这个独特的、独立的索引。
核心 API
https://api-dashboard.search.brave.com/app/documentation/web-search/get-started
●独立索引 (Independent Index): 这是它最核心、最与众不同的特点。当你调用 Brave Search API 时,你查询的是 Brave 自己爬虫和算法构建的数据库,而不是 Google 或 Bing 的 “二手数据”。这意味着你能得到一套可能完全不同的、未经主流引擎过滤的结果。
●Goggles 功能: 这是一个非常独特的创新功能,也通过 API 提供。Goggles 允许用户创建或使用自定义的 “规则集” 来重新排序搜索结果。例如,你可以应用一个 “反科技巨头” 的 Goggle,它会自动降低大型科技公司网站的排名;或者应用一个 “学术优先” 的 Goggle,来优先显示学术论文和研究。
●多类型搜索: API 支持多种搜索类型,包括网页搜索 (web)、新闻搜索 (news)、视频搜索 (videos) 等。
●简洁的 API 设计: API 的端点和参数设计得非常直观,包括 q (查询), country, search_lang 等标准参数,易于开发者上手。
●核心产出: 返回一个干净的、结构化的 JSON 对象,其中包含了各种类型的搜索结果,以及丰富的元数据。
适用场景与优势
选择 Brave Search API 通常是基于对其核心理念的认同,以及对其独特优势的需求。
●适用场景:
○注重隐私的应用: 对于不想将用户数据和查询历史发送给 Google 或 Bing 的应用来说,Brave 是理想选择。
○需要 “第二意见” 的工具: 在研究、分析或事实核查应用中,可以同时调用 Brave API 和其他主流 API,为用户提供一个对比视角,打破 “信息茧房”。
○构建新型 AI Agent: 为 AI 代理提供一个非主流、可能更少偏见的信源,以获得更多样化的观点和信息。
○新闻聚合与分析: 利用其独立的新闻索引来发现可能被主流引擎忽略的报道。
●核心优势:
○真正的独立性: 结果不受 Google 或 Bing 排名算法的影响,提供了真正的多样性。
○隐私保护: 继承了 Brave 浏览器对用户隐私的承诺,API 调用不会被用于用户画像分析。
○无偏见的结果: Brave 声称其排名算法旨在提供最相关、最公正的结果,减少商业化和 SEO 的过度影响。
○创新的 Goggles 功能: 提供了前所未有的结果定制能力,让开发者可以根据特定需求对结果进行重新排序。
生态与集成
作为一个现代化的 API 服务,Brave Search 非常注重开发者生态。
●AI 框架集成: 它被迅速地集成到了 LangChain 和 LlamaIndex 等主流 AI 开发框架中。开发者可以非常轻松地将其作为一个 Tool 或 Retriever 添加到自己的 AI 应用中,这极大地推动了它在 AI 社区的普及。
●易于使用: 作为一个标准的 REST API,它可以被任何编程语言轻松调用。官方文档清晰,API 控制台 (api-dashboard) 直观易用。
●社区支持: 围绕 Brave 的隐私和独立理念,已经形成了一个强大的开发者和用户社区。
接入示例:
1⚡ python片段"""
2Brave Search API - 超简洁版
3独立索引的隐私优先搜索引擎 API
4"""
5
6import os
7import requests # type: ignore[import-untyped]
8from dotenv import load_dotenv
9
10load_dotenv()
11
12# API 配置
13API_KEY = os.getenv("BRAVE_API_KEY")
14API_URL = "https://api.search.brave.com/res/v1/web/search"
15
16if not API_KEY:
17 print("❌ 错误:请设置 BRAVE_API_KEY 环境变量")
18 print("提示:在 .env 文件中添加:BRAVE_API_KEY=your_key_here")
19 exit(1)
20
21# 搜索
22query = input("搜索: ")
23headers = {
24 "Accept": "application/json",
25 "Accept-Encoding": "gzip",
26 "X-Subscription-Token": API_KEY,
27}
28params = {"q": query, "count": 5}
29
30try:
31 response = requests.get(API_URL, headers=headers, params=params)
32 response.raise_for_status()
33 results = response.json()
34except requests.exceptions.RequestException as e:
35 print(f"❌ 请求错误: {e}")
36 ifhasattr(e.response, "text"):
37 print(f"响应: {e.response.text}")
38 exit(1)
39
40# 打印结果
41print(f"\n🔍 搜索结果: {query}\n")
42print("=" * 60)
43
44web_results = results.get("web", {}).get("results", [])
45if not web_results:
46 print("⚠️ 未找到搜索结果")
47 print(f"API 响应: {results}")
48else:
49 for idx, result in enumerate(web_results, 1):
50 print(f"\n【{idx}】 {result.get('title', '无标题')}")
51 print(f"🔗 {result.get('url', '')}")
52 description = result.get("description", "")
53 if description:
54 # 移除 HTML 标签
55 clean_desc = description.replace("<strong>", "").replace("</strong>", "")
56 snippet = clean_desc[:200].replace("\n", "")
57 print(f"📝 {snippet}...")
58
59 print("\n" + "=" * 60)
60 print(f"✅ 共找到 {len(web_results)} 条结果")
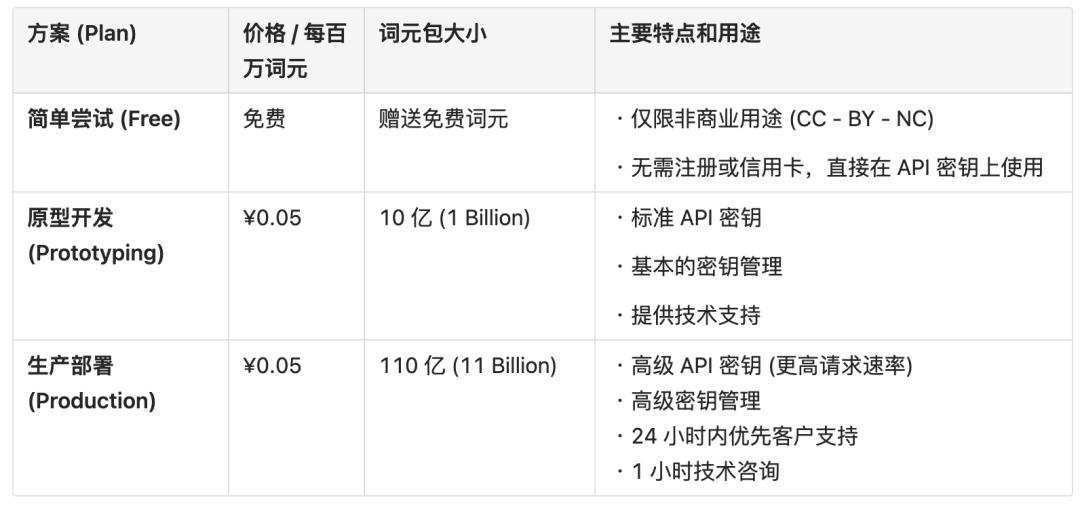
价格与配额
Brave Search API 的定价模型旨在吸引从个人开发者到大型企业的各类用户,具有很强的竞争力。
●免费套餐 (Free Plan): 提供一个非常慷慨的免费层级,通常每月提供多达 2,000 次的免费查询。这足以满足绝大多数个人项目、开发测试和小型应用的需求。
●付费套餐 (Paid Plans): 对于需要更高查询量的用户,提供了多个付费订阅套餐。
○付费套餐的起步价非常亲民(例如,每月几美元即可获得数万次查询)。
○其单位查询成本在整个行业中都非常有竞争力,使其成为 SerpApi 等高端服务的低成本、高质量替代品。
●定价哲学: 通过提供高性价比的服务来鼓励开发者使用其独立的索引,从而挑战现有市场格局,推动一个更开放、更多样化的网络。
其他厂家
还有一些其它的厂商也提供类似服务,比如国内的:
●https://open.bochaai.com/
●https://aisearch.anspire.cn/
选型建议
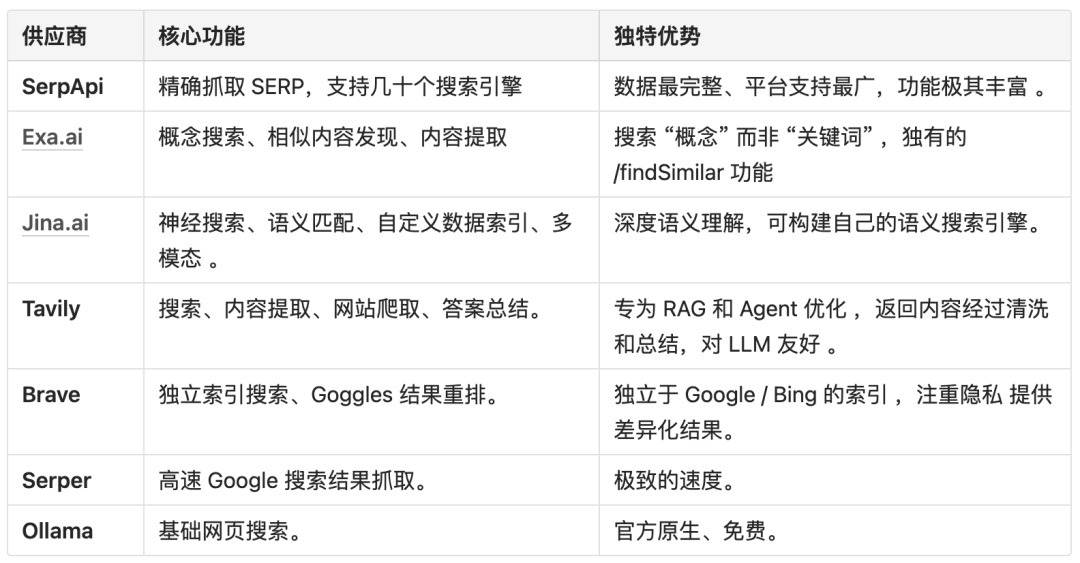
我们快速回顾一下各个供应商的核心定位:
●Tavily: 专为 AI Agent 和 RAG 设计的 “答案层” API,强调对搜索结果的清洗、总结和整合,直接输出对 LLM 友好的内容
●SerpApi: 功能最全面的 “数据层” API,精确抓取并解析 Google、Bing、Baidu 等几十个平台的完整 SERP(搜索结果页面),数据极其丰富
●Serper: SerpApi 的挑战者,主打极致的速度和极低的价格,专注于提供 Google 搜索结果
●Exa.ai: “概念搜索引擎”,使用自然语言描述进行搜索,能理解抽象意图,擅长内容发现和深度研究,而非简单的关键词匹配
●Ollama Web Search: Ollama 官方提供的免费云端 API 服务,极致简化,与 Ollama 生态无缝集成
●Jina.ai DeepSearch: 强大的 “神经搜索引擎”,基于向量嵌入进行语义搜索,支持自定义数据索引和多模
●Brave Search: 建立在独立网络索引之上的搜索引擎,主打隐私保护和不受主流引擎影响的 “第二意见” 结果
综合对比与分析
我们将从响应速度、成本、功能、易用性和适用场景五个维度进行详细对比。
响应速度
经过本地实测,响应速度上 Brave Search 和 SerpApi 是伯仲之间
1⚡ 代码片段======================================================================
2🏆 响应速度排名(从快到慢)
3======================================================================
4🥇 1. SerpApi 627ms
5🥈 2. Brave Search 662ms
6🥉 3. Tavily 976ms
7 4. Serper.dev 1.35s
8 5. Exa.ai 2.29s
9 6. Jina AI 4.66s
10
11======================================================================
成本
成本是选型的关键,我们从业余 / 开发阶段到大规模生产阶段进行考量
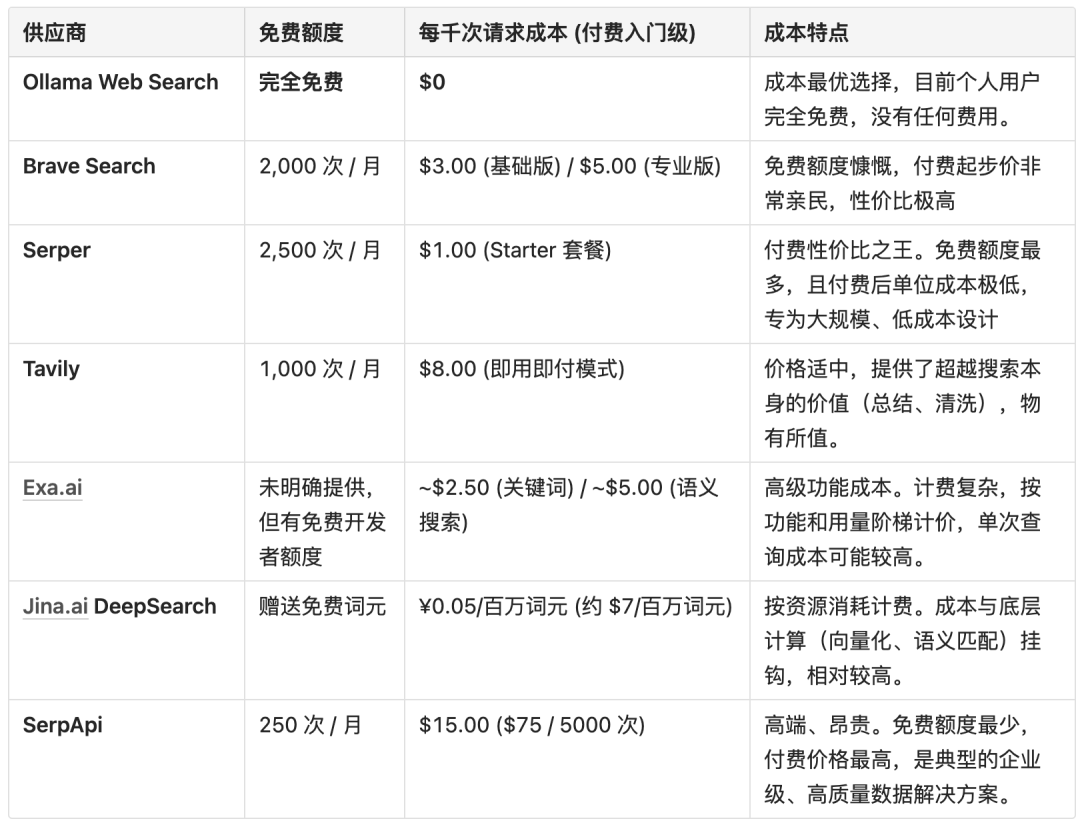
成本排序(从低到高):
Ollama > Serper > Brave > Tavily > Exa.ai > Jina.ai > SerpApi
功能
易用性
●最简单: Ollama Web Search。官方原生,一个 API Key 解决所有问题,无需任何第三方配置 。
●非常简单: Serper, Brave, Tavily。都是标准的 REST API,API 设计直观简洁,且都深度集成了 LangChain 等 AI
●中等: SerpApi。功能非常多,参数复杂,但因为有完善的文档、工具和多语言库,集成也相对顺畅
●较复杂 / 需理解新概念: Exa.ai, Jina.ai。它们引入了新的搜索范式(概念搜索、神经搜索),需要开发者改变传统的 “关键词思维” 才能发挥其最大价值
适用场景
●需要最高性价比、大规模获取 Google 结果: Serper 是不二之选
●快速原型、个人项目或 Ollama 生态内应用: Ollama Web Search 的免费和简易性使其成为首选
●注重隐私、需要独立 / 差异化结果源: Brave Search 是最佳选择。
●构建高质量 RAG 或 AI Agent: Tavily 经过优化的输出能显著提升效果和效率,是此场景的理想选择
●需要完整、真实的 SERP 数据用于 SEO 或市场分析: SerpApi 的数据完整性和多平台支持无可替代。
●需要进行深度研究、内容发现或构建推荐系统: Exa.ai 的概念搜索和相似性搜索能力是独一无二的
●需要构建企业内部的语义知识库或进行高级语义搜索: Jina.ai 的自定义索引和神经搜索能力最为强大
选型建议
综合以上分析,以下是针对不同需求的选型建议:
1.个人开发者 / 初创公司 / 预算极度敏感项目:
○首选:Ollama Web Search。完全免费且极致简单,没有任何理由不优先考虑它
○备选:Serper 或 Brave Search。当 Ollama 不可用或需要更高查询量时,这两者提供了业内最慷慨的免费额度和最低的付费门槛
2.构建标准 RAG 或 AI Agent 应用:
○首选:Tavily。它专为此场景设计,能直接提供清洗和总结后的高质量上下文,有效降低幻觉,节省你自己处理数据的成本和 LLM 的 Token 消耗
○备选:Serper。如果你的 RAG 流程需要自己控制总结逻辑,且对成本和速度要求很高,可以使用 Serper 作为快速的数据获取层
3.专业的 SEO / 市场分析 / 需要多平台数据的企业级应用:
○唯一选择:SerpApi。尽管价格昂贵,但其数据的完整性、真实性以及对全球几十个搜索引擎和电商平台的支持是其他所有服务都无法比拟的
4.探索前沿 AI 应用 / 需要进行深度内容发现和研究:
○首选:Exa.ai。如果你需要 AI 去 “发现” 而不是 “查找”,或者需要基于一篇好文章找到更多同类内容,Exa 的概念搜索和相似性搜索能力是你的不二之选
○备选:Jina.ai DeepSearch。如果你不仅要搜索网络,还想构建一个能理解内部文档的、强大的语义知识库,Jina 提供了更完整的平台级解决方案
另外 ,从风险评估的角度总结来说: