“
测评人: 小盒子(AI 架构仔,Agentic 编程方向,常年被 API 账单搞到头大) 测评时间: 2025 年 11 月 11 日发布后的一周
这波价格战,字节是真不想给同行活路了
说实话,我当时 凌晨 1:47 在公司改那个傻 X 的 Kubernetes 配置。看到新闻推送,火山引擎出了个 豆包编程模型 Doubao-Seed-Code,说性能 SOTA,但这不是重点。
重点是价格。它宣称 综合成本能比业界平均水平低 62.7%,直接是 国内最低价。我当时正在用 cc 搭配 k2,心想:都说最低价,质量怎么样呢?k2 测完了其实还是不如原装的 claude,所以 doubao-seed-code 如果真是质量高价格低的话,多一个选择也是蛮不错的。
以前我们跑一次复杂的 Agentic 任务,特别是涉及多轮 Bug 修复和重构的,Claude Sonnet 4.5 那个账单,每个月看一次疼一次。
我看官方资料里明晃晃地写着,做一个交互式英语学习网站,用 Doubao-Seed-Code 只需要 0.34 元左右,用 Claude Sonnet 4.5 可是要大概 4 块多。 这差距,可以的~
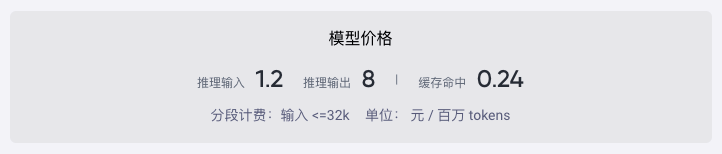
它这个 API 定价,输入 1.20 元/百万 Tokens,输出 8.00 元/百万 Tokens(0-32K 区间),配合那个 Cache 技术,还能再降 80% 的成本。我们现在正在做 Agent 自动化项目,以前成本受限,很多地方要做工程优化,要这样的话,感觉忽然就 经济可行 了。

我立马摸鱼时试了下,冲了它那个 9.9 块首月 的 Coding Plan。一杯咖啡钱,买一个号称 SWE-Bench Verified 榜单上 SOTA 的模型(这个榜单是测 Agent 端到端解决问题的能力,很硬核的)。
兼容 Claude Code
感觉最近这都成了编程模型的标配了哈。
作为 Claude Code 用户,感觉接入不是很丝滑的。Doubao-Seed-Code 原生兼容 Anthropic API ,接入方法还是老套路,很简单:
第一种方式
如果是短期测试,可以直接在终端中配置环境变量,在启动 Claude Code 前输入环境变量
1export ANTHROPIC_BASE_URL=https://ark.cn-beijing.volces.com/api/compatible
2export ANTHROPIC_AUTH_TOKEN=<ARK-API-KEY>
3export ANTHROPIC_MODEL=doubao-seed-code-preview-latest
第二种方式
如果是长期使用,可以直接配置文件
1open -e ~/.claude/settings.json
2
3{
4 "api_key": "xxxxxxx",
5 "api_url": "https://ark.cn-beijing.volces.com/api/compatible",
6 "model": "doubao-seed-code-preview-latest"
7}
说句提外话,最近这几家搞 code 模型的,就是明着抢 Claude 的客户,但我支持,哈哈。
切换零成本 + 价格低 60%+ 性能 SOTA 确实有点儿心动。
核心能力体验
“
长上下文和那个 VLM 才是真杀手锏
光便宜和兼容没用,代码写得烂,那也是浪费我时间。
看了一下上下文,256K,还成,跟 K2 一样,感觉现在没个 256K 都不好拿出手。
虽然 Claude 4.5 Sonnet 的上下文声称是 1M,但实际上只有 200K,而且还死贵。 256 好,还多 56K,哈哈
别小看多出来的这点儿。我手头有个遗留项目,Python 写的,几百个文件,那叫一个乱。模型处理 Bug,有时候上下文 Token 一爆,它就变瞎子了,你得手动 RAG 喂它代码,有时候就差那么一两个文件,逼得我重开个 thread,前面都白费劲了。
Doubao-Seed-Code 多出来的这 56K,意味着它能把 整个中等规模的项目结构和依赖 都装进 “脑子” 里

刚才我让它解决一个跨越十几个文件的逻辑 Bug,以前的模型得来回拉扯五六轮,这次它 一步到位 定位到了问题。而且它不只是修复 Bug,它还会 优化结构,提升代码的可读性和维护性。这才是 Agent 编程,不过客观地讲跟最贵的那位比还是有一定的差距。
VLM:前端仔的末日… 还是福音?
这个视觉理解(VLM)能力, 国内首发。
这个功能并不新鲜,但国内首发,算是跟上了。我现在可以直接把 UI 稿截图,或者 手绘草稿 扔给它。然后它能给你生成对应的代码。
我一开始以为它就是搞了个图转文字,再让 LLM 去生成代码,这种方法信息折损很大。结果 它这个是原生的 VLM 能力,不是靠工具调用。最牛逼的是,它能 自己完成样式修复和 Bug 修复。它生成一个页面,然后拿截图跟你原始的设计稿对比,发现哪里边距不对,哪里颜色溢出了,自己动手改
我当时试了一个复杂的 Dashboard 界面,只给了一张截图,它生成的 React + Tailwind 代码还原度还是非常高的。前端兄弟估计已经麻木了,据我所知,他们自己也在用 vibe coding 干活,哈哈。
聊聊技术底裤
Doubao-Seed-Code 的核心是 Seed-Coder 家族,能 SOTA,说明字节在训练上砸了不少黑科技
官方资料里提了一堆很唬人的词儿, 小盒子来翻译翻译:
“大规模 Agent 强化学习训练系统” :他们好像是搞了一套巨大的 打怪升级系统,专门用来训练代码 Agent。模型不是靠背书(预训练数据)学编程的,它是直接在 沙盒里 跑代码
构建了覆盖 10 万容器镜像的训练数据集”:为了让模型见过各种稀奇古怪的运行环境(比如 Python 3.7 + PyTorch 1.9 + CUDA 10.2),他们准备了 10 万个容器
“万级并发沙盒 session”:几万个容器同时跑。让模型在里面不断试错,错了就 罚站(接收执行反馈)。这样练出来的 Agent,解决问题的鲁棒性才强
这套机制直接解释了为什么它能在 SWE-Bench Verified 这种需要端到端解决问题的测试里登顶。它不是一个静态的知识库,它是个会 思考、会动手、会自我修正 的开发伙伴
顺便提一句,这个 Seed-Coder 还有开源版本。开源的 Seed-Coder-8B-Reasoning 有 64K 上下文,虽然不如商业 API 的 256K 那么猛,但对于个人研究也够用了。
测试
这里我做了一个测试,目的是看它能不能真的理解 “Vibe Coding”(用户描述一个抽象的、高层的需求,让 Agent 去实现),特别是设计稿的还原和自我纠错能力
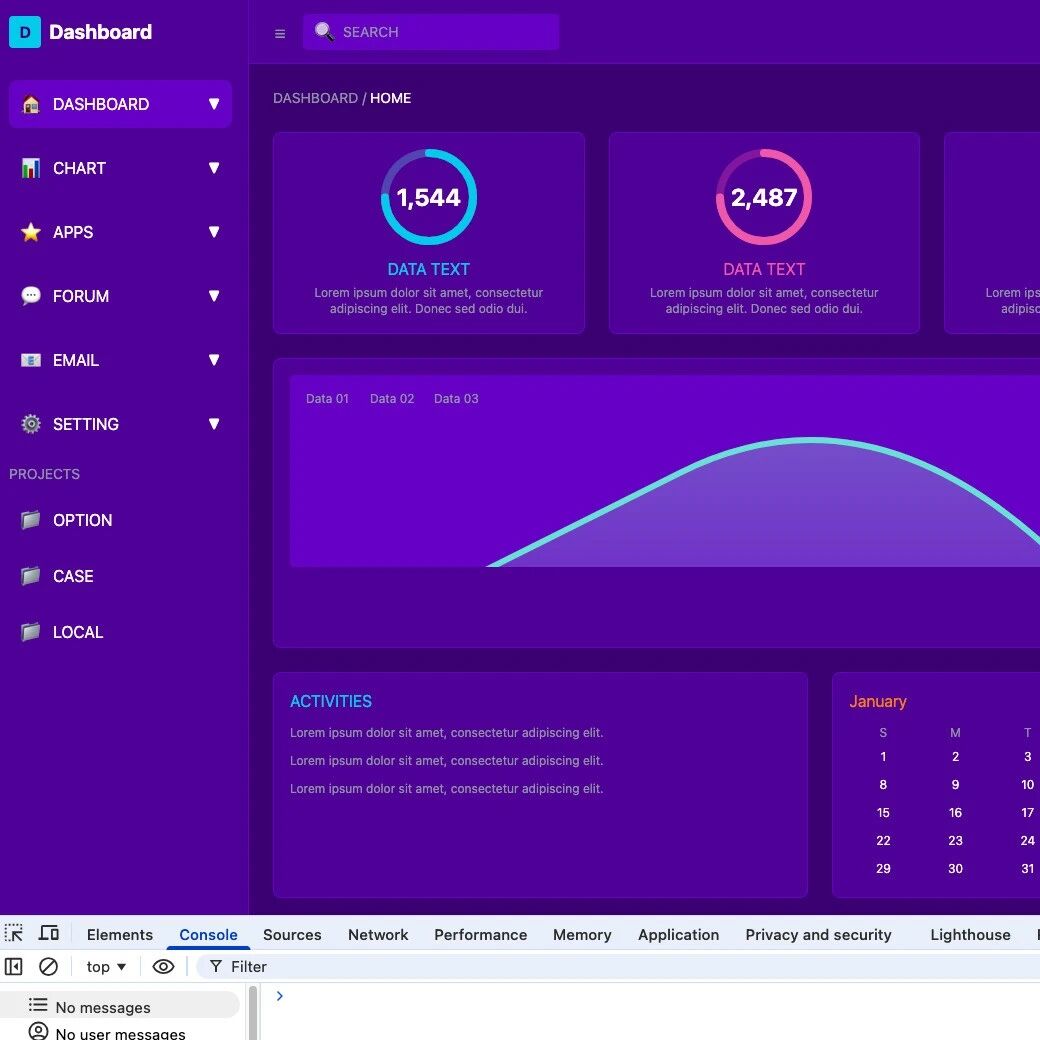
找一个 UI 稿截图,越复杂越好。
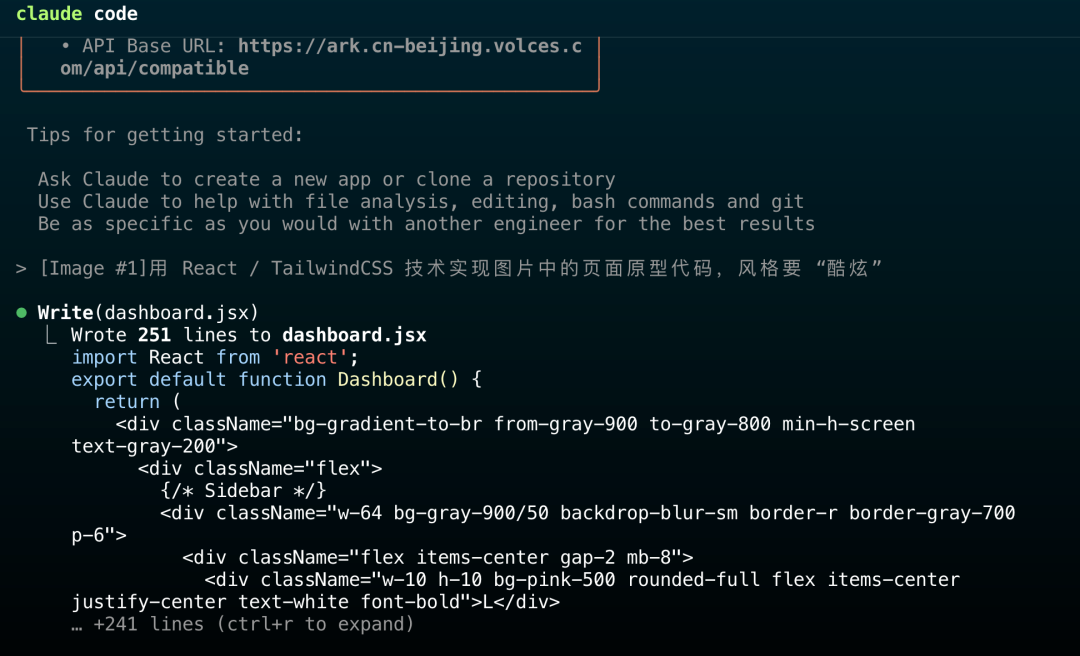
最终生成的效果如下:
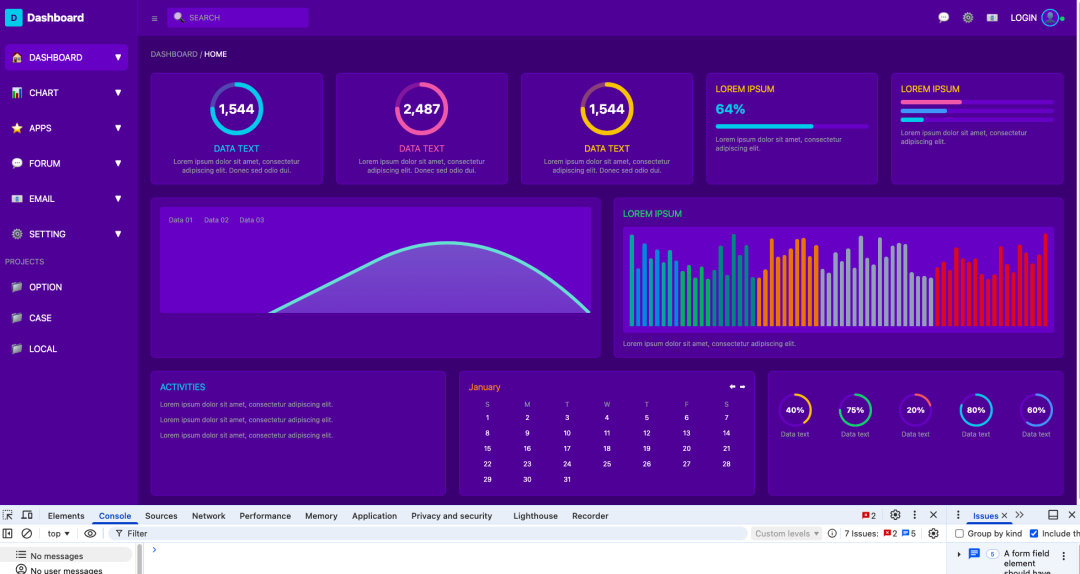
总结
无论最后你是否使用 doubao-seed-code 模型作为你的生产工具,我都推荐你试试,包括 k2 等其他模型,无它,AI 进化的速度很快,先上车!
单纯就 doubao-seed-code 来说,我觉得也还可以:
- 价格摆在那儿,跑 100 次 Agentic 任务的成本,以前可能只能跑 30 次。
- VLM 是未来:前端开发效率的飞跃。
- 256K 上下文:真正能处理企业级复杂重构任务的基础。
Doubao-Seed-Code 这波操作,是想把 AI 编程从 “昂贵的工具” 变成 “水、电、煤” 一样基础设施 。对于追求极致效率和成本控制的团队,值得一试。