一、背景
为什么要搞推理平台
从实用的角度讲,搞推理平台的目的就是为了给部署、运行、维护模型打造一个良好的 “环境”。
为什么要自己部署、运行、维护模型呢? 全部用 API 不行吗?
这个问题涉及到模型的功能分化。简单来讲,传统的 LLM 基座模型是很强,类似全能型选手,但在企业落地场景下并不完全适用。企业需要的是 ROI 极高的方案,企业场景下会考虑并发、延迟、成本等非常具体的指标。所以用满足单一场景且成本极低的小模型 + 基座大模型是比较务实的选择。
一定要有 GPU (显卡资源)吗?
不一定,有些模型在 CPU 也跑的很好。 比如 all-MiniLM-L6-v2,但绝大多数模型是需要 GPU 的。
二、资源规划与集群架构
我们假设你的生产环境是如下图所示的 K8S 集群环境
不止 k8s
对于一个 “模型在线推理平台(Serving 平台)”,光靠 k8s 是不够的。
如果光有 k8s 我们会遇到以下几个问题:
- 资源利用率极低,成本高昂:Kubernetes 的原生调度单位是 Pod。它不理解 “模型” 这个概念,也不知道如何在一张 GPU 上高效地运行多个模型。那就意味着一个模型会独占一张 GPU 卡。中小模型的计算量不大,大部分时间里,这个 Pod 和 GPU 都是空闲的。当模型数量增加时(例如 10 个或 50 个模型),成本会呈线性增长,变得非常昂贵。
- 运维复杂度极高:原生 Kubernetes 缺少一个更高层次的抽象来描述 “模型服务” 这个场景,必须手动组合多个底层资源来完成一个任务(手动编写和维护一套复杂的 Kubernetes YAML 文件(Deployment, Service, HorizontalPodAutoscaler 等)。
- 缺乏标准化的模型服务能力:这些都是应用层的逻辑,原生的 Kubernetes 并不直接提供这些开箱即用的功能
- 如何进行 A / B 测试或金丝雀发布(Canary Rollouts)来平滑升级模型?
- 如何处理模型的预处理和后处理逻辑?
- 如何监控模型的 QPS、延迟、成功率等指标? 可观测性不足(难以按 “模型维度” 看指标)
- 流量高峰时如何自动扩容,没有流量时如何缩容以节省成本?
KServe
“
Standardized Distributed Generative and Predictive AI Inference Platform for Scalable, Multi-Framework Deployment on Kubernetes
为了解决上述问题,社区催生了专门针对 Kubernetes 的模型服务平台,KServe 就是其中的佼佼者。它通过引入一个名为 InferenceService 的自定义资源(CRD)来解决这些问题。
解决资源利用率问题:
模型复用 (Multi-Model Serving):KServe 可以与 NVIDIA Triton Inference Server 或 TorchServe 等高性能推理服务器集成。这些服务器支持在 单个 Pod 和单个 GPU 上加载和运行多个模型。当请求进来时,由推理服务器动态地将计算任务分配给 GPU。这样,多个中小模型就可以共享一张 GPU,极大提高资源利用率。
自动缩容至零 (Scale to Zero):当一个模型在一段时间内没有收到任何请求时,KServe 可以自动将该模型的 Pod 缩减到 0。当新的请求到来时,它又能快速拉起一个新的 Pod 来提供服务。这对于流量不稳定的中小模型来说,是巨大的成本节省。
解决运维复杂度问题:
单一抽象 (InferenceService):不再需要编写 Deployment, Service 等一大堆 YAML。只需要定义一个 InferenceService 对象,在里面声明用的是什么框架(TensorFlow, PyTorch, Triton 等)以及模型的存储路径(如 S3)。KServe 会自动创建和管理所有底层的 Kubernetes 资源。这极大地简化了运维工作。
解决标准化服务能力问题:
开箱即用的高级部署:在 InferenceService 的配置中,只需修改几行代码,就可以轻松实现金丝雀发布。例如,您可以指定将 10% 的流量发送到新模型,90% 的流量发送到旧模型,验证通过后再全量切换。
请求日志、监控指标:KServe 自动提供了标准化的接口和可观测性指标,方便接入 Prometheus、Grafana 等监控系统。
推理图谱 (Inference Graph):对于需要多个模型串联(例如预处理 -> 模型 A -> 后处理 -> 模型 B)的复杂场景,KServe 也提供了标准化的解决方案。

对于 “在 Kubernetes 上部署多个中小模型” 这个场景, KServe 是目前最好、最主流的开源解决方案之一。
直接采用 KServe 将会极大降低成本、简化管理、并提升部署的稳定性和灵活性,让我们可以更专注于模型算法本身,而不是底层的基础设施。
KServe 架构
KServe 架构概览:
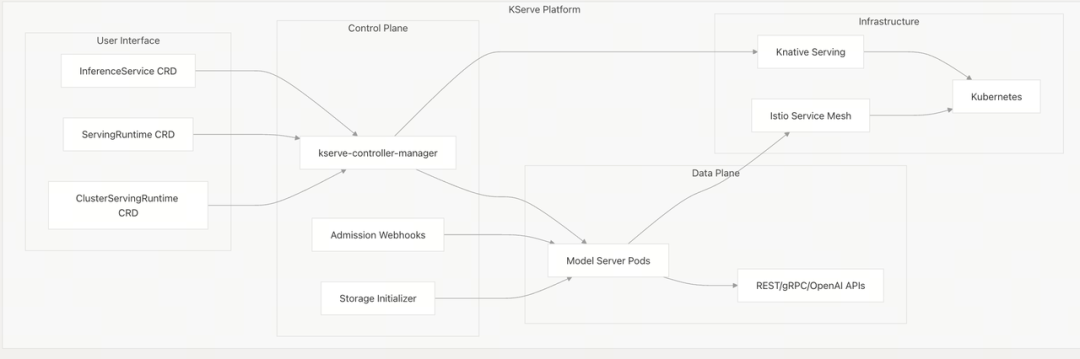
核心架构:
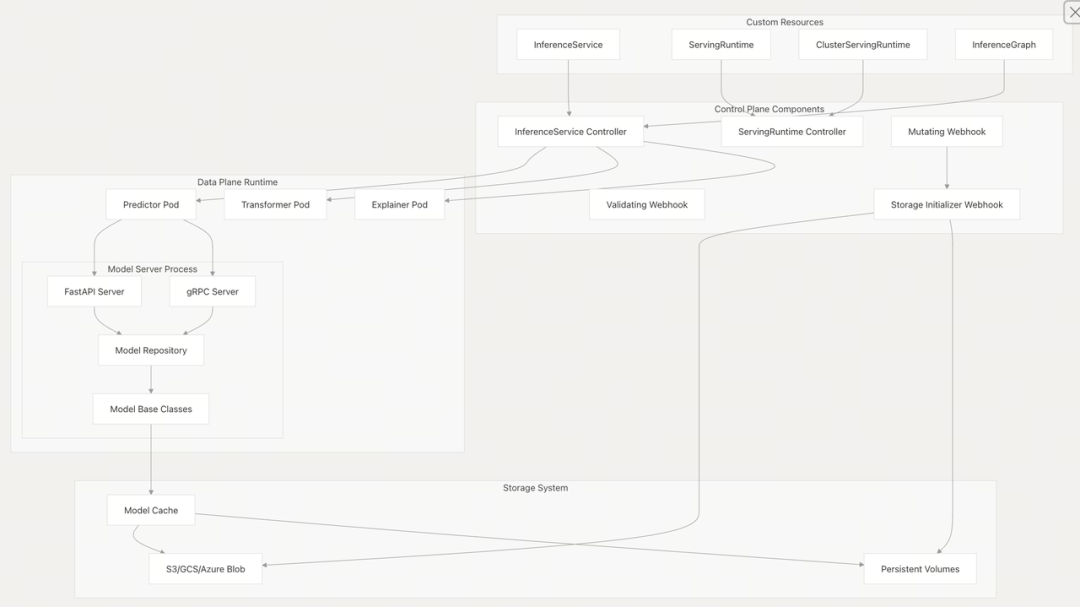
控制面架构:
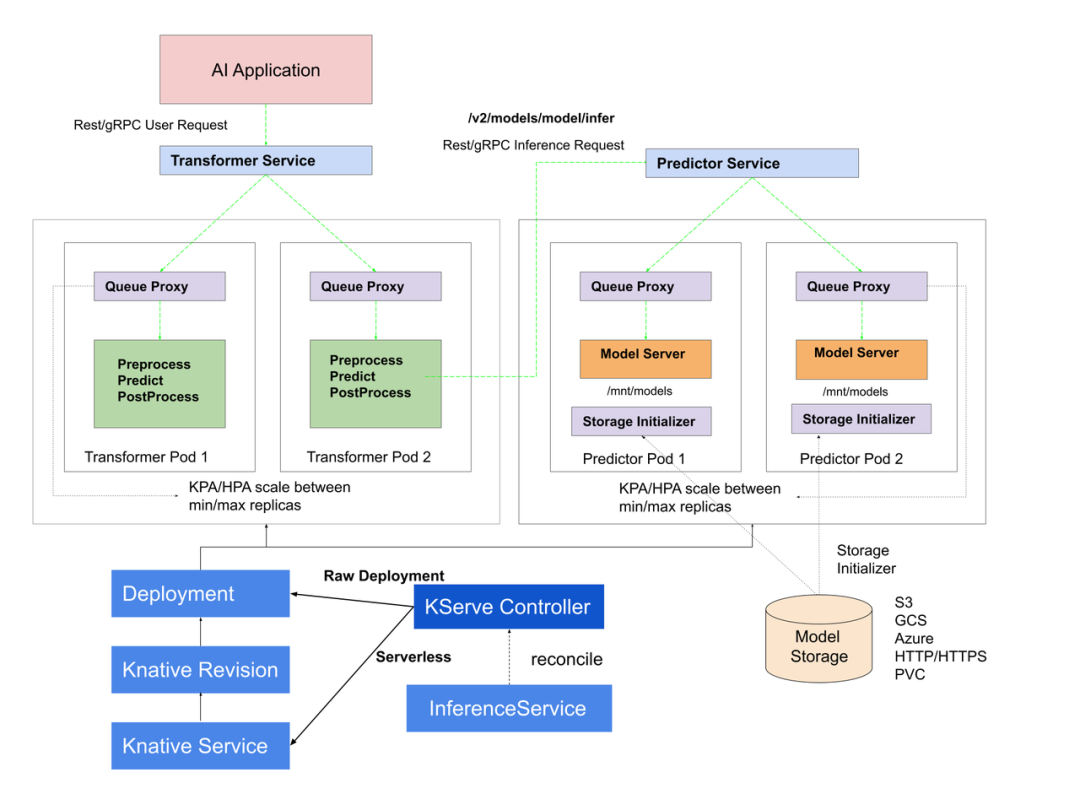
数据面架构:
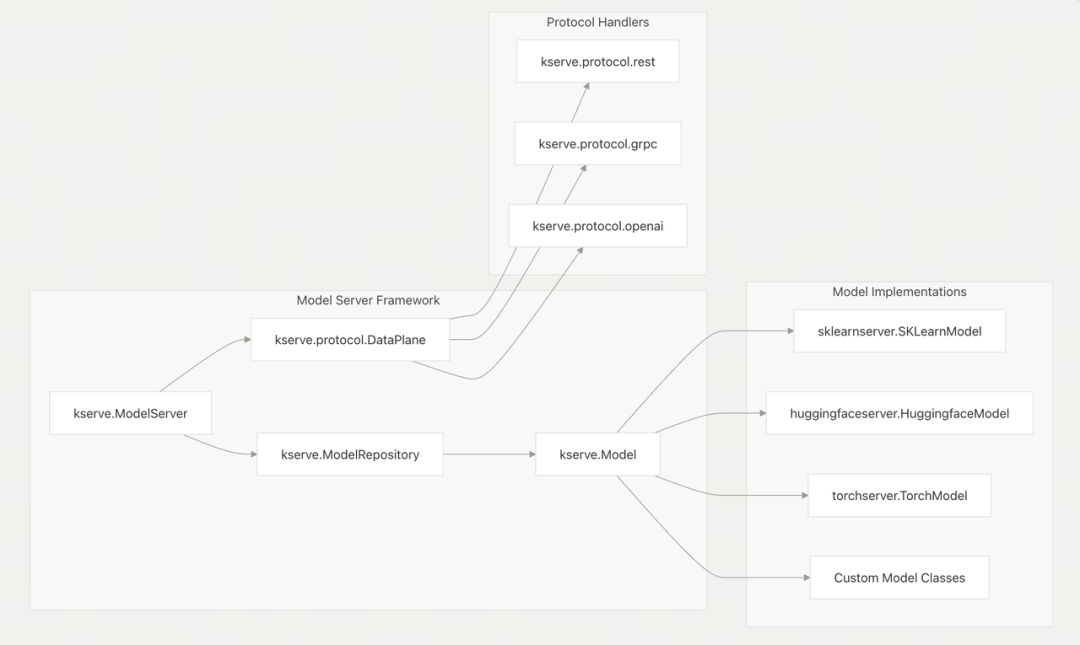
模型 runtime 支持:

vLLM 和 Triton
从 KServe 的运行体系图中可以看到在推理层面,大致有两种最流行的软件,一个是 vLLM,一个是 Triton
- vLLM 是 LLM 专用推理引擎(只跑 Transformer,极快但单一)
- Triton 通用推理平台(CV/NLP/LLM/推荐都能跑,全能但略重)
在 KServe 里,两者的选择就是: “要极速跑 LLM,还是要一车拉所有模型” 。在实践中,KServe 是一个统一平台,可以支持我们按需选引擎,所以不用 all in 其中任何一种,比较灵活、方便。
三、部署思路
架构
结构如下:

这里我们需要解释几个问题
1. 整体链路是谁在做自动扩缩容?
在 KServe + Knative 模式 下,职责大致是:
KServe:
写 InferenceService CRD(YAML)
KServe Controller 把它翻译成一个 Knative Service(和一些 K8s 资源)
同时通过 annotations / 字段把我们希望的 autoscaling 配置写进去
Knative Serving:
一个 Revision
一个对应的 Deployment(里面的 Pod 跑模型容器)
一个自动伸缩器:
要么是 KPA(Knative Pod Autoscaler)
要么是一个真正的 Kubernetes HPA(如果配置了 autoscaling.knative.dev/class: hpa.autoscaling.knative.dev)
接管 Knative Service,创建:
Istio:
负责入口网关、路由、mTLS 等
把请求导入到 Knative 的 activator / queue-proxy 上
为 Knative 提供 HTTP 请求 metrics(QPS、并发等)
不直接做扩缩容决策,只是提供流量和指标
真正做扩缩容决策的是:
Knative 的 KPA 或 HPA,再通过 Deployment 控制最终 Pod 数量
KServe 只是 “声明模型 + 帮我们写好 Knative 配置”,并不直接操作 replicas
2. enable-scale-to-zero: “true” 的含义是什么?
1# 文件: knative-config.yaml
2enable-scale-to-zero: "true"
在 Knative 的 config(比如 config-autoscaler)里,表示 允许某个 Knative Service 被 KPA 缩到 0 个 Pod。 再配合 InferenceService / Knative Service 上的配置:
- 若没有设置 minScale / minReplicas,默认允许从 0 → N
- 若在 InferenceService 里(或 annotations)配了 minReplicas: 1 或 autoscaling.knative.dev/minScale: “1”,则不会缩到 0,而是至少保留 1 个 Pod(即 1 块 GPU 一直常驻)
缩到 0 的流程大致是:
- 一段时间内没有请求(由 Knative 的 autoscaler 统计)
- KPA 认为可以缩减,就把 Deployment 的 replicas 降到 0
- Pod 把 GPU 释放掉;节点上的 GPU 就空闲了
从 0 唤醒:
- 有新请求到达 Istio 网关 → 被路由到 Knative 的 Activator
- Activator 缓冲请求,并通知 autoscaler
- autoscaler 把 Deployment 从 0 扩到 1(或更多)个 Pod
- Pod 启动,模型加载进 GPU,处理缓存的请求(这就是冷启动)
3. 单模型 多 Pod ,如何占多机多卡?
把上面的流程套到 GPU 上看就是:
1. 每个推理 Pod 的容器请求:
1resources:
2 limits:
3 nvidia.com/gpu: 1
4
2. K8s 调度时确保:
- 每个 Pod 分配到一个有空闲 GPU 的节点
- 默认 nvidia.com / gpu 是「不可共享资源」,所以 1 Pod 独占 1 块卡
3. 当 autoscaler 决定从 1 Pod 扩到 N Pod 时:
- K8s 再调度 N-1 个新的 Pod 到其他 GPU 节点
- 最终你就是:同一个模型,多 Pod,分布在多台单卡机器上
- Istio / Knative 负责把请求均衡到这些 Pod 上
4. 当流量变小:
- autoscaler 把 replicas 从 N 缩回 1,甚至缩到 0
- 对应地释放掉一部分 / 全部节点上的 GPU
总的来说:
- 目前有两种模式:
- 单模型 + 单 Pod = 占用一台单卡机
- 单模型 + 多 Pod = 水平扩展到多台单卡机,多卡并行处理请求
多 Pod 的自动扩缩容流程:
决策逻辑在 Knative(KPA 或 HPA)这层
KServe 只是根据 InferenceService 的 spec & annotations 帮我们创建出合适的 Knative Service / autoscaler 配置
Istio 不做扩缩容决策,只负责网关和路由,同时为 Knative 提供 metrics / 流量通路
enable-scale-to-zero: “true” 是 Knative 的全局开关,允许在 InferenceService 里配置成真正可缩到 0 的无流量模型服务。
面临的问题
整个架构从水平扩容的角度讲是没有太大的问题,但当我们把视角切换到机器内部,看 pod 内部的情况,是有问题的,比如:
- 一个显卡 48G 显存,一个小模型可能只需要 10G 显示,但它独占了一张显示,这会造成资源的浪费
- 当我只有一两个模型需要部署时候问题不大。浪费也不大,但如果我有多个小模型(单卡能放下)都需要同时部署,如果不仔细计算显卡的使用率,那么有可能造成大量的资源浪费。
解决办法
对一个 LLM 来说,显存大致分三块:
- 模型权重(weights)
- 运行时开销(activations / 临时 buffer 等)
- KV Cache(连续 batching 的关键,vLLM 会尽可能把剩余显存拿来做这个)VLLM Docs
vLLM 通过 –gpu-memory-utilization 控制 “自己能用的显存占比”(默认 0.9),在这个额度内, 剩下的空间基本都会拿去做 KV Cache,以提升吞吐和并发。
所以:
- 如果我们看到 “模型只占 10G”,很可能只是在低并发、短上下文下的一瞬间观感;
- 一旦并发、上下文长度、请求峰值上去,KV Cache 会吃掉大量显存,这时候那 “剩余的 30+ G” 就会逐步被用起来。
如果在业务高峰期,这几个指标都比较高(比如显存长期 >70%,KV cache 使用率也不低),那 “单模型独占一张卡” 并不浪费,而是在换 性能 & 稳定性。
其实我们问题的本质是:“我有好几种小模型都要在线,单卡其实装得下,但一机一模型的部署方式会造成卡粒度上的浪费。”
要解决这个问题,大致有几条思路:按 “现实可行度” 从高到低排序:
- 业务层合并:能不用多模型就别用多模型
- 能用 一个 “能力足够强” 的主模型 + Prompt / LoRA 搞定,就不要真部署 N 个完全独立的小模型。
- 多数 “业务小模型” 的差异,其实是 “提示词 + 风格 + LoRA” 的区别,不一定非要上不同 base model。
- 把单模型的吞吐吃满
- 利用 vLLM 的连续 batching,提高并发、适当增加最大上下文、控制 QPS,让 GPU 真正跑到比较高的利用率。
- 我们已经有完整的 Prometheus / Grafana 看板方案,可以直接看 QPS、Token 吞吐、GPU Util、KV Cache 占用来调优。
- 实在必须多模型同卡,再考虑 “共享 GPU” 技术(下面会拆开说)
共享 GPU 技术
Time-Slicing
NVIDIA GPU Operator / k8s-device-plugin 提供的 Time-Slicing,本质是:
- 把一张物理 GPU 虚拟成多个 “replica” 资源,Pod 申请 nvidia.com / gpu: 1 时,拿到的是其中一个 replica;
- 底层靠 时间片轮转 在同一张卡上跑多个 Pod。
关键点(也是坑点)是:Time-Slicing 只切算力,不切显存,显存是共享的,没有隔离。NVIDIA Docs 这意味着:
- 如果多个 Pod 加起来申请 / 实际占用的显存 > 实际物理显存,就有概率 OOM;
- 即使不 OOM,Page Fault / 内存碎片也会让延迟非常不稳定。
而 vLLM 非常依赖稳定且持续的显存做 KV Cache,Time-Slicing 没有显存隔离,很容易被别的 Pod 挤爆显存导致 OOM,所以不适合 vLLM
MIG(Multi-Instance GPU)
MIG 的特点:
- 真正把 一张 GPU 切成多个硬件隔离的 “小卡”,每块有独立的显存、高带宽内存、缓存和计算核心
- 适合需要 延迟可预测、多租户隔离 的 LLM 推理场景
但 MIG 只在 A100 / H100 / A30 等特定卡上存在,普通云上 L4、L40、T4、V100 这类要么不支持,要么支持非常有限。对于我们来说,也不适用。
ModelMesh
KServe 其实就内置了两种 “模型平台形态”:1. Single-Model Serving(单模型平台)
- 每个服务只跑一个模型;
- LLM / 大模型几乎都是走这一条(包括 vLLM Runtime)。2. Multi-Model Serving(基于 ModelMesh 的多模型平台)
- 同一个模型服务器里可以放多模型,按需加载/卸载,适合一堆小模型共享有限卡的场景(比如 SKLearn/ONNX/OpenVINO 那些)。
ModelMesh 适合「很多模型 + 访问稀疏」的场景,ModelMesh 的设计目标是:
管理 大量模型(几十、几百甚至更多)
很多模型 QPS 很低,没必要长时间常驻显存 / 内存
通过「按需加载 + LRU 驱逐」来平衡:
内存 / 显存占用
冷启动延迟
另外,社区对 ModelMesh 的定位也比较明确:更偏向 “可伸缩多模型平台”,现在要把 LLM Runtime(特别是 vLLM)硬往 ModelMesh 里塞,是有一定探索和集成成本的,而且生态也还在演进中 https://github.com/kserve/kserve/issues/4299

如果我们前期的目标只是「十个以内」的小模型,希望高利用率、简单稳定,所以可以先不用 ModelMesh,真正到模型数爆炸、并且很多模型很冷时,再考虑 ModelMesh 会更合适。尤其是当前的重点是 “先把核心 LLM 跑稳定 & 可观测 & 易扩容”。
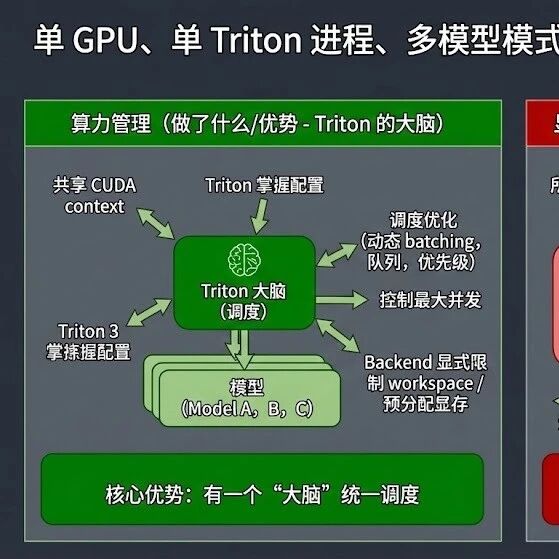
Triton + vLLM + 多模型同 Pod / 同 GPU
以上方案都不太合适,于是我把目光投向了 Triton
NVIDIA Triton 的能力是比较强的:
- 支持在同一台机器上多个模型 / 多个模型实例并行执行,由 Triton 负责调度;NVIDIA Docs
- 支持多种后端(TensorRT-LLM、PyTorch、ONNXRuntime、Python backend 等);
- 现在还有 官方的 vLLM backend,可以在 Triton 里用 vLLM 做 LLM 推理。
从 GPU 视角看,Triton 做的事类似于:“一个进程负责管理很多模型,来了请求就把对应的 op 丢给 GPU,GPU 再在硬件层面做调度并发。” 但是:Triton 也不会神奇地帮我们 “切显存”—— 多个模型的权重 + KV Cache 依然是往同一个物理显存里塞。Triton 提供的是 “共享一块显存的多模型协调器”,不是 “把显存分成几块小卡” 的硬隔离器。
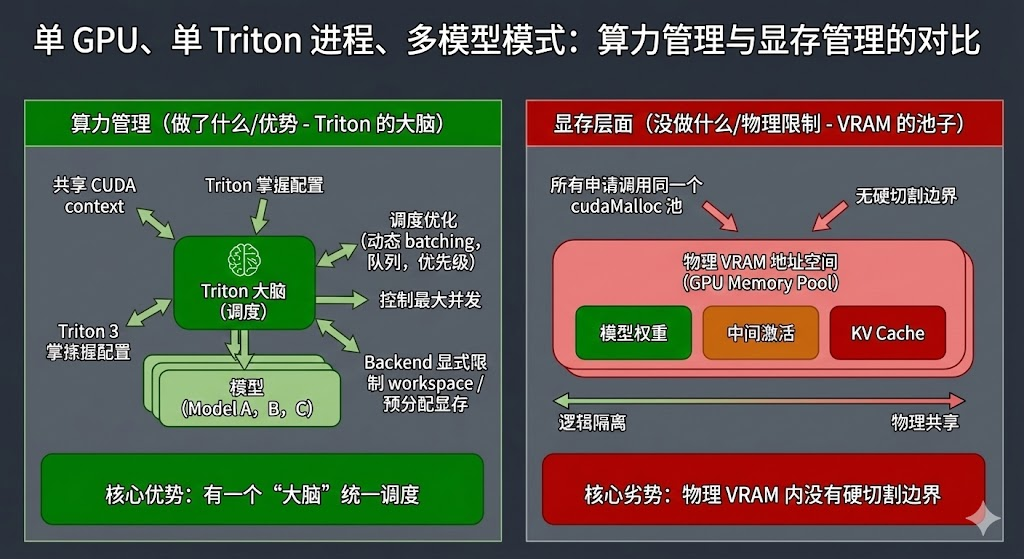
因此:
Triton 不能像 MIG 一样说:
“模型 A 只能用 16G,模型 B 只能用 8G,互相绝不会越界”
它顶多是:
通过配置 + 调度让你 “尽量别把自己搞到 OOM”;
但如果你把几个模型配置得都很激进,合起来 > 物理显存,照样可能 OOM,仅仅是更 “有迹可循”。
结合我们的实际情况,综合考虑,Triton 可以有以下几种组合姿势:
- Triton 只负责传统模型(embedding、CV、语音等),LLM 仍由独立 vLLM 服务跑
- 这时候 “一卡多模型” 主要是非 LLM 模型之间的事,LLM 是单卡独占或少量共享;
- 对现在的 “私有化大模型平台” 来说,这是最现实、也最可控的一种搭配。
- Triton + vLLM backend,把 LLM 也塞进 Triton 的统一服务里
- 本质上还是 “一张卡一个 vLLM 引擎”,只是对外通过 Triton 统一暴露接口而已;
- 多模型同卡时,显存依然一起抢;如果你试图放多个 LLM(哪怕是 7B SLM),很快就会撞上显存天花板,需要极其克制的 –gpu-memory-utilization 和并发控制。
- Triton 内部多 LLM + 非 LLM 模型混合
- 这种组合在理论上可行,工程上可做,但对资源规划、监控、故障排查的要求会非常高;
- 对现在来说,属于 “下一阶段再考虑” 的东西
综上,目前我们利用 Triton 采用第一种方式:负责传统模型(embedding、CV、语音等),LLM 仍由独立 vLLM 服务跑
对所有私有化部署的模型部署整体策略如下:

“
上图是从 KServe 视角看的,如果从 k8s 视角,不同的 pod 还会有多副本扩容的情况。但每个 pod 都是独占 GPU。
Triton 多模型(非 LLM)分组方案
整体思路:1 GPU 1 Triton,多模型共用
在现有架构下,最自然的做法是:
每块 GPU 起一个 Triton Pod(由一个 InferenceService 管)
这个 Triton Pod 里面的 model repository 里放多个非 LLM 模型:embedding / rerank / CV / ASR…
KServe 只是负责:
帮我们起 kserve-tritonserver 这个 runtime
把远端(S3/MinIO/PVC)上的 Triton model repository 挂到 /models(或 /mnt/models)
暴露统一的 HTTP / gRPC 入口(/v2/models//infer)
Triton 本身就是为「一台机上多个模型、多个实例并发」设计的:多个模型、多个实例可以在同一块卡上并发执行,通过 instance_group、dynamic_batching 来调度和吃满卡资源。NVIDIA Docs
建议按业务域 + 性能特性分组:
- 一组:文本向量 + rerank(text-embedder / text-reranker)
- 一组:CV / OCR / ASR(图像 & 语音) 这样:
- 同一组内模型的 batch 维度、输入大小比较接近,Triton 的 dynamic batching 比较好调;
- 资源隔离更清晰:文本这组爆了不会影响语音那组。
下面是一套完整配置样例(可以先从「所有非 LLM 都放一个组」开始,后面再拆分)
分组示例
Triton 模型仓库(model repository)结构示例,Triton 要求的模型仓库布局类似这样:
1 s3://your-bucket/triton-nonllm-repo/
2├── text-embedding-e5-small/
3│ ├── config.pbtxt
4│ └── 1/
5│ └── model.onnx
6├── text-rerank-msmarco/
7│ ├── config.pbtxt
8│ └── 1/
9│ └── model.onnx
10├── vision-cls-resnet50/
11│ ├── config.pbtxt
12│ └── 1/
13│ └── model.onnx
14├── asr-conformer/
15│ ├── config.pbtxt
16│ └── 1/
17│ └── model.onnx
18└── search-pipeline/
19 ├── config.pbtxt # 可选:Triton ensemble,把 embedder + reranker 串起来
20 └── 1/
21 └── model.graphdef / model.py / ...
只要 storageUri 指向这个目录,Triton 就会把子目录当成多个模型一起加载。
单个模型的 config.pbtxt 示例(带分组 / 实例配置),以一个 ONNX embedding 模型 为例: 路径:text-embedding-e5-small/config.pbtxt
1name: "text-embedding-e5-small"
2platform: "onnxruntime_onnx"
3max_batch_size: 128 # 这里根据你的 embedding 模型实际情况调
4
5input [
6 {
7 name: "input_ids"
8 data_type: TYPE_INT64
9 dims: [ -1 ] # 序列长度,-1 表示动态
10 },
11 {
12 name: "attention_mask"
13 data_type: TYPE_INT64
14 dims: [ -1 ]
15 }
16]
17
18output [
19 {
20 name: "embedding"
21 data_type: TYPE_FP32
22 dims: [ 768 ] # 或者你的模型真实向量维度
23 }
24]
25
26# 关键:在同一块 GPU 上开多实例,提高吞吐
27instance_group [
28 {
29 kind: KIND_GPU
30 count: 2 # 这块卡上起两个实例,看显存情况调 1/2/3
31 }
32]
33
34# 关键:Dynamic Batching,让 Triton 自动拼 batch
35dynamic_batching {
36 preferred_batch_size: [ 8, 16, 32, 64 ]
37 max_queue_delay_microseconds: 2000 # 2ms 内尽量攒一波请求
38}
39
同理,你可以为其他模型写各自的 config.pbtxt。分组思路:
- 对 高 QPS 的模型(比如 text embedding)可以把 max_batch_size 和 preferred_batch_size 设得大些,多起几个 instance_group;
- 对 低 QPS 但重模型(ASR、复杂 CV)就用 max_batch_size 小一点,甚至单实例。
如果有完整的 pipeline(比如「embedding → rerank」),可以用 Triton 的 ensemble 在 search-pipeline/config.pbtxt 里把两个模型串起来,一次请求走一条 DAG,减少网络往返。
KServe InferenceService YAML 示例(kserve-tritonserver)
KServe 自带 kserve-tritonserver 这个 ClusterServingRuntime,支持 TensorFlow / ONNX / PyTorch / TensorRT 模型。可以这样起一个「非 LLM 小模型专用」的 Triton 服务:
1apiVersion: serving.kserve.io/v1beta1
2kind: InferenceService
3metadata:
4 name: triton-nonllm-text
5 namespace: ai-serving
6 annotations:
7 # Knative 自动扩缩容(按并发)
8 autoscaling.knative.dev/metric: "concurrency"
9 autoscaling.knative.dev/target: "10" # 每 Pod 目标并发
10 autoscaling.knative.dev/minScale: "1"
11 autoscaling.knative.dev/maxScale: "5"
12spec:
13 predictor:
14 # ✅ 新 schema:通过 model.runtime 显式指定使用 kserve-tritonserver
15 model:
16 modelFormat:
17 # 这里写实际模型格式(比如 onnx / pytorch),只要包含在 kserve-tritonserver 支持列表中即可
18 # Triton 仓库里可以混放多种 backend,KServe 不会限制这一层
19 name: onnx
20 runtime: kserve-tritonserver
21 # 指向刚才那个包含多个模型的 Triton 模型仓库
22 storageUri: s3://your-bucket/triton-nonllm-repo
23 runtimeVersion: "24.03-py3" # 按你集群里安装的 kserve-tritonserver 版本改
24 # 如需 gRPC(性能更好),参考官方示例暴露 9000 端口:contentReference[oaicite:6]{index=6}
25 ports:
26 - name: h2c
27 protocol: TCP
28 containerPort: 9000
29 resources:
30 requests:
31 cpu: "4"
32 memory: "16Gi"
33 nvidia.com/gpu: 1
34 limits:
35 cpu: "8"
36 memory: "32Gi"
37 nvidia.com/gpu: 1
38 nodeSelector:
39 gpu-pool: "true" # 按你集群里标的 label 改,确保调度到有 GPU 的节点
40
几点说明:
- 多模型是 Triton 内部概念
- KServe 看到的只是「一个 InferenceService + 一个 Triton Pod」。
- Triton 会根据 storageUri 下的目录加载多个模型。
- 请求路径
走 KServe / Istio / Knative 的网关时:
HTTP:POST http:///v2/models//infer
gRPC:grpc://:/InferenceServer/ModelInfer(按 Triton V2 协议)
就是每个子目录名:text-embedding-e5-small / vision-cls-resnet50 / asr-conformer…
简单 Checklist:
- 准备 Triton 模型仓库
- 在 MinIO / S3 / PVC 上建好 triton-*-repo 目录;
- 把 embedding、rerank、CV、ASR 模型按 Triton 要求拆目录 + 写 config.pbtxt。
- 确认集群里有 kserve-tritonserver 的 ClusterServingRuntime
- kubectl get clusterservingruntime | grep triton
- 应用上面那个 InferenceService YAML
- 改好 storageUri、runtimeVersion、nodeSelector;
- 通过 /v2/models//infer 分别打 smoke test
- 文本 embedding / rerank / CV / ASR 各来几条请求;
- 对比 Triton metrics(/metrics)和 DCGM,看 GPU 利用率 & 显存占用。
请求流 & 监控流(两条主链路)
推理请求链路(从客户端到 vLLM)
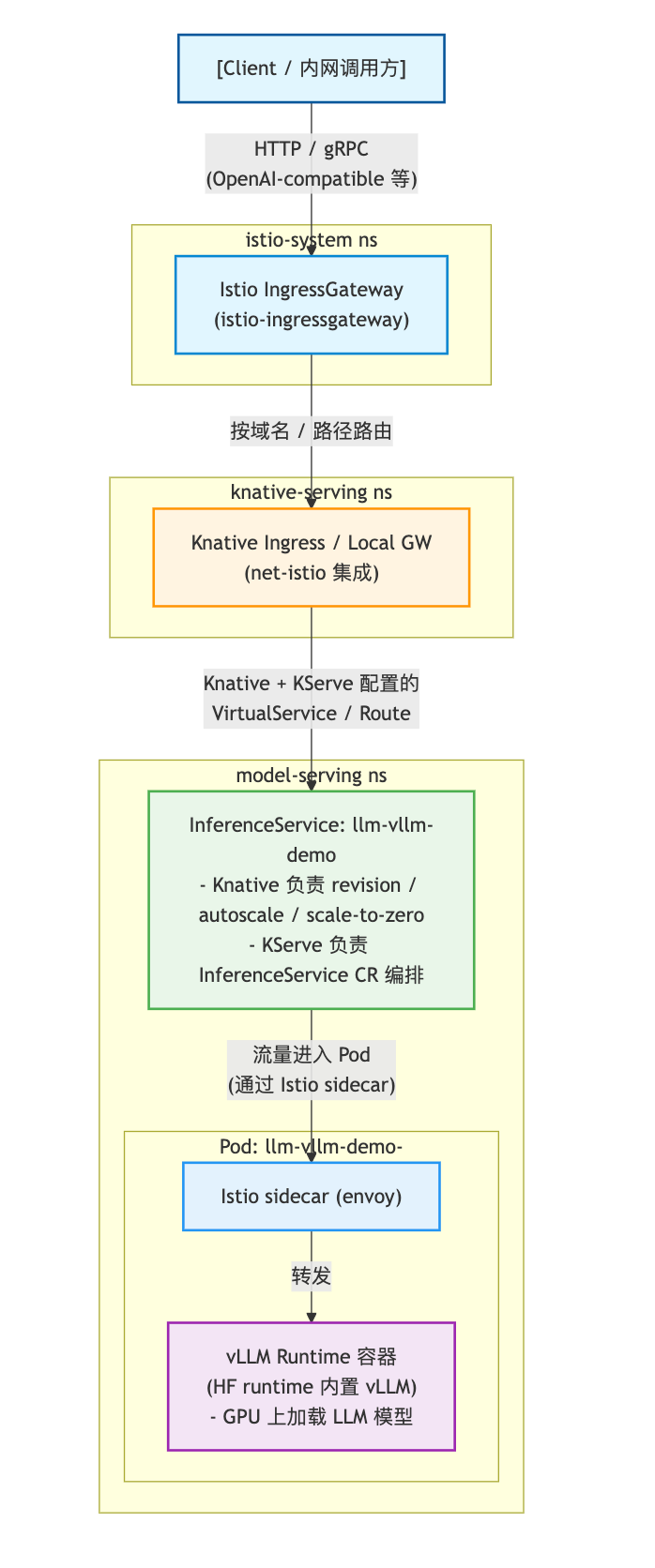
- KServe 把 InferenceService 抽象出来,底层仍然是 Knative Service + Istio VirtualService 这些资源;Istio ServiceMesh 文档里也有 “给 InferenceService 打 sidecar 做安全 / 流量治理” 的说明。
- vLLM 服务端会在 /metrics 上暴露自身的 Prometheus 指标,例如 vllm:prompt_tokens_total、vllm:generation_tokens_total、vllm:e2e_request_latency_seconds 等,用来统计 QPS、Token 数量和端到端延迟。
监控链路(业务 + GPU)
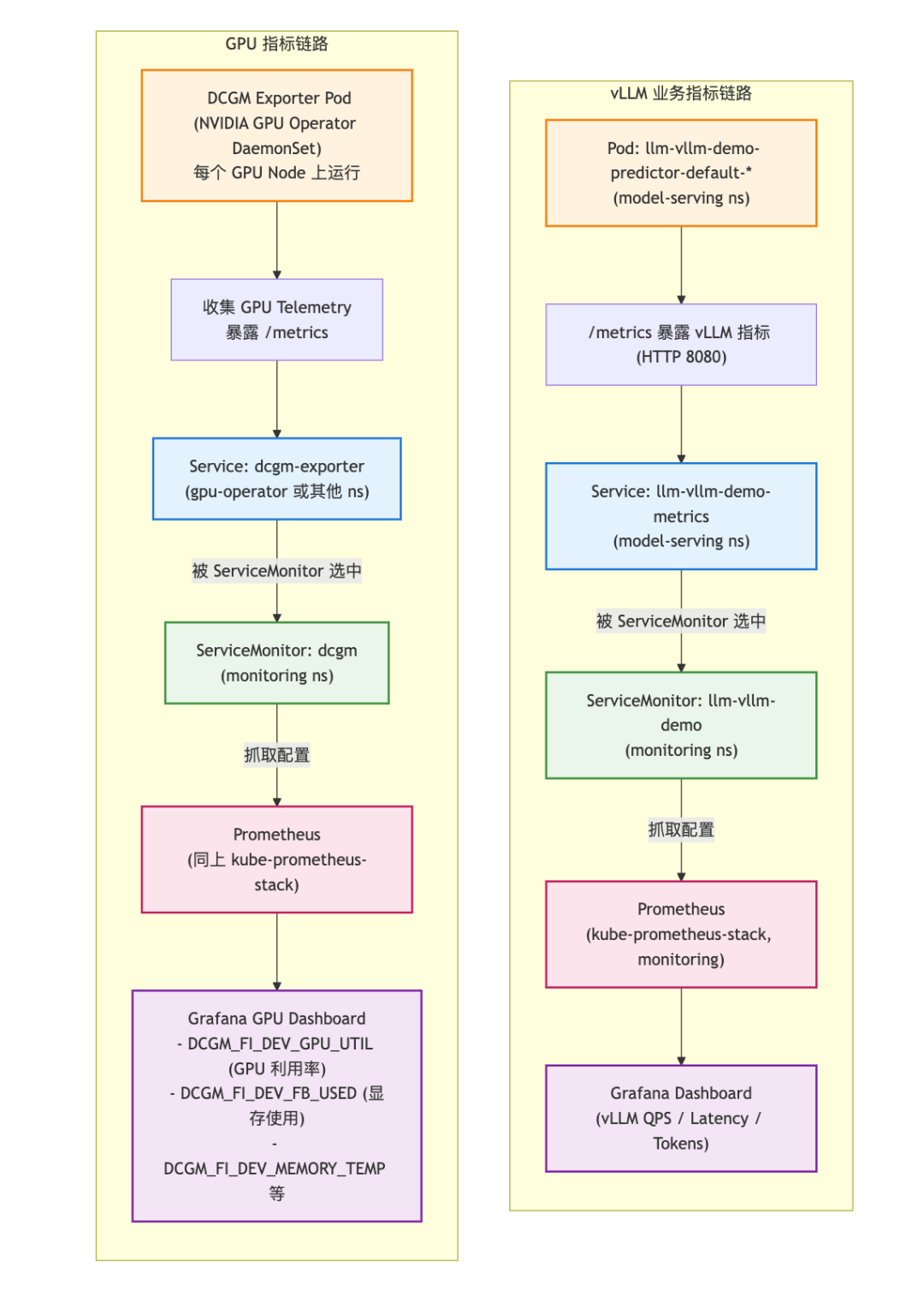
- NVIDIA 官方文档明确建议:在 Kubernetes 中监控 GPU 时,使用 DCGM Exporter → Prometheus → Grafana 这一条链路。
- 我们现在的设计就是把这一套和 vLLM 的业务 metrics 汇总到同一个 kube-prometheus-stack 里 —— 这也是很多实践里推荐的做法,用 Prometheus Operator 的 ServiceMonitor 去发现所有 exporter 与应用。
在 K8s 里做 GPU 监控,典型链路是:
“
GPU 节点 → GPU Operator → DCGM Exporter → Prometheus → Grafana
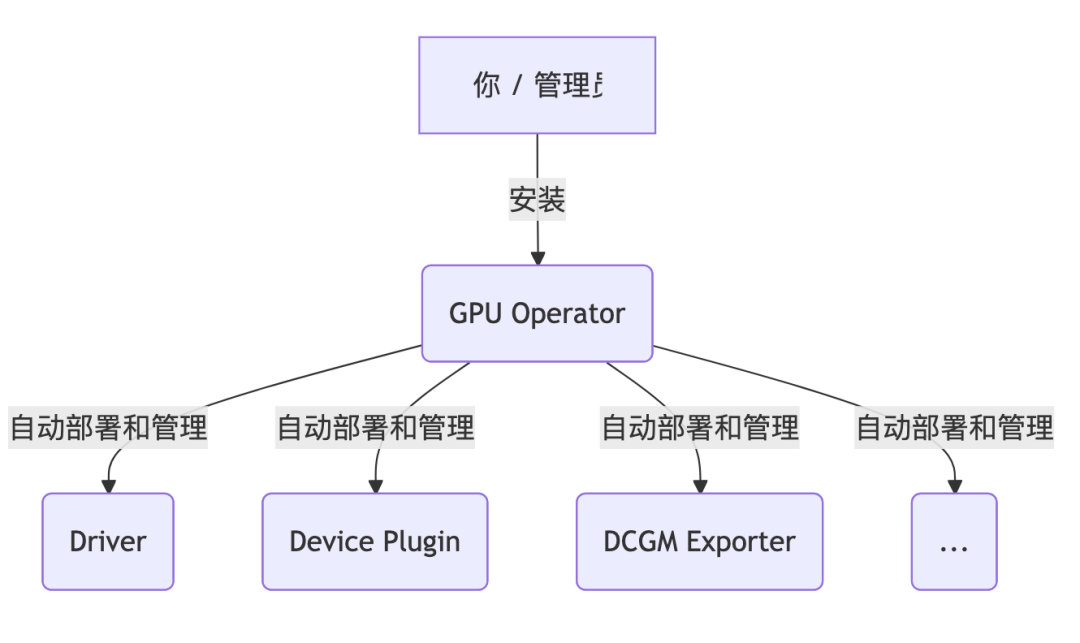
- GPU Operator:在 GPU 节点上自动装好驱动、Container Toolkit、Device Plugin、DCGM / Exporter 等一整套 GPU 栈。
- DCGM Exporter:基于 NVIDIA DCGM,把 GPU 的利用率、显存、温度、功耗等指标以 Prometheus /metrics 的形式暴露出来。
- NVIDIA 官方推荐:在 K8s 集群里采集 GPU Telemetry,就用 DCGM Exporter + Prometheus + Grafana 这一套。
- GPU Operator 默认就会启用 DCGM Exporter 来采集 GPU metrics(可以通过 Helm values 里的 dcgmExporter.enabled 开关)。
所以,我们只需要:
- 在 Kubekey 装好的 K8s 集群中安装 GPU Operator(包含 DCGM Exporter)。
- 在公司统一 Prometheus 上加一个 scrape job(或者在集群里用 ServiceMonitor),把这些 /metrics 抓过去即可
“
GPU Operator 是一个管理者,DCGM Exporter 是它管理的一个组件。 你只和管理者(Operator)打交道,它会帮你搞定一切。
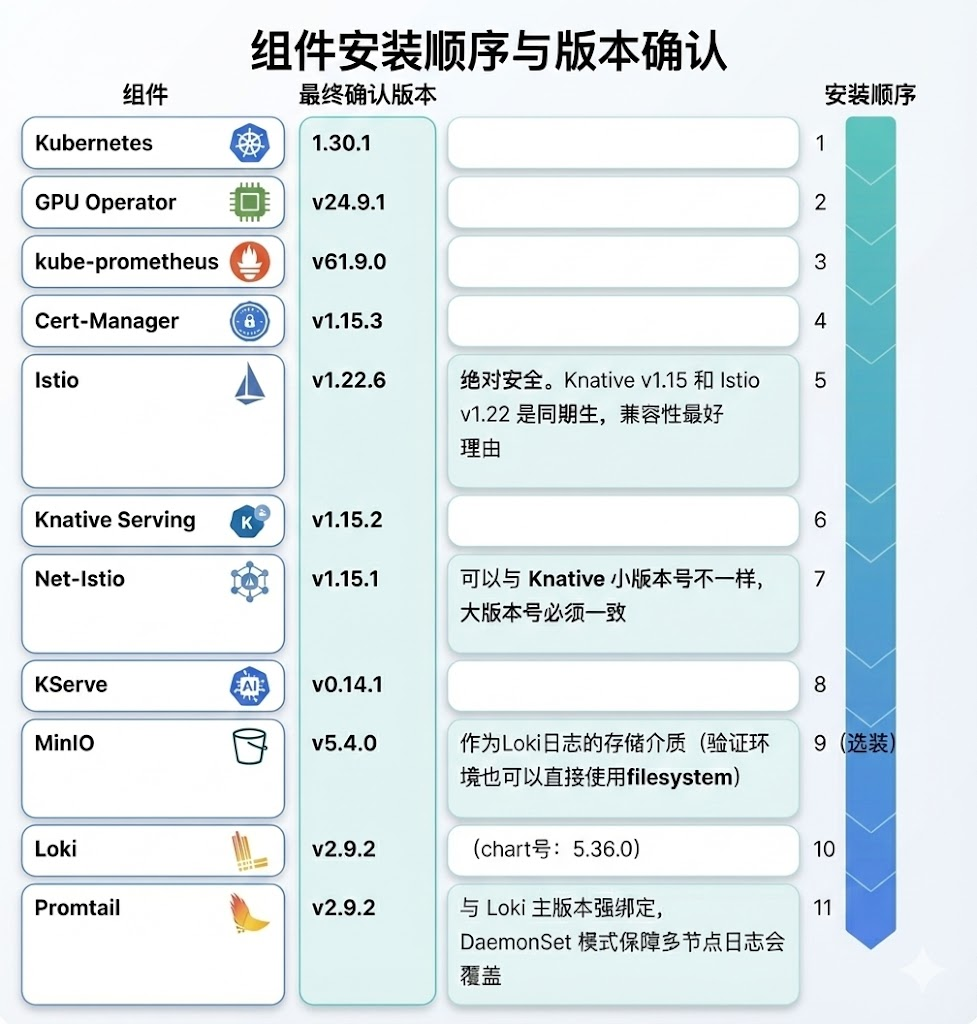
四、环境搭建步骤
需要安装的软件、版本及顺序
安装步骤 SOP
第 0 步:准备工作
1# 添加所有需要的 Helm 仓库
2helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
3helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
4helm repo add jetstack https://charts.jetstack.io
5helm repo add istio https://istio-release.storage.googleapis.com/charts
6helm repo update
第 1 步:安装 NVIDIA GPU Operator (v24.9.1)
目的:启用 GPU 驱动,并配置 CDI (Container Device Interface) 以兼容 K8s 1.30。
以下命令是在 GPU 驱动都安装好的前提下执行
1helm install gpu-operator nvidia/gpu-operator \
2 -n gpu-operator --create-namespace \
3 --version v24.9.1 \
4 --set driver.enabled=false \
5 --set toolkit.enabled=true \
6 --set cdi.enabled=true \
7 --set cdi.default=true
8
验证:等待 kubectl get pods -n gpu-operator 全绿。
如果出错,那么:
这个命令显式指定了版本,并且强制告诉 Operator 你的 Containerd 配置文件在哪里,避免出现之前的 FailedCreatePodSandBox 错误。
1helm install gpu-operator nvidia/gpu-operator \
2 -n gpu-operator --create-namespace \
3 --version v24.9.1 \
4 --set driver.enabled=false \
5 --set toolkit.enabled=true \
6 --set toolkit.env[0].name=CONTAINERD_CONFIG \
7 --set toolkit.env[0].value=/etc/containerd/config.toml \
8 --set toolkit.env[1].name=CONTAINERD_SOCKET \
9 --set toolkit.env[1].value=/run/containerd/containerd.sock \
10 --set toolkit.env[2].name=CONTAINERD_RUNTIME_CLASS \
11 --set toolkit.env[2].value=nvidia \
12 --set cdi.enabled=true \
13 --set cdi.default=true
第 2 步:安装 Kube-Prometheus-Stack (v61.9.0)
目的:基础监控。必须修正配置,否则 KServe 的 ServiceMonitor 会被忽略。
准备 values-kube-prometheus-stack.yaml
1# values-kube-prometheus-stack.yaml
2
3prometheus:
4 prometheusSpec:
5 # 允许抓取所有 namespace 下的 ServiceMonitor / PodMonitor
6 serviceMonitorNamespaceSelector: {}
7 podMonitorNamespaceSelector: {}
8
9 # 不再强制使用 Helm 的 release label 做筛选
10 # (默认是 true,会要求 ServiceMonitor 带 release=<helm release> 这样的 label)
11 serviceMonitorSelectorNilUsesHelmValues: false
12 podMonitorSelectorNilUsesHelmValues: false
13
14 # 空 selector = 不按 label 过滤,看到就抓
15 serviceMonitorSelector: {}
16 podMonitorSelector: {}
17
18 # 可选:Prometheus 数据保留时间
19 retention: 15d
20
21 # 暴露 Prometheus 的方式(开发环境方便直接 NodePort)
22 service:
23 type: NodePort
24 nodePort: 30090 # 访问地址:任一节点IP:30090
25
26grafana:
27 # Grafana 用 NodePort 方便先调试;生产看你们自己安全策略
28 service:
29 type: NodePort
30 nodePort: 30080 # 可不填,让 kube 随机分配
31
32 # 管理员密码(不写一般是 prom-operator,也可以明确写死)
33 adminPassword: prom-operator
这套配置的核心就是:Prometheus 不再只认「带 release=kube-prometheus-stack 的 ServiceMonitor」,而是「所有 namespace 下的 ServiceMonitor 都抓」,这样 GPU Operator 自动创建的 ServiceMonitor 也不会漏掉。
安装 kube-prometheus-stack
1helm install monitoring prometheus-community/kube-prometheus-stack \
2 -n monitoring --create-namespace \
3 --version 61.9.0 \
4 -f values-kube-prometheus-stack.yaml
打开 GPU Operator 的 监控组件(ServiceMonitor)
1#解释:
2#--reuse-values: 保留之前设置的 cdi.enabled=true 等参数。
3#--set dcgmExporter.serviceMonitor.enabled=true: 这才是核心,告诉 Operator 创建监控对象。
4
5helm upgrade gpu-operator nvidia/gpu-operator \
6 -n gpu-operator \
7 --reuse-values \
8 --set dcgmExporter.serviceMonitor.enabled=true
第 3 步:安装 Cert-Manager (v1.15.3)
目的:为 KServe 和 Knative 的 Webhook 签发自签名证书。
1helm install cert-manager jetstack/cert-manager \
2 -n cert-manager --create-namespace \
3 --version v1.15.3 \
4 --set crds.enabled=true
验证:等待 kubectl get pods -n cert-manager 全绿。
第 4 步:安装 Istio (v1.22.6)
目的:流量网关。严格按照 Base -> Istiod -> Gateway 的顺序安装。
1# 1. 安装 Base CRD
2helm install istio-base istio/base -n istio-system --create-namespace --version 1.22.6
3
4# 2. 安装 Istiod 控制平面
5helm install istiod istio/istiod -n istio-system --version 1.22.6 --wait
6
7# 3. 安装 Ingress Gateway (数据平面)
8helm install istio-ingressgateway istio/gateway -n istio-system --version 1.22.6
第 5 步:安装 Knative Serving & Net-Istio (v1.15.1)
目的:实现 Serverless 扩缩容能力。
1# 1. 安装 CRDs
2kubectl apply -f https://github.com/knative/serving/releases/download/knative-v1.15.2/serving-crds.yaml
3
4# 2. 安装 Serving Core
5kubectl apply -f https://github.com/knative/serving/releases/download/knative-v1.15.2/serving-core.yaml
6
7# 3. 安装 Net-Istio (网络适配器)
8kubectl apply -f https://github.com/knative-extensions/net-istio/releases/download/knative-v1.15.1/net-istio.yaml
验证:kubectl get pods -n knative-serving,确保 net-istio-controller 和 activator 状态为 Running。
第 6 步:安装 KServe (v0.14.1)
目的:核心推理平台。 注意这里使用的是 v0.14.1。
1# 安装 KServe CRDs
2helm install kserve-crd oci://ghcr.io/kserve/charts/kserve-crd \
3 --version v0.14.1 \
4 -n kserve --create-namespace
5
6# 安装 KServe Controller
7helm install kserve oci://ghcr.io/kserve/charts/kserve \
8 --version v0.14.1 \
9 -n kserve
执行完上述两条命令后,检查 KServe 的系统组件: kubectl get pods -n kserve
第 7 步:配置 vLLM Runtime (关键)
KServe 默认只有简单的 CPU 模型支持。为了运行公司级 LLM 服务,必须添加支持 GPU 的 Runtime。
保存以下内容为 vllm-runtime.yaml 并执行 kubectl apply -f vllm-runtime.yaml:
1apiVersion: serving.kserve.io/v1alpha1
2kind: ClusterServingRuntime
3metadata:
4 name: kserve-vllm
5spec:
6 annotations:
7 prometheus.kserve.io/port: '8080'
8 prometheus.kserve.io/path: "/metrics"
9 supportedModelFormats:
10 - name: vllm
11 version: "1"
12 autoSelect: true
13 containers:
14 - name: kserve-container
15 image: vllm/vllm-openai:latest
16 # 建议生产环境锁定具体 image sha256
17 command: ["python3", "-m", "vllm.entrypoints.openai.api_server"]
18 args:
19 - --port=8080
20 - --model=/mnt/models
21 - --gpu-memory-utilization=0.9
22 env:
23 - name: PORT
24 value: "8080"
25 resources:
26 requests:
27 cpu: "4"
28 memory: "16Gi"
29 nvidia.com/gpu: "1"
30 limits:
31 cpu: "8"
32 memory: "32Gi"
33 nvidia.com/gpu: "1"
第 8 步:为 GPU 调度开启 Knative 的 nodeSelector / tolerations
Knative 默认禁止你在 Knative Service 的 Pod 里写 nodeSelector / tolerations,KServe 官方教程在使用 GPU 时也会做这一步 patch。
打开特性开关
1kubectl patch configmap/config-features \
2 --namespace knative-serving \
3 --type merge \
4 --patch '{"data":{"kubernetes.podspec-nodeselector":"enabled", "kubernetes.podspec-tolerations":"enabled"}}'
重启 Webhook:
1kubectl delete pod -n knative-serving -l app=webhook
第 9 步:Istio Sidecar 注入策略(避免影响 GPU Operator 和监控)
默认 Istio 只对打了 istio-injection=enabled 标签的 namespace 注入 sidecar。确保「不需要注入」的 namespace 没有 label
保护基础设施 (防止 Sidecar 导致 Job 不退出)
1# 1. 明确禁止 GPU Operator 注入 (防止 Validator/Driver 安装卡死)
2kubectl label namespace gpu-operator istio-injection=disabled --overwrite
3
4# 2. 明确禁止 监控 注入 (减少开销)
5kubectl label namespace monitoring istio-injection=disabled --overwrite
6
7# 3. 明确禁止 kube-system 注入 (安全底线)
8kubectl label namespace kube-system istio-injection=disabled --overwrite
保护控制平面 (防止 Webhook 超时)
1
2kubectl label namespace knative-serving istio-injection=disabled --overwrite
3kubectl label namespace kserve istio-injection=disabled --overwrite
启用业务空间 (让模型享受 Service Mesh 能力),业务命名空间 “必须” 注入 ✅
1# 1. 创建你的业务空间 (如果你还没创建)
2kubectl create namespace model-serving
3# 2. 启用注入 (关键一步)
4kubectl label namespace model-serving istio-injection=enabled --overwrite
这样做的好处:
- GPU Operator、DCGM Exporter、Prometheus 不会被 sidecar 干扰
- 模型推理流量全部走 Istio + Knative 控制的入口
第 10 步:安装 MinIO(可选)
添加所有依赖 Helm 仓库
1# 添加MinIO、Loki官方仓库
2helm repo add minio https://helm.min.io/
3helm repo add grafana https://grafana.github.io/helm-charts
4# 更新所有仓库(确保获取最新Chart版本)
5helm repo update
MinIO 部署 —— 部署 2 节点分布式 MinIO(Loki 后端存储) MinIO 配置为 2 副本分布式,适配当前 2 节点,同时预留未来扩容参数,升级时仅需修改副本数即可。
编写 MinIO 配置文件 minio-distributed-values.yaml
关键标注:文件内 replicas 和 numberOfNodes 为扩容核心参数,未来扩容需同步修改为 3+ 等节点数。
1# 核心:启用分布式模式(2节点适配,未来扩容改replicas/numberOfNodes)
2mode: distributed
3replicas: 2
4numberOfNodes: 2
5
6# 镜像配置(你原单节点的成功版本)
7image:
8 repository: quay.io/minio/minio
9 tag: RELEASE.2023-07-07T07-13-57Z
10 pullPolicy: IfNotPresent
11
12# 访问密钥(完全沿用你的配置,Loki对接需一致)
13rootUser: U4DwltABIX8p20aONyoY
14rootPassword: 9YZInPYCqXwerS0NE6PDGrxo9g0l4akt2fs0IJNm
15
16# 持久化存储配置(你的成功配置,保障数据持久化)
17persistence:
18 enabled: true
19 storageClass: "" # 使用集群默认存储类
20 size: 10Gi
21 mountPath: /export
22
23# 服务配置(集群内访问,无需暴露外网)
24service:
25 type: ClusterIP
26 port: 9000 # S3兼容接口端口(Loki对接用)
27consoleService:
28 type: ClusterIP
29 port: 9001 # 管理控制台端口(可选)
30
31# 默认Bucket(Loki日志存储专用,自动创建,无需手动操作)
32defaultBucket:
33 enabled: true
34 name: loki-chunks # Loki配置需与该Bucket名一致
35 policy: read-write
36 purge: false # 卸载MinIO时保留数据
37
38# 资源限制(适配测试环境,低资源占用)
39resources:
40 requests:
41 cpu: 100m
42 memory: 512Mi
43 limits:
44 cpu: 500m
45 memory: 1Gi
46
47# 健康检查(分布式启动稍慢,微调延迟避免探针失败)
48livenessProbe:
49 initialDelaySeconds: 90
50 periodSeconds: 10
51readinessProbe:
52 initialDelaySeconds: 60
53 periodSeconds: 5
54
55# 跨节点调度策略(强制2个副本分布在不同节点,保障高可用)
56affinity:
57 podAntiAffinity:
58 requiredDuringSchedulingIgnoredDuringExecution:
59 - labelSelector:
60 matchExpressions:
61 - key: app.kubernetes.io/name
62 operator: In
63 values:
64 - minio
65 topologyKey: kubernetes.io/hostname
66
67# 安全配置(确保权限足够)
68securityContext:
69 runAsUser: 0
70 runAsGroup: 0
71 fsGroup: 0
72
73# 监控集成(默认关闭,若需对接Prometheus可改为true)
74metrics:
75 enabled: false
76 serviceMonitor:
77 enabled: false
安装分布式 MinIO
1helm install minio minio/minio \
2 -n monitoring \
3 --version 5.4.0 \
4 -f minio-distributed-values.yaml
验证 MinIO 部署(2 节点核心检查)
1# 查看MinIO Pod状态(2个副本均为Running,分布在不同节点)
2kubectl get pods -n monitoring -o wide | grep minio
3
4# 查看MinIO Service(地址固定,扩容后不变)
5kubectl get svc -n monitoring | grep minio
6
7# 验证桶创建成功
8kubectl exec -n monitoring minio-0 -- mc ls minio
9# 预期输出:[2024-xx-xx xx:xx:xx UTC] DIR loki-data
创建存储桶
Loki 的 ConfigMap 中指定了两个桶:chunks(存储日志块)、ruler(存储规则),先在 MinIO 中手动创建这两个桶(避免 Loki 首次写入时因桶不存在报错):
1# 进入minio-0 Pod,创建chunks和ruler桶
2kubectl exec -it minio-0 -n monitoring -- /bin/sh -c "
3 /usr/local/bin/mc alias set minio http://localhost:9000 U4DwltABIX8p20aONyoY 9YZInPYCqXwerS0NE6PDGrxo9g0l4akt2fs0IJNm --api S3v4 &&
4 /usr/local/bin/mc mb minio/chunks --ignore-existing &&
5 /usr/local/bin/mc mb minio/ruler --ignore-existing &&
6 echo '✅ Loki所需的chunks和ruler桶创建成功' &&
7 /usr/local/bin/mc ls minio # 验证桶是否存在
8"
第 11 步:安装 Loki 和 Promtail
编写 Loki 配置文件(loki-values.yaml)
1autoscaling:
2 enabled: true
3 maxReplicas: 5
4 minReplicas: 2
5 targetCPUUtilizationPercentage: 70
6 targetMemoryUtilizationPercentage: 80
7backend:
8 persistence:
9 enabled: true
10 size: 10Gi
11 storageClass: local
12 replicas: 2
13 # 可选新增:就绪探针(解决之前Pod卡死问题,不影响原有配置)
14 readinessProbe:
15 initialDelaySeconds: 60
16 timeoutSeconds: 10
17canary:
18 enabled: false
19gateway:
20 enabled: false
21grafanaAgent:
22 enabled: false
23image:
24 tag: 2.9.2
25loki:
26 auth_enabled: false
27 limits_config:
28 retention_period: 720h
29 schemaConfig:
30 configs:
31 - index:
32 period: 24h
33 prefix: index_
34 object_store: s3
35 schema: v11
36 store: boltdb-shipper
37 storage:
38 config:
39 s3:
40 access_key_id: U4DwltABIX8p20aONyoY
41 bucketnames: chunks # 匹配MinIO已创建的chunks桶
42 endpoint: minio:9000 # 保留你原有简写地址,不改动
43 insecure: true
44 secret_access_key: 9YZInPYCqXwerS0NE6PDGrxo9g0l4akt2fs0IJNm
45 s3forcepathstyle: true # MinIO必需的核心配置
46 type: s3
47read:
48 replicas: 2
49 # 可选新增:就绪探针(解决之前Pod卡死问题,不影响原有配置)
50 readinessProbe:
51 initialDelaySeconds: 60
52 timeoutSeconds: 10
53resources:
54 limits:
55 cpu: 1000m
56 memory: 2Gi
57 requests:
58 cpu: 300m
59 memory: 768Mi
60write:
61 persistence:
62 enabled: true
63 size: 20Gi
64 storageClass: local
65 replicas: 2
66 # 可选新增:就绪探针(解决之前Pod卡死问题,不影响原有配置)
67 readinessProbe:
68 initialDelaySeconds: 60
69 timeoutSeconds: 10
部署 Loki
1# 部署Loki
2helm install loki grafana/loki -n monitoring \
3 -f loki-values.yaml \
4 --version 5.36.0
Loki ConfigMap:
1apiVersion: v1
2data:
3 config.yaml: |2
4
5 auth_enabled: false
6 common:
7 compactor_address: 'loki-backend'
8 path_prefix: /var/loki
9 replication_factor: 1
10 storage:
11 s3:
12 bucketnames: chunks
13 # 新增:MinIO集群内服务地址
14 endpoint: minio.monitoring.svc.cluster.local:9000
15 # 新增:MinIO的Access Key
16 access_key_id: U4DwltABIX8p20aONyoY
17 # 新增:MinIO的Secret Key
18 secret_access_key: 9YZInPYCqXwerS0NE6PDGrxo9g0l4akt2fs0IJNm
19 # 修正:MinIO未开启HTTPS,改为true
20 insecure: true
21 # 修正:MinIO必须开启路径风格,改为true
22 s3forcepathstyle: true
23 frontend:
24 scheduler_address: query-scheduler-discovery.monitoring.svc.cluster.local.:9095
25 frontend_worker:
26 scheduler_address: query-scheduler-discovery.monitoring.svc.cluster.local.:9095
27 index_gateway:
28 mode: ring
29 limits_config:
30 enforce_metric_name: false
31 max_cache_freshness_per_query: 10m
32 reject_old_samples: true
33 reject_old_samples_max_age: 168h
34 retention_period: 720h
35 split_queries_by_interval: 15m
36 memberlist:
37 join_members:
38 - loki-memberlist
39 query_range:
40 align_queries_with_step: true
41 ruler:
42 storage:
43 s3:
44 bucketnames: ruler
45 # 新增:MinIO集群内服务地址
46 endpoint: minio.monitoring.svc.cluster.local:9000
47 # 新增:MinIO的Access Key
48 access_key_id: U4DwltABIX8p20aONyoY
49 # 新增:MinIO的Secret Key
50 secret_access_key: 9YZInPYCqXwerS0NE6PDGrxo9g0l4akt2fs0IJNm
51 # 修正:MinIO未开启HTTPS,改为true
52 insecure: true
53 # 修正:MinIO必须开启路径风格,改为true
54 s3forcepathstyle: true
55 type: s3
56 runtime_config:
57 file: /etc/loki/runtime-config/runtime-config.yaml
58 schema_config:
59 configs:
60 - index:
61 period: 24h
62 prefix: index_
63 object_store: s3
64 schema: v11
65 store: boltdb-shipper
66 server:
67 grpc_listen_port: 9095
68 http_listen_port: 3100
69 storage_config:
70 hedging:
71 at: 250ms
72 max_per_second: 20
73 up_to: 3
74kind: ConfigMap
75metadata:
76 annotations:
77 meta.helm.sh/release-name: loki
78 meta.helm.sh/release-namespace: monitoring
79 creationTimestamp: "2025-11-24T08:14:03Z"
80 labels:
81 app.kubernetes.io/instance: loki
82 app.kubernetes.io/managed-by: Helm
83 app.kubernetes.io/name: loki
84 app.kubernetes.io/version: 2.9.2
85 helm.sh/chart: loki-5.36.0
86 name: loki
87 namespace: monitoring
88 resourceVersion: "8228076"
89 uid: 103b336c-fcb1-4516-85d8-76d45ca6c79d
验证 Loki 部署
1# 查看Loki核心组件(read/write/backend均需Running)
2kubectl get pods -n monitoring | grep -E "loki-read|loki-write|loki-backend"
3# 示例输出:
4# loki-backend-0 2/2 Running 0 5m
5# loki-read-546cd5b67c-dsb84 1/1 Running 0 5m
6# loki-write-0 1/1 Running 0 5m
部署 Promtail(日志采集代理)
编写 Promtail 配置文件(promtail-values.yaml)
1config:
2 # 对接Loki的write服务(集群内服务名解析)
3 clients:
4 - url: http://loki-write:3100/loki/api/v1/push
5
6 # 日志采集规则(采集K8s Pod日志)
7 scrape_configs:
8 - job_name: kubernetes-pods
9 kubernetes_sd_configs:
10 - role: pod # 基于Pod自动发现
11 relabel_configs:
12 # 添加命名空间标签
13 - source_labels: [__meta_kubernetes_pod_namespace]
14 action: replace
15 target_label: namespace
16 # 添加Pod名称标签
17 - source_labels: [__meta_kubernetes_pod_name]
18 action: replace
19 target_label: pod
20 # 添加容器名称标签
21 - source_labels: [__meta_kubernetes_pod_container_name]
22 action: replace
23 target_label: container
24 # 过滤掉无需采集的系统组件(可选,按需调整)
25 - source_labels: [__meta_kubernetes_pod_namespace]
26 regex: "kube-system|istio-system"
27 action: drop
28
29# 部署模式:DaemonSet(每个节点1个副本)
30daemonset:
31 enabled: true
32 extraArgs:
33 - --max-open-files=1000000 # 增加文件打开限制
34 # 健康检查配置
35 readinessProbe:
36 initialDelaySeconds: 60
37 timeoutSeconds: 10
38
39# 权限配置(解决日志目录读取权限问题)
40securityContext:
41 runAsUser: 0 # 以root用户运行
42 runAsGroup: 0
43 fsGroup: 0
44 allowPrivilegeEscalation: true
45 capabilities:
46 add:
47 - DAC_READ_SEARCH # 增加目录读取权限
48
49# 资源配置(低资源占用)
50resources:
51 requests:
52 cpu: 50m
53 memory: 64Mi
54 limits:
55 cpu: 200m
56 memory: 256Mi
57
58# 禁用非必需组件
59serviceMonitor:
60 enabled: false
61prometheusRule:
62 enabled: false
部署 Promtail
1# 部署Promtail
2helm install promtail grafana/promtail -n monitoring \
3 -f promtail-values.yaml \
4 --version 5.36.0
验证 Promtail 部署
1# 查看Promtail Pod(每个节点1个副本,均需Running)
2kubectl get pods -n monitoring | grep promtail
3
4# 查看Promtail日志(确认无报错,有日志推送记录)
5PROMTAIL_POD=$(kubectl get pods -n monitoring -l app=promtail -o jsonpath='{.items[0].metadata.name}')
6kubectl logs -n monitoring $PROMTAIL_POD | grep "Successfully sent batch"
7# 示例输出:level=info ts=xxx caller=client.go:347 msg="Successfully sent batch"
最终验证
验证 GPU Operator & GPU metrics 是否正常
看 GPU Operator 相关 Pod:
1kubectl -n gpu-operator get pods
2kubectl -n gpu-operator get ds
通常会看到类似:
- 驱动 DaemonSet
- Device Plugin DaemonSet
- nvidia-dcgm-exporter 或类似名字的 DaemonSet
找到 DCGM Exporter 暴露出来的 Service:
1kubectl -n gpu-operator get svc
里面一般会有一个和 dcgm-exporter 类似名字的 Service,对应端口 9400(Prometheus 默认端口)。
本地 port-forward 看看 /metrics:
1# 换成你查到的 dcgm exporter 服务名
2kubectl -n gpu-operator port-forward svc/nvidia-dcgm-exporter 9400:9400
3
4# 打开一个新终端:
5curl http://127.0.0.1:9400/metrics | head
应该能看到类似:
1# HELP DCGM_FI_DEV_SM_CLOCK SM clock frequency (in MHz).
2# TYPE DCGM_FI_DEV_SM_CLOCK gauge
3DCGM_FI_DEV_SM_CLOCK{gpu="0",UUID="GPU-xxxx"} 139
4...
说明 GPU 指标已经通过 DCGM Exporter 暴露出来了。
轻量级测试
1# 运行 GPU 测试 (显式申请 1 个 GPU)
2sudo kubectl run test-gpu-real \
3 -n model-serving \
4 --image=vllm/vllm-openai:latest \
5 --restart=Never \
6 --overrides='{"metadata": {"annotations": {"sidecar.istio.io/inject": "false"}}, "spec": {"containers": [{"name": "test-gpu-real", "image": "vllm/vllm-openai:latest", "command": ["nvidia-smi"], "resources": {"limits": {"nvidia.com/gpu": "1"}}}]}}'
7
8kubectl logs test-gpu-real -n model-serving
完整测试(triton + vllm)
有关 Namespace
注意 InferenceService 的 namespace 是:model-serving
为什么必须是 model-serving?
- Istio 注入生效:我们之前只给 model-serving 命名空间打了 istio-injection=enabled 标签。只有部署在这个命名空间下的 Pod,才会自动拥有 Istio Sidecar(负责流量路由、Metrics 等)。
- 资源隔离:将业务模型与系统组件(如 gpu-operator, knative-serving)分开,是生产环境的最佳实践。
举例:
1apiVersion: serving.kserve.io/v1beta1
2kind: InferenceService
3metadata:
4 name: qwen-7b-chat # 你的服务名称
5 namespace: model-serving # 👈 这里必须写 model-serving
6spec:
7 predictor:
8 model:
9 modelFormat:
10 name: vllm # 对应 ClusterServingRuntime 的名字
11 runtime: kserve-vllm # 如果你有自定义 Runtime,这里指定名字
12 storageUri: "pvc://model-pvc/qwen-7b" # 或者 "s3://..."
13 resources:
14 requests:
15 cpu: "4"
16 memory: "16Gi"
17 nvidia.com/gpu: "1" # 👈 申请 1 张显卡
18 limits:
19 cpu: "4"
20 memory: "16Gi"
21 nvidia.com/gpu: "1"
即使 YAML 里写了 namespace,习惯上在 apply 时显式指定一下也是个好习惯(双重保险):
1kubectl apply -f isvc-llm.yaml -n model-serving
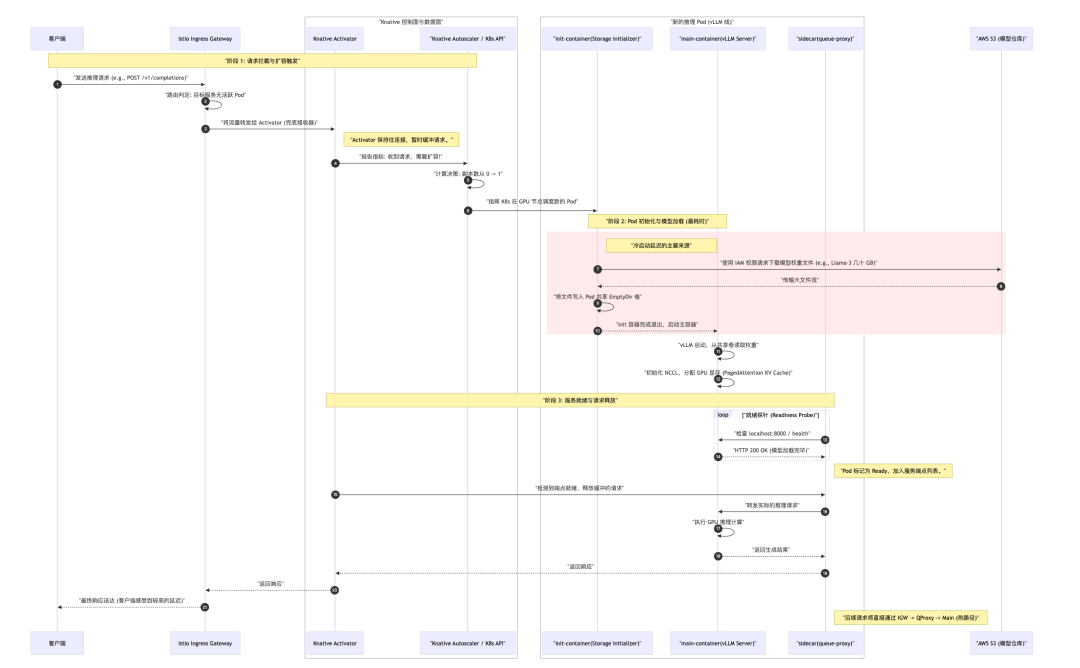
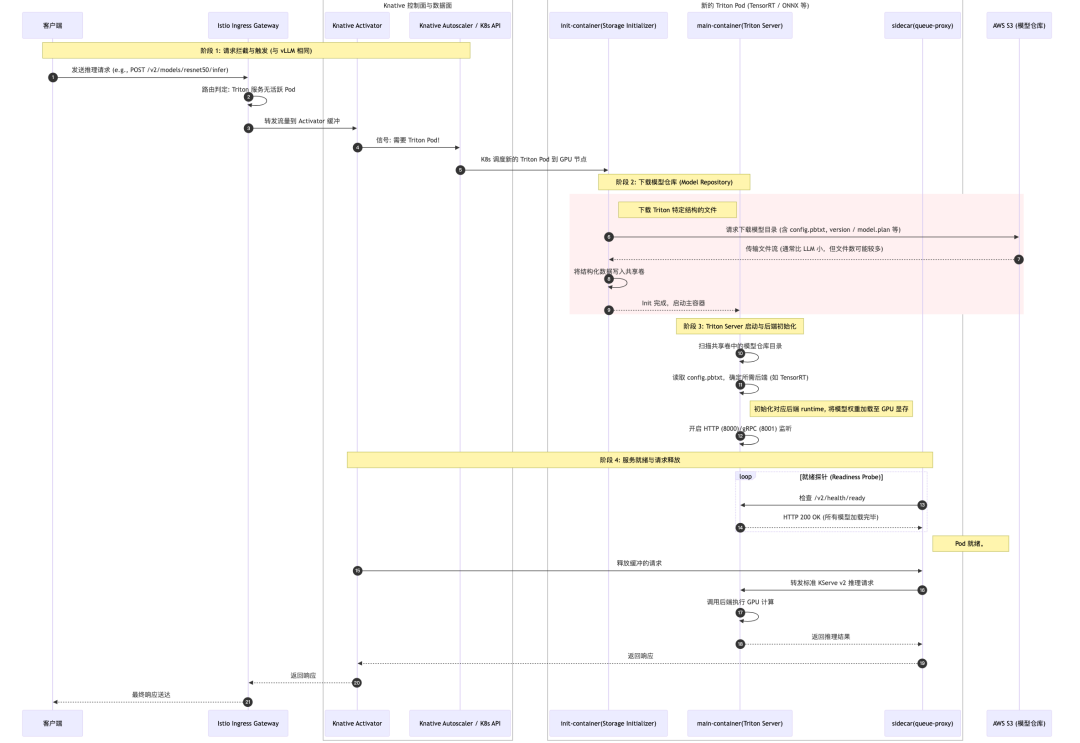
五、完整调用链路
六、基于 Argo 的 CI / CD
GitHub: https://github.com/argoproj/argo-cd 官网:https://argoproj.github.io/
“
Argo = 一套专门给 Kubernetes 用的开源工具家族,用来做 CI / CD、工作流编排、GitOps 部署、灰度发布、事件驱动等,是 CNCF 下面的毕业项目
Argo 不是一个单一软件,而是一个 “工具矩阵”,主要包括四个子项目:
- Argo Workflows
- Kubernetes 原生的 工作流 / 任务编排引擎
- 用 CRD(自定义资源)定义 Workflow,每个步骤跑在 Pod 里,非常适合 CI 流水线、数据处理、ML 训练等批处理任务
- Argo CD
- 一个 GitOps 风格的持续交付工具
- 通过对比 Git 仓库里的 “期望状态” 和 K8s 集群中的 “实际状态”,自动同步和回滚应用,常用来管理大规模集群配置
- Argo Rollouts
- 替代原生 Deployment 的 CRD
- 支持 蓝绿发布、金丝雀发布,可以接入网关、监控指标做渐进式发布和自动回滚
- Argo Events
- 做 事件驱动 自动化
- 支持各种事件源(Webhook、Kafka、S3 等),触发 Argo Workflows 或其他 K8s 资源,实现 event-driven CI / CD 或自动化任务
一句话:Argo = “围绕 Kubernetes 打造的一整套自动化 / GitOps / 发布 / 事件工具链”。
Argo 跟 Kubernetes 是什么关系?
“
Kubernetes 提供 “集群和基础设施”,Argo 提供 “在这个集群上自动化地干活的工具”。Argo 是 Kubernetes 最主流的 GitOps / Workflow 方案之一
CNCF 官方介绍中就把 Argo 定义为 “Kubernetes-native tools to run workflows, manage clusters, and do GitOps right”
运行环境层面:完全依赖 K8s
- Argo 的所有组件(Controller、UI 等)都是以 Deployment / Pod 的形式部署在 Kubernetes 集群中。
- Argo 的核心对象(Workflow、Rollout、EventSource、Application 等)都是 Kubernetes CRD。
职责分工:
Kubernetes 负责:调度 Pod、管理节点、网络、存储、基础监控。
Argo 负责:
把一堆任务编排成 “工作流” 并在 K8s 上跑(Workflows)
把 Git 仓库里的 YAML 自动同步到集群(CD & GitOps)
把发布过程做成可观测、可灰度控制的 rollouts(Rollouts)
把外部事件变成触发器(Events)
部署层级
所有文件都应该放到 git 让 Argo 负责吗?
不是的,这涉及到 “部署层级” 的问题。在云原生的 GitOps 实践中,我们将部署分为了两个截然不同的层级:
层级一:平台基础设施层
包含组件:Istio, Knative Serving, KServe, Cert-Manager, Nvidia Device Plugin 等。
特点:
变动低频:装好后很少动,顶多几个月升级一次版本。
全局影响:一旦挂了,所有模型全挂。
管理者:平台运维工程师 / SRE。
部署方式:通常使用 Helm Chart 或 Operator。
层级二:应用负载层
包含组件:InferenceService (模型), gateway (网关), ConfigMap (业务配置)。
特点:
变动高频:每天可能有新模型上线,或者修改版本、调整并发参数。
局部影响:配置错了只影响这一个模型。
管理者:算法工程师 / MLOps 工程师。
部署方式:YAML 文件 (InferenceService)。
所以目前来看,层级二的内容要以放到 git 中由 argo 管理 CD。层级一的也可以放到 git 中,但手动运维。
实践
Jenkins 本身是可以做全套的 CI + CD 的,但从我们推理服务部署这件事上来讲,CD (持续部署) 并不适合用 Jenkins,而适合用 Argo。Jenkins 在我们的这个场景下可以继续做它擅长的 CI (持续集成),但想了想,没必要那么麻烦,全部用 Argo 结合 Git 就完全能搞定,而且很方便,不适合用 jenkins 再增加运维复杂度了。
ArgoCD 是云原生时代的王者(GitOps 流)
实操 for Triton(预演)
假设:
- Git 仓库地址:git@github.com:your-name/ai-ops.git
- S3 Bucket:my-ai-models
- EKS 命名空间:ai-serving
- 自定义 Docker 镜像 –> 镜像仓库
第一阶段:基础设施与权限准备 (一次性工作)
这部分工作通常不需要经常变动,主要是为了打通 K8s 和 S3 的权限,以及准备 Git 仓库。
- 创建 Namespace (如果还没建)
1kubectl create namespace ai-serving
- 配置 S3 访问凭证 (Secrets) 注意:敏感信息不要直接上传到 Git。 我们先用 kubectl 手动创建 Secret(或者使用 ExternalSecrets / SealedSecrets 等高级方案,但现在先用简单直接的方式)。
准备一个 s3-secret.yaml 在你本地( 不要提交到 Git):
1apiVersion: v1
2kind: Secret
3metadata:
4 name: my-s3-secret
5 namespace: ai-serving
6 annotations:
7 serving.kserve.io/s3-endpoint: "s3.amazonaws.com" # AWS S3
8 serving.kserve.io/s3-region: "us-east-1" # 你的 Region
9type: Opaque
10stringData:
11 AWS_ACCESS_KEY_ID: "你的AK"
12 AWS_SECRET_ACCESS_KEY: "你的SK"
执行应用:
1kubectl apply -f s3-secret.yaml
- 准备 Git 仓库目录结构
在你的 ai-ops Git 仓库中,创建一个专门存放 ASR 部署文件的目录,例如 apps/asr-service/overlays/prod (如果是 Kustomize 结构) 或者直接 manifests/asr-service。
建议结构如下
1manifests/asr-service/
2├── service-account.yaml # 关联 Secret 的账号配置
3└── inference-service.yaml # 核心模型服务配置
编写 manifests/asr-service/service-account.yaml 并提交到 Git:
1apiVersion: v1
2kind: ServiceAccount
3metadata:
4 name: sa-s3-access
5 namespace: ai-serving
6secrets:
7 - name: my-s3-secret # 引用刚才手动创建的 Secret
第二阶段:模型工件准备 (模型上线 / 更新时操作)
这个阶段是 “搬运工” 工作,把模型传上去,让 KServe 有东西可拉。
- 本地整理 Triton 结构
如之前所述,确保本地目录结构正确:
1simple-asr/
2├── config.pbtxt
3└── 1/
4 └── model.onnx
- 上传到 S3
使用 AWS CLI 或手动上传。
1# 假设上传到 bucket 的 triton-repo 目录下
2aws s3 cp --recursive simple-asr/ s3://my-ai-models/triton-repo/simple-asr/
验证: 确保 s3://my-ai-models/triton-repo/simple-asr/config.pbtxt 存在。
第三阶段:Argo CD 配置与部署 (GitOps 核心)
这是让 Argo CD 接管部署的关键步骤。
- 编写 InferenceService 配置文件
在 Git 仓库的 manifests/asr-service/inference-service.yaml 中写入:
1apiVersion: serving.kserve.io/v1beta1
2kind: InferenceService
3metadata:
4 name: asr-service
5 namespace: ai-serving
6 annotations:
7 # 稍微改动这个字段可以触发 Argo 重新同步和 Pod 重启,常用于强制重新拉取模型
8 serving.kserve.io/model-version: "v1-20231121"
9spec:
10 predictor:
11 serviceAccountName: sa-s3-access
12 model:
13 modelFormat:
14 name: onnx
15 runtime: kserve-tritonserver
16 storageUri: s3://my-ai-models/triton-repo/simple-asr
17 resources:
18 limits:
19 nvidia.com/gpu: 1
提交代码到 Git:
1git add .
2git commit -m "Add ASR inference service"
3git push
- 创建 Argo CD Application
你需要告诉 Argo CD:“去监控我的 Git 仓库,把东西部署到 EKS 里”。
你可以通过 Argo CD 的 Web UI 点击 “New App” 创建,或者写一个 YAML 文件(推荐 YAML 方式,这叫 App-of-Apps 模式)。
创建一个文件 asr-argocd-app.yaml (手动 apply 这个文件):
1apiVersion: argoproj.io/v1alpha1
2kind: Application
3metadata:
4 name: asr-serving-app
5 namespace: argocd
6spec:
7 project: default
8 source:
9 repoURL: 'https://github.com/your-name/ai-ops.git' # 你的 Git 地址
10 targetRevision: HEAD
11 path: manifests/asr-service # 你的 YAML 所在目录
12 destination:
13 server: 'https://kubernetes.default.svc'
14 namespace: ai-serving
15 # 开启自动同步和自愈
16 syncPolicy:
17 automated:
18 prune: true # Git 里删了文件,K8s 里也删掉
19 selfHeal: true # 手动改了 K8s 配置,Argo 会强制改回来
20 syncOptions:
21 - CreateNamespace=true
执行:
1kubectl apply -f asr-argocd-app.yaml
第四阶段:验证与观察
一旦应用了上面的 Application YAML,奇迹就开始了:
- 观察 Argo CD UI:
- 你会看到 asr-serving-app 变成 Processing 状态。
- 它会画出一棵树:Application -> InferenceService -> Knative Configuration -> Revision -> Deployment -> Pod。
- 确保所有图标变绿(Healthy 和 Synced)。
- 观察 Pod 状态 (命令行):
1kubectl get pods -n ai-serving
你会看到类似 asr-service-predictor-00001-deployment-xxx 的 Pod。
- 如果是 Init:0 / 1:正在运行 storage-initializer 下载 S3 模型。
- 如果是 Running:模型下载完毕,Triton 启动成功
日常开发流程
这套系统搭建好后,以后的日常工作流就是:
- 算法同学:训练新模型 -> 导出 ONNX -> 上传覆盖 S3 上的 model.onnx。
- 运维 / 算法同学:
- 修改 Git 里的 inference-service.yaml。
- 比如修改 annotations 里的 version: “v2” 或者修改资源配额。
- git push。
- Argo CD:自动检测到 Git 变化 -> 更新 K8s 资源 -> Knative 滚动更新 -> 新 Pod 拉取新模型 -> 流量平滑切换。
这就是最标准的 GitOps 模型部署流程。
实操 for vLLM(预演)
第一阶段:基础设施准备 (一次性工作)
因为 KServe 可能不知道怎么启动 vLLM,我们需要先在集群里注册一个 “说明书”,告诉 KServe:“当我说用 vllm 时,请拉取这个镜像并运行这个命令”。
- 创建 vLLM 的 ClusterServingRuntime
将以下内容保存为 vllm-runtime.yaml 并 kubectl apply -f(或者放入 ArgoCD 管理的基础设施 Git 仓库中)。
1apiVersion: serving.kserve.io/v1alpha1
2kind: ClusterServingRuntime
3metadata:
4 name: kserve-vllm
5spec:
6 annotations:
7 prometheus.kserve.io/path: "/metrics"
8 prometheus.kserve.io/port: "8000"
9 containers:
10 - name: kserve-container
11 image: vllm/vllm-openai:latest # 使用 vLLM 官方镜像
12 command: ["python3", "-m", "vllm.entrypoints.openai.api_server"]
13 args:
14 # 这里的 args 是默认值,会被 InferenceService 里的 args 覆盖或追加
15 - --port=8080
16 - --model=/mnt/models
17 - --served-model-name=default
18 - --trust-remote-code
19 env:
20 - name: HF_HOME
21 value: /tmp/hf
22 resources:
23 requests:
24 cpu: "4"
25 memory: "16Gi"
26 limits:
27 cpu: "8"
28 memory: "32Gi"
“
注意:vLLM 默认监听 8000,但 KServe 容器通常要求监听 8080,所以我们在 args 里强制指定 –port = 8080。
第二阶段:模型上传 (S3)
vLLM 不需要 Triton 那种 1 / model.onnx 的结构。它只需要标准的 HuggingFace 模型文件夹。
假设你要部署 Qwen2-7B:
- 本地准备
你需要把 HuggingFace 上的文件下载下来,目录结构大概长这样:
1Qwen2-7B/
2├── config.json
3├── tokenizer.json
4├── model-00001-of-00004.safetensors
5├── ...
6└── model.safetensors.index.json
- 上传 S3
1aws s3 cp --recursive Qwen2-7B/ s3://my-ai-models/llm/Qwen2-7B/
第三阶段:Argo CD 部署配置 (GitOps)
- 在 Git 仓库中(manifests/llm-service/),编写 inference-service.yaml。
这里有几个关键点需要注意:
- runtime: 指定刚才创建的 kserve-vllm。
- storageUri: 指向 S3 文件夹。KServe 会把这里面的所有文件下载到 Pod 的 /mnt/models 目录下。
- args: 我们需要覆盖启动参数,告诉 vLLM 模型就在 /mnt/models。
1apiVersion: serving.kserve.io/v1beta1
2kind: InferenceService
3metadata:
4 name: qwen-llm
5 namespace: ai-serving
6 annotations:
7 # LLM 启动很慢(加载权重需要时间),必须调大健康检查超时时间,否则会被 K8s 杀掉
8 serving.knative.dev/progressDeadline: "20m"
9
10 # 自动扩缩容配置 (LLM通常基于并发或请求数)
11 autoscaling.knative.dev/target: "5"
12 autoscaling.knative.dev/minScale: "1" # 建议 LLM 至少保留1个,因为冷启动太慢了
13 autoscaling.knative.dev/maxScale: "3"
14spec:
15 predictor:
16 serviceAccountName: sa-s3-access # 别忘了 S3 权限账号
17 model:
18 modelFormat:
19 name: pytorch
20 runtime: kserve-vllm # 对应 ClusterServingRuntime 的名字
21
22 # KServe 会把这个 S3 路径下的内容下载到容器的 /mnt/models
23 storageUri: s3://my-ai-models/llm/Qwen2-7B
24
25 # 核心参数配置
26 args:
27 - --model=/mnt/models # 必填:指向下载好的模型路径
28 - --served-model-name=qwen # 服务名称,API调用时用到
29 - --gpu-memory-utilization=0.9 # 显存占用率
30 - --max-model-len=4096 # 上下文长度,防止 OOM
31 - --dtype=float16 # 或 bfloat16
32
33 resources:
34 requests:
35 cpu: "8"
36 memory: "32Gi"
37 nvidia.com/gpu: 1 # 必须有 GPU
38 limits:
39 cpu: "16"
40 memory: "64Gi"
41 nvidia.com/gpu: 1
42 nodeSelector:
43 gpu-type: "A100" # 建议指定节点类型
提交到 Git,Argo CD 检测到后会自动同步。
- 创建 Argo CD Application
你可以通过 Argo CD 的 Web UI 点击 “New App” 创建,或者写一个 YAML 文件(推荐 YAML 方式,这叫 App-of-Apps 模式)。
创建一个文件 llm-argocd-app.yaml (手动 apply 这个文件):
1apiVersion: argoproj.io/v1alpha1
2kind: Application
3metadata:
4 name: llm-serving-app # 应用名称,要在 Argo 面板上显示的
5 namespace: argocd # ArgoCD 安装的命名空间
6spec:
7 project: default
8 source:
9 repoURL: 'https://github.com/your-name/ai-ops.git' # 你的 Git 仓库
10 targetRevision: HEAD
11 path: manifests/llm-service # ✅ 关键点:指向存放 vLLM InferenceService 的目录
12 destination:
13 server: 'https://kubernetes.default.svc'
14 namespace: ai-serving # 部署的目标命名空间
15 # 启用自动同步,Git 变了 K8s 自动变
16 syncPolicy:
17 automated:
18 prune: true # Git 里删了,K8s 也删
19 selfHeal: true # K8s 里被改了,强制还原回 Git 的状态
20 syncOptions:
21 - CreateNamespace=true # 如果 ai-serving 命名空间不存在,自动创建
执行:
1kubectl apply -f llm-argocd-app.yaml
第四阶段:部署后的验证与调用
vLLM 启动成功后,它提供的是 OpenAI Compatible API。这意味着你可以直接用 OpenAI 的 SDK 或者 curl 来调用,这比 Triton 的 gRPC 接口对开发者更友好。
- 验证 Pod 状态
1kubectl get pods -n ai-serving
2# 等待状态变为 Running (可能需要几分钟下载模型和加载权重)
3kubectl logs -f <pod-name> -c kserve-container -n ai-serving
4# 看到日志显示 "Uvicorn running on http://0.0.0.0:8080" 即成功
- 调用测试 (在集群内部或通过 Ingress)
获取服务的 URL
1kubectl get isvc qwen-llm -n ai-serving
2# 假设 URL 是 http://qwen-llm.ai-serving.svc.cluster.local
发送请求(完全兼容 OpenAI 格式):
1curl http://qwen-llm.ai-serving.svc.cluster.local/v1/chat/completions \
2 -H "Content-Type: application/json" \
3 -d '{
4 "model": "qwen",
5 "messages": [
6 {"role": "system", "content": "You are a helpful assistant."},
7 {"role": "user", "content": "你好,介绍一下你自己。"}
8 ],
9 "max_tokens": 100
10 }'
vLLM 流程的关键 Checklist
- ClusterServingRuntime: 你的集群里如果没有 kserve-vllm 定义,第一步就会报错,必须先加这个 CRD。
- Timeouts: LLM 动辄 20GB+,下载 + 加载显存需要很久。一定要在 annotations 里设置 progressDeadline 为 20m 或更长,否则 Knative 会以为部署失败并回滚。
- Arguments: 必须通过 args 显式指定 –model=/mnt/models,因为这是 KServe storageUri 下载的目标路径。
- Resources: 显存和内存给够,否则 vLLM 会报 OOM(Out Of Memory)并 CrashLoopBackOff。
这套流程结合 ArgoCD 后,以后更新 LLM 版本(比如从 Qwen2 换到 Qwen2.5),你只需要:
- 上传新模型到 S3 的新目录。
- 修改 Git 里的 storageUri。
- ArgoCD 自动同步,Knative 会等待新 Pod 里的 vLLM 完全加载好权重后,才切断旧 Pod 的流量。
七、如何衡量平台是否成功?
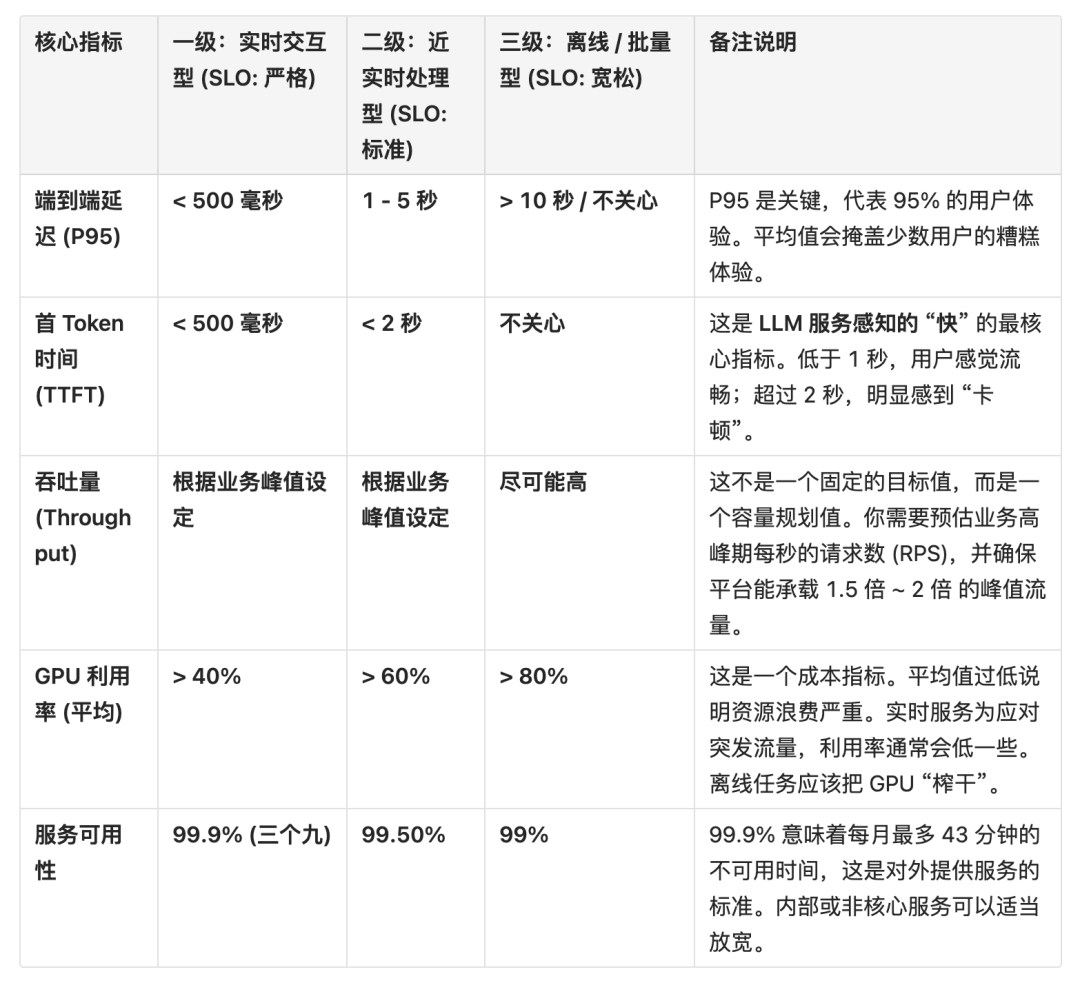
一个优秀的模型服务平台,其核心指标应该覆盖 性能、成本、稳定性 几个维度。
维度一:性能与延迟 (Performance & Latency) - “我们的服务快不快?”
- 端到端延迟 (End-to-End Latency) - P95 / P99
- 是什么? 从业务应用发出 API 请求,到收到完整响应的总时间。
- 为什么重要? 这是衡量用户体验的黄金标准。我们通常关注 P95(95% 的请求都快于此值)和 P99,因为平均值会掩盖那些最慢的、最影响用户的请求。
- 如何衡量? 从 Istio Gateway 或 Prometheus 中间件获取。
- 首 Token 时间 (Time to First Token - TTFT) - (LLM 专属)
- 是什么? 对于生成式模型,从发出请求到收到第一个有意义的 token 所需的时间。
- 为什么重要? 这是衡量 LLM 服务 “感知响应速度” 的最关键指标。一个低 TTFT 的模型会让用户感觉 “反应很快”,即使生成全文总时间较长。
- 如何衡量? 需要在客户端或 Transformer 中进行定制化测量
- 每输出 Token 时间 (Time Per Output Token - TPOT) - (LLM 专属)
- 是什么? 生成每个后续 token 的平均时间。它是 (总时间 - TTFT) / (总 token 数 - 1)。
- 为什么重要? 这是衡量 LLM “生成速度” 的核心指标。一个低的 TPOT 意味着模型的 “吐字” 速度很快,用户体验流畅。
- 如何衡量? 客户端或 Transformer 中计算。
- 吞吐量 (Throughput)
- 是什么? 单位时间内平台能成功处理的请求数。通常用 RPS (Requests Per Second) 或 QPS (Queries Per Second) 表示。
- 对于 LLM,一个更有意义的指标可能是 输出 Tokens/秒 (Output Tokens/Second),因为它综合了并发处理能力和生成速度。
- 为什么重要? 这是衡量平台容量和处理能力的上限。
维度二:成本与效率 (Cost & Efficiency) - “我们的钱花得值不值?”
- GPU 利用率 (GPU Utilization - Compute)
- 是什么? GPU 计算核心在单位时间内的繁忙程度百分比。
- 为什么重要? 这是衡量 “GPU 是否在干活” 的首要指标。一个持续低于 20% 的利用率可能意味着巨大的资源浪费。
- 如何衡量? 通过 NVIDIA DCGM Exporter 在 Prometheus 中采集。
- GPU 显存利用率 (GPU Memory Utilization)
- 是什么? GPU 显存被占用的百分比。
- 为什么重要? 很多模型(尤其是 LLM)可能计算量不大,但会占用海量显存。高显存占用会限制单卡能部署的模型数量。这是成本优化的另一个关键。
- 如何衡量? 通过 NVIDIA DCGM Exporter 采集。
- 闲置实例数 / 缩容至零频率 (Scale-to-Zero Metrics)
- 是什么? 平台上有多少模型服务实例处于 0 副本状态,以及它们进入和退出 0 副本状态的频率。
- 为什么重要? 直接体现了 KServe + Knative Serverless 架构带来的成本节省效果。
- 如何衡量? 从 Knative 的监控指标中获取。
- 冷启动延迟 (Cold Start Latency)
- 是什么? 当一个服务从 0 副本状态接收到第一个请求时,从开始拉起 Pod 到成功响应请求的总时间。
- 为什么重要? 这是 Serverless 模式为了节省成本而付出的性能代价。你需要监控并优化它,确保它在可接受的范围内。
- 如何衡量? 结合 Knative 指标和应用日志进行分析。
维度三:稳定性与可用性 (Stability & Availability)- “我们的服务稳不稳?”
- 服务可用性 (Availability)
- 是什么? 在规定时间内,服务能够正常响应的请求比例。通常目标是 99.9% 或 99.99%。
- 为什么重要? 这是衡量服务可靠性的最终标准。
- 如何衡量? (成功请求数 / 总请求数) * 100%。
- 错误率 (Error Rate)
- 是什么? 返回 5xx(服务器错误)状态码的请求比例。
- 为什么重要? 错误率的飙升是服务出现严重问题的最直接信号。需要设置告警。
- 如何衡量? 从 Istio Gateway 或 Prometheus 中间件获取。
- Pod 重启次数 (Pod Restart Count)
- 是什么? 模型服务 Pod 的重启次数。
- 为什么重要? 频繁的重启(特别是 CrashLoopBackOff 状态)表明代码存在 Bug、内存溢出(OOM Killed)或配置错误。
- 如何衡量? 从 Kubernetes API 直接获取。
短期看,最重要的指标有这几个:
- 端到端延迟 (End-to-End Latency)
- 首 Token 时间 (Time to First Token - TTFT)
- 吞吐量 (Throughput)
- GPU 利用率
- 服务可用性
长期看其实还要加上模型效果指标,量化 “准确率” 与 “生成质量”。