背景知识
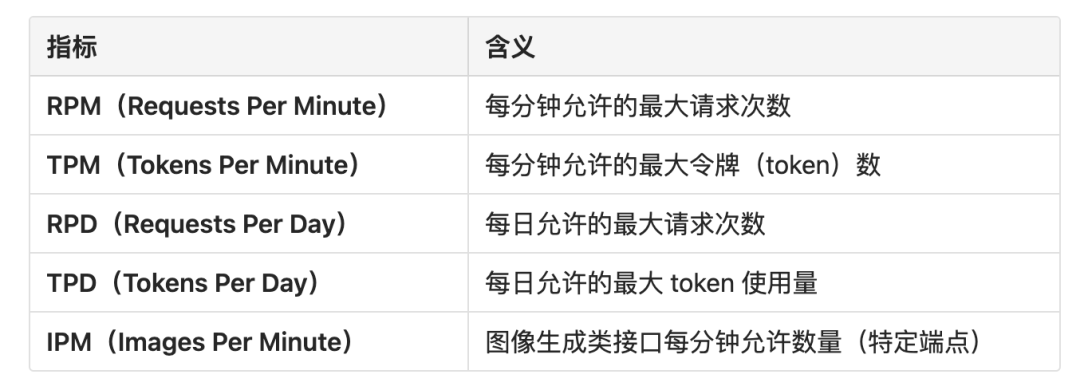
速率限制以五种方式衡量:
- RPM(每分钟请求数)
- TPM(每分钟 token 数)
- RPD(每日请求数)
- TPD(每日 token 数)
- IPM(每分钟图像数)
TPM (Tokens Per Minute)
中文含义: 每分钟 Token 数 定义: 在一分钟内,允许你的应用程序发送给模型(输入)和从模型接收(输出)的 Token 总量。
RPM (Requests Per Minute)
中文含义: 每分钟请求数 定义: 在一分钟内,允许你的应用程序向 API 接口发起调用的次数。
我们可以把 API 想象成一个高速公路收费站:
RPM (请求数) = 通过车辆的数量
限制 RPM 就像限制收费站每分钟只能通过 100 辆车。
不管你是摩托车还是大卡车,只要过一辆车,就占 1 个额度。
TPM (Token 数) = 车辆装载的货物总量
限制 TPM 就像限制收费站每分钟只能通过 10 吨货物。
你可以过 100 辆空载的摩托车(高 RPM,低 TPM)。
你也可能只过 1 辆装满货物的重型卡车,然后就超重了,后面不能再过车了(低 RPM,高 TPM)。
模型供应商配额说明
AWS
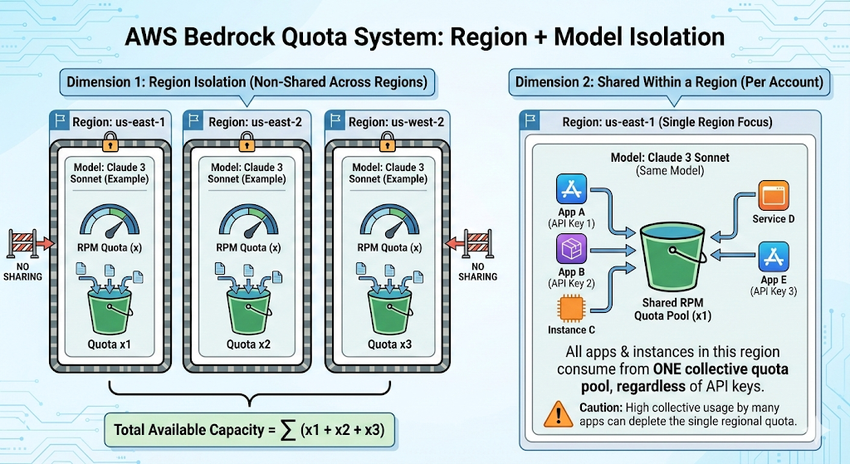
AWS Bedrock 的限额,本质上是按 **区域(Region) + 模型(Model)**这两个维度来限制的,不会在不同区域之间共享。
- 每一个 AWS 区域(Region)都有自己独立的一份模型配额
- 配额只在同一个区域内生效
举个例子:
- 如果你同时在 us-east-1、us-east-2、us-west-2 这三个区域使用同一个模型
- 那么这三个区域各自都有一份独立的 RPM 配额
- 实际可用的总请求能力,相当于 三个区域配额的总和(x1 + x2 + x3)
但需要注意一点:
- 在同一个 AWS 账户下 , 同一个区域内,同一个模型的配额是所有服务 / 应用共用的
也就是说,只要是在同一区域使用同一个模型,不管你起了多少个应用或实例,都会一起消耗这一个区域里的那份配额。(无论有多少个 api key)
Azure
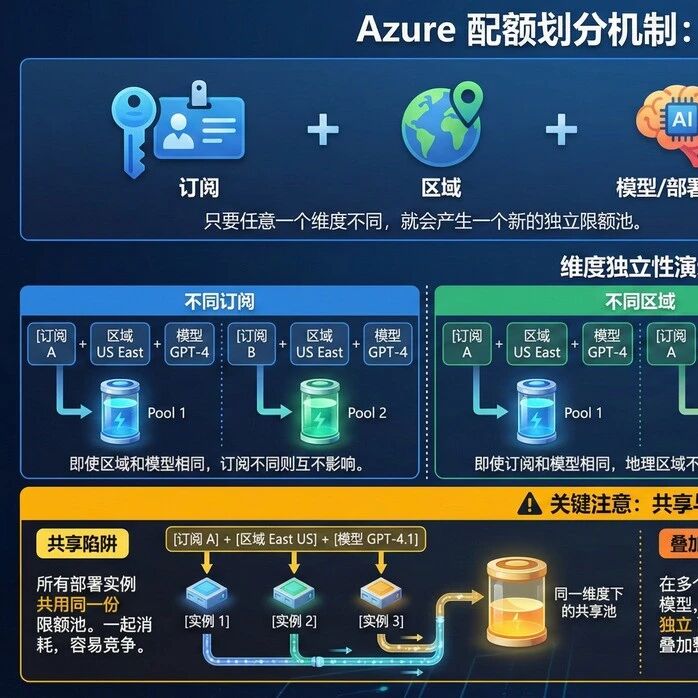
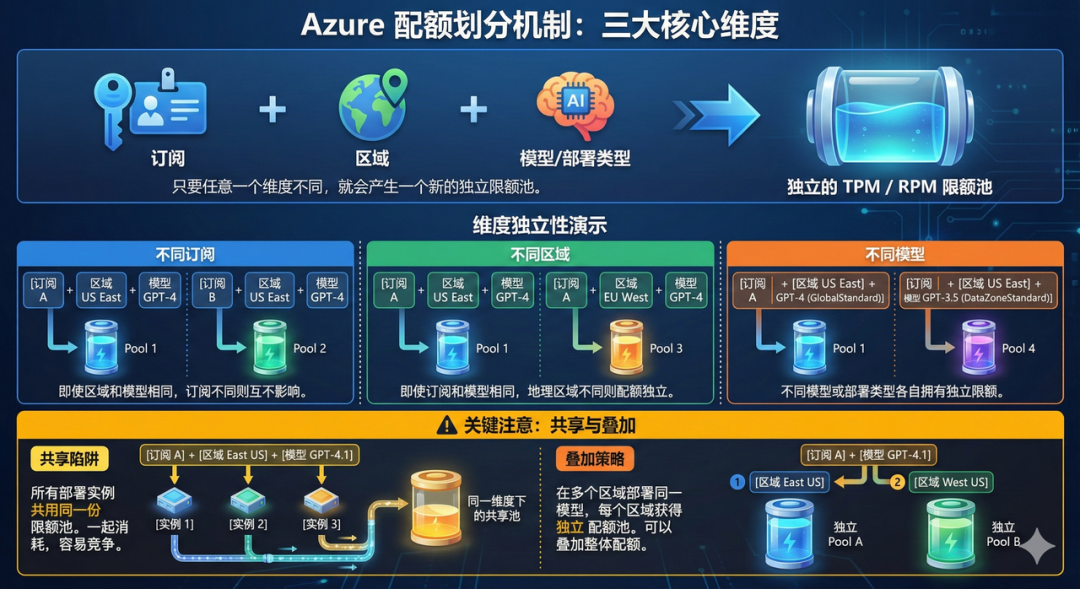
Azure 配额是按**「区域 + 订阅 + 模型 / 部署类型」**三个维度独立划分的
只要 “区域、订阅或模型” 其中任意一个维度不一样,就会拥有一份独立的 TPM / RPM 限额池。
订阅(Subscription)
不同订阅之间配额是独立的。即便是同一区域、同一个模型,不同订阅互不影响。
区域(Region)
不同的地理区域不会共享配额。 即使在同一个订阅、同一个模型下,不同区域都有各自完整的配额池
模型 / 部署类型(Model / Deployment Type)
不同模型或不同部署类型(GlobalStandard vs DataZoneStandard)各自有独立限额
假设 gpt-4.1 的默认配额是:
- 5,000,000 TPM
- 5,000 RPM
那么你在不同维度组合下会得到不同的配额池(以下每一条都是独立的配额,不互相占用):
⚠️注意:
在 同一个 Azure 订阅、同一区域、同一个模型下的所有部署实例会 共用同一份限额池。
比如 SubA 在 EastUS 部署多个 gpt-4.1 实例 → 都一起消耗这一区域这型号的配额
但如果 同一个订阅在多个区域部署同一模型,每个区域就能拿到一份独立 pool → 可以叠加整体配额。
核心公式(逻辑层面):总可用配额 ≈ Σ(每个区域 × 每个订阅 × 每个模型 / 部署类型 的配额池)
部署类型说明 :
- GlobalStandard 表示推理请求可以在 Azure 全球任何支持该模型的区域执行,默认配额较高,适合性能和吞吐要求高、对数据处理位置没有严格限制的场景。
- DataZoneStandard 则限制推理处理只在 Microsoft 定义的 “数据区域” 内部执行(比如整个美国或整个欧盟),仍然利用 Azure 的内部调度,但在区域范围内,兼顾更高默认配额和区域数据合规性。
⚠️注意:假设部署类型为 DataZoneStandard ,且数据区域在美国,我从中国发起的请求不会失败,Azure 会把这个推理请求转发到 “美国数据区域内部” 的节点去执行,DataZoneStandard 只是限制 “推理处理(模型计算)” 的位置范围,不是限制请求来源的位置。
OpenAI 官方
OpenAI 的配额体系用 Rate Limits 控制实时调用速率(请求数 + 令牌数),再通过 Usage Limit / Tier 决定这些速率上限能达到什么程度,两者结合起来确保公平使用、服务稳定以及根据付费情况自动提升资源用量。
在 OpenAI 平台下,不管你在同一个账号 / 组织里创建了多少个 API Key,它们都是共享同一个限额池,而不是每个 Key 有各自的配额。
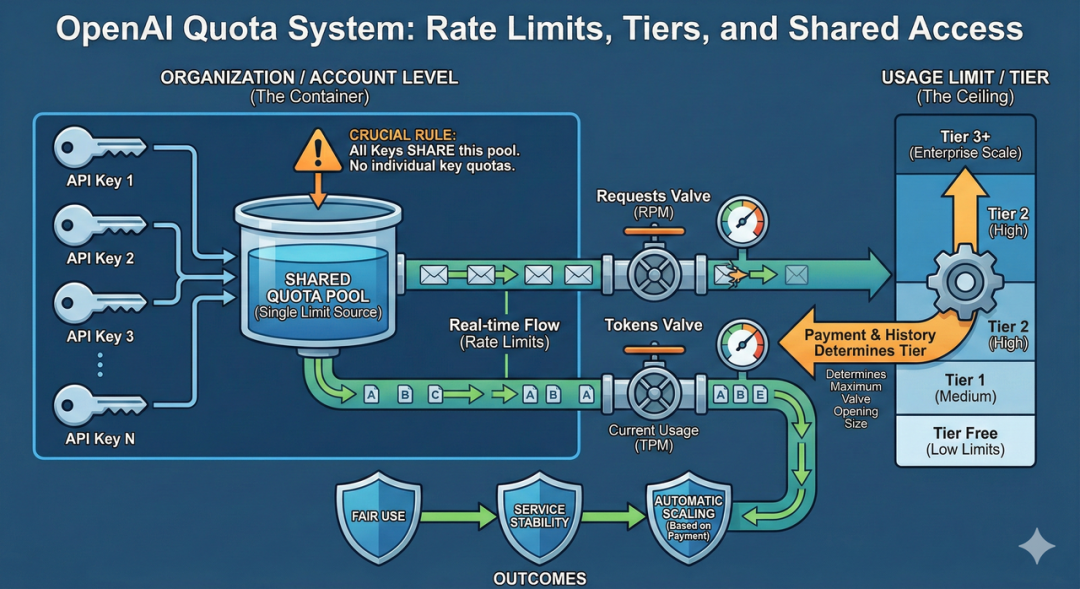
Rate Limits
OpenAI 的 Rate Limits 主要通过以下指标衡量:
📌 429 Too Many Requests 错误表示超过了当前限额,需要等待或降速重试
OpenAI 会同时检查请求数(RPM)和 token 数量(TPM):
- 即使 RPM 未达到上限,但 TPM 用尽时也会被限流
- 反之亦然,两者谁先触达阈值就会触发限制
例如:如果你的限制是 60 RPM 和 150k TPM
- 你每秒最多约 1 次请求
- 在触发任一限制时被拒绝继续调用
Usage Limit
不同模型和不同帐户级别(所谓的 Usage Tier / 付费等级)有不同的限额 (Usage Limit):
- 免费 / 低付费帐户 通常限额较低
- 高付费 / 企业帐户 有更高的 RPM 和 TPM
随着在 API 上的支出增加,OpenAI 会自动升级到下一个使用层级。通常会导致大多数模型的速率限制增加。

Rate limits(实时速率限制)与 Usage Limit 是不同概念:
- Rate Limit 是短时间内限制访问频率
- Usage Limit 是长期的消耗上限(例如每日 / 每月可消耗多少 tokens)
- Usage Limit 的设置会影响能持续调用的总量,而 Rate Limits 影响的是实时的频率控制
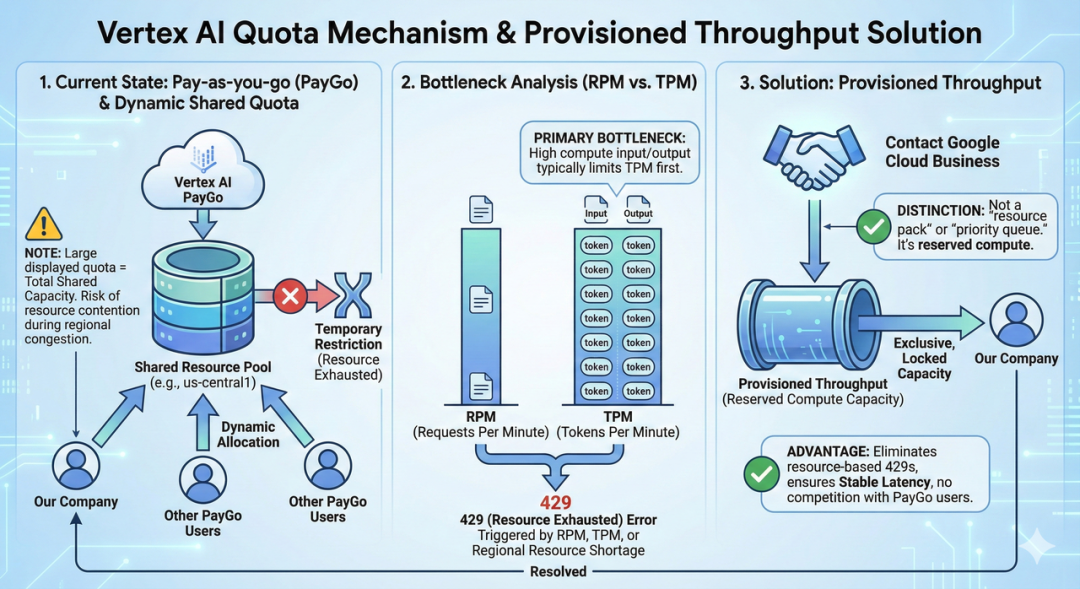
配额机制与 PayGo 模式: Vertex AI 的 Pay-as-you-go (PayGo) 模式对于 Gemini 1.5 Flash / Pro 及 Gemini 2.0 等较新模型,Google 采用动态共享配额 (Dynamic Shared Quota) 机制。这意味着我们不需要手动提交配额增加申请,系统会在特定区域内(如 us-central1)根据整体资源池的空闲情况,在所有 PayGo 客户之间动态分配容量。
注意:虽然配额显示数值很大(看似无限制),但这代表的是共享池的总量。在区域资源紧张时,我们仍需与其他用户竞争资源,可能会因为区域繁忙而暂时受限。
瓶颈分析 (RPM vs TPM) :根据官方最佳实践与实际经验,在大语言模型应用中,每分钟请求数 (RPM) 通常不是首要瓶颈。由于 Input(输入上下文)和 Output(生成内容)消耗大量计算资源,每分钟 Token 数 (TPM) 往往更容易先达到上限。当 TPM 或 RPM 任何一个达到阈值,或者区域资源不足时,系统均会返回 429 (Resource Exhausted) 错误。
解决方案:预配置吞吐量 (Provisioned Throughput): 如果业务对稳定性要求极高,且频繁遇到 429 错误,单纯依靠共享配额是不够的。此时应联系 Google Cloud 商务,购买 Provisioned Throughput (预配置吞吐量)。
- 区别: 这不是简单的 “资源包” 或 “优先级插队”,而是预留算力。
- 优势: 购买后,Google 会为我们锁定特定的计算容量,不再与其他 PayGo 用户争抢资源,从而彻底解决资源不足导致的 429 问题,并提供稳定的延迟表现。
XAI
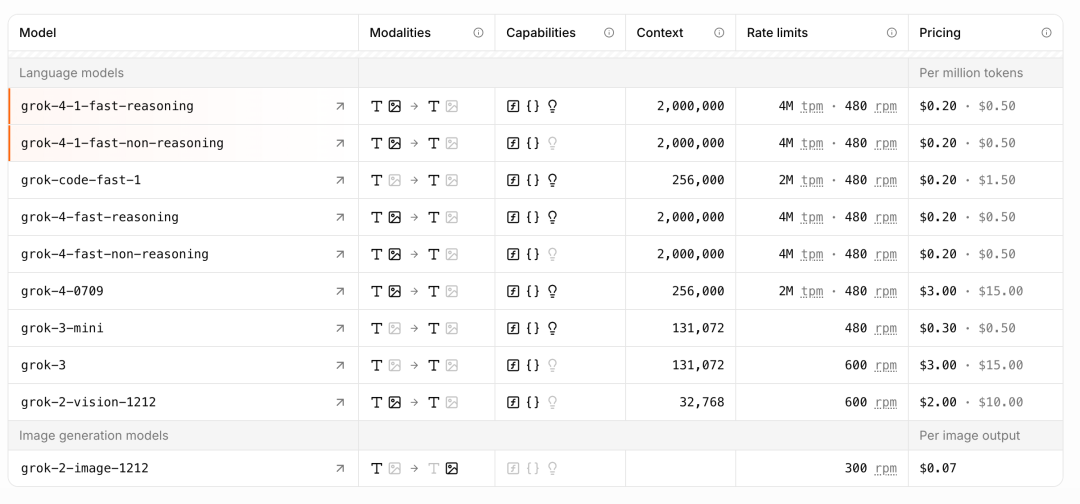
按账号 + 模型进行配额,各模型配额如下: