“
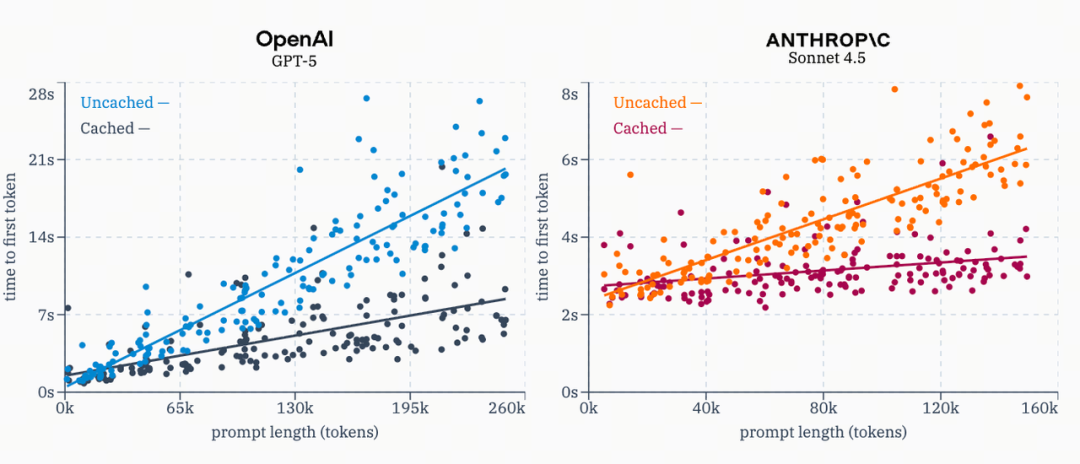
OpenAI 和 Anthropic 声称,缓存的输入 token 在成本上比常规输入 token 便宜 10 倍。
到底什么是 Cached Token ?
Cached Token 就是让 AI “记住” 它刚刚读过的长内容,不用每次都在脑子里从头重新算一遍,从而让回答变得极快且极便宜。
想象你正在参加一场开卷考试,考试内容是一本 500 页的历史书。
没有 Cache (传统模式) :
第一题: 你把书从第 1 页读到第 500 页,然后回答问题。
第二题: 你忘光了刚才读的内容,必须再次从第 1 页读到第 500 页,才能回答第二个问题。
后果: 每次回答都很慢,而且把你累得半死(消耗算力,费钱)。
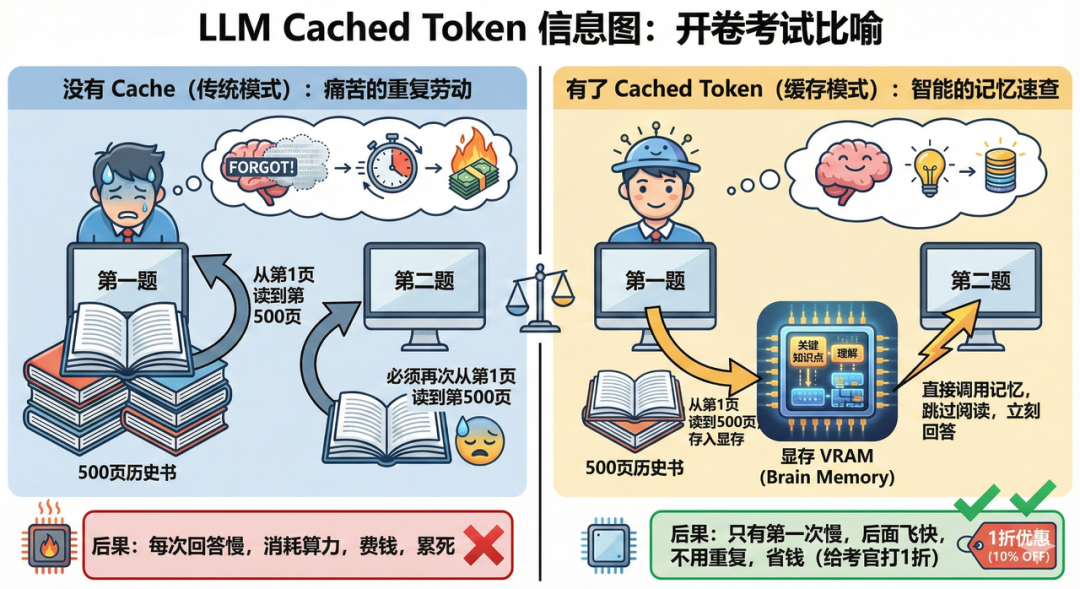
有了 Cached Token (缓存模式) :
第一题: 你从第 1 页读到第 500 页,并把关键知识点和理解暂时存在脑子里(存入显存)。
第二题: 你直接调用脑子里的记忆,跳过阅读过程,立刻回答问题。
后果: 只有第一次慢,后面飞快,而且因为不用重复劳动,甚至可以给考官(用户)打个一折的优惠价
很多人会误以为 “缓存 = 把上次的回复存起来再发一遍”。不是的。
更准确地说,缓存的是模型在处理这段输入时产生的一些中间计算结果(常被称为 KV cache:attention 里的 K / V 矩阵)。所以即使 cached_tokens 很高,你也仍然可能得到不同的回答(因为采样、temperature 等发生在更后面)
LLM 架构
想要彻底弄明白 Cached Token,我们需要从原理上了解一下 LLM 架构。
我们可以将大语言模型(LLM)的架构看作是一个巨大的数学函数:输入一串数字,输出一个数字。这个过程主要由以下四个核心部分组成:
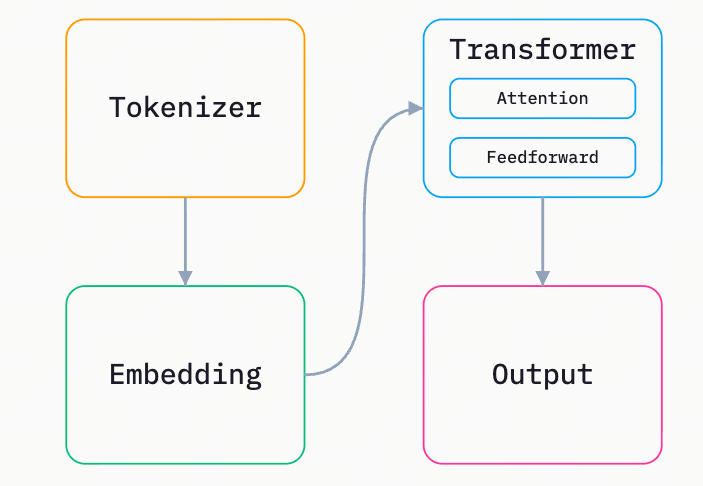
Tokenizer (分词器 / 切词器)
这是模型与人类语言交互的翻译官。
LLM 无法直接理解文本(如中文或英文),它只能处理数字。Tokenizer 的作用是将你输入的提示词(Prompt)切分成一个个小的片段,称为 Token,并为每个 Token 分配一个唯一的整数 ID。
比如输入 “Check out ngrok.ai”,Tokenizer 会将其切分为 [“Check”, “out”, “ng”, “rok”, “.ai”],并转换为对应的数字序列 。
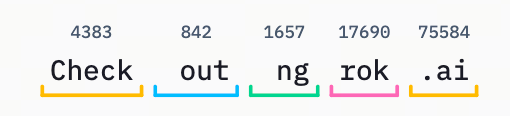
注意:不同的模型(如 GPT-5 和 Claude)使用不同的 Tokenizer 规则
Embedding (嵌入层)
这是让数字拥有含义的一步。将 Tokenizer 生成的简单整数 ID 转换为 高维向量(即一长串数字数组)。这个过程就像查字典,每个 Token ID 对应一个固定的向量。
下面是一个例子,可以看到将原始 token 进行 embedding 后是什么样子。

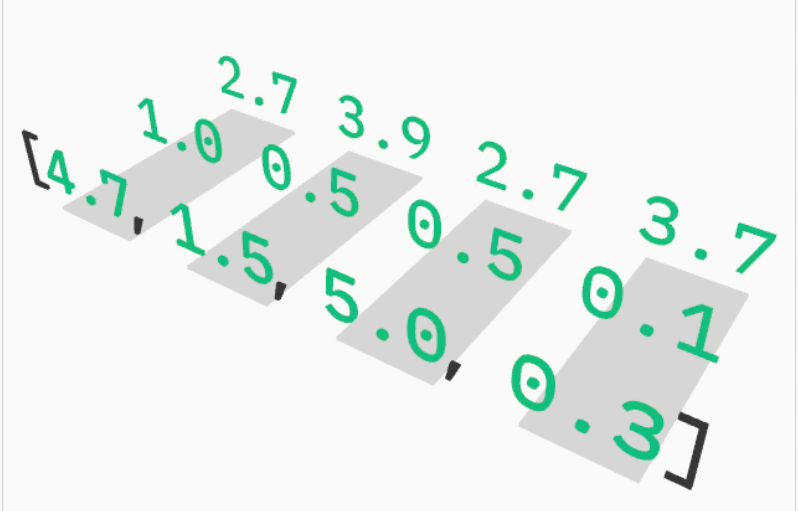
Embedding 是可以有很多维度的,最大的模型甚至超过 10,000 维,上面的例子只显示了三维。维度越多,大语言模型对每个标记的表示就越复杂、越细致。
这些向量代表了 Token 的 “语义位置”。在这个高维空间中,含义相似的词(如 “猫” 和 “狗”)在空间上的距离会更近。这一步还会把 Token 的 位置信息 编码进去,这样模型就能知道词语的先后顺序。
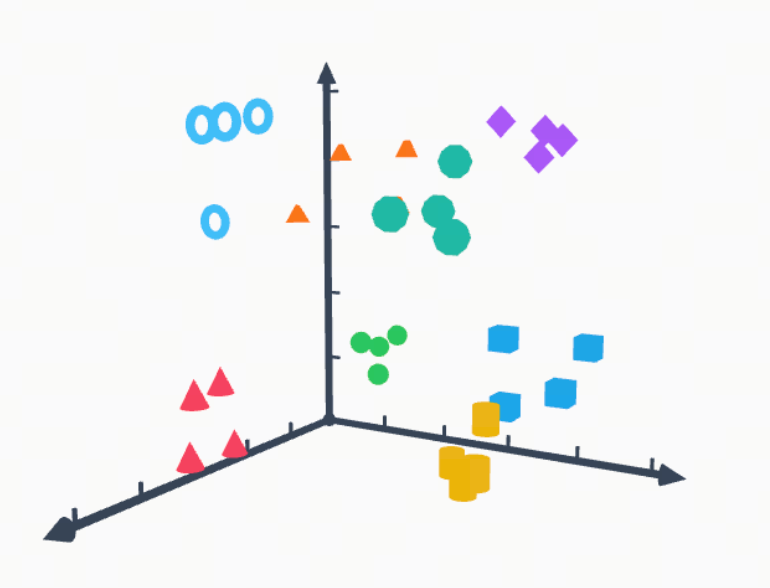
如果你听说过 “余弦相似度”,那么恭喜你找对了方向。Embedding(嵌入) 和 Cosine Similarity(余弦相似度) 的关系可以理解为 “坐标” 与 “距离测量工具” 的关系。
想象一个巨大的多维空间(就像一个无限大的图书馆)。Embedding 就是把每一个词、每一句话都变成这个空间里的一个 具体的坐标点,在这个空间里,意思相近的词(比如 “猫” 和 “小猫”),它们的坐标点会靠得很近;意思无关的词(比如 “猫” 和 “微波炉”),距离就会很远。Embedding 把文字变成了数学空间里的向量,而余弦相似度用来计算这些向量之间的 “语义距离”。
Transformer (变换器 / 核心处理层)
这是 LLM 的大脑,负责理解和推理。
它的主要工作是让输入序列中的每个 Token 相互 “交流”。模型会计算每个 Token 对其他 Token 的重要程度(即 “注意力权重”)。例如在句子 “Mary had a little lamb” 中,模型会计算出 “Mary” 对 “had” 的生成有多重要。这就是它的核心机制。
到这里我知道你肯定会想到这篇开山之作**《Attention Is All You Need》**。没错,这篇论文作为开山之作,几乎全篇都在讨论 “Transformer”。该论文提出的 Transformer 架构,其主要职责就是接收 Embedding 层的输入(一堆数字向量),然后在这一层内部通过 Attention(注意力机制) 和 Feedforward(前馈网络) 对这些数据进行复杂的数学变换。关于论文这里不便展开,我们言归正传。
在这一层,输入的 Embedding 会被转化为 Query (Q)、Key (K) 和 Value (V) 三种形态。通过复杂的矩阵运算(Q 乘以 K 得到权重,再乘以 V),模型能够理解上下文的语境和词与词之间的关系。
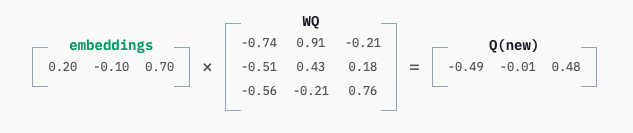
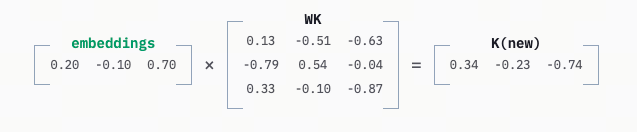
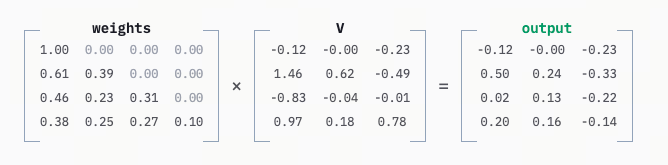
简单来说:
- 每个 token 会生成三组向量:Q (Query:我想找什么)、K (Key:我有什么线索)、V (Value:我的内容是什么)
- 通过计算 Q 和所有 K 的相似度,得到 “该关注谁” 的权重(softmax 归一化),再对 V 做加权求和,得到 “结合上下文后的新表示”。
- Multi-head 就是并行做多组注意力,让模型能同时学到多种关系(语法、指代、主题等)
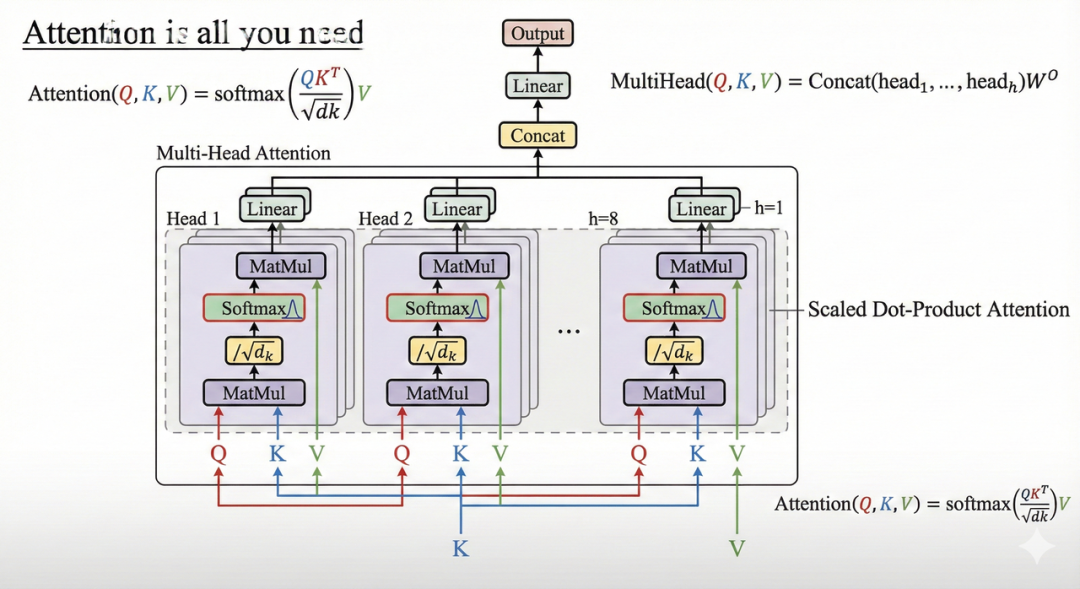
这个阶段是计算量最大的部分。为了加速,推理过程中会将计算过的 K 和 V 矩阵缓存起来(即 KV Cache),避免对之前的 Token 重复计算
Output (输出层)
这是最终生成结果的一步。
经过 Transformer 层层处理后,最后得到一个新的 Embedding。输出层会将其转化为概率分布,预测 下一个最可能出现的 Token。
LLM 是 “自回归” 的,这意味着它每次只生成一个 Token。生成的这个新 Token 会被加回到输入的末尾,整个流程(Tokenizer -> … -> Output)再次循环,直到生成结束符(如)或达到长度限制
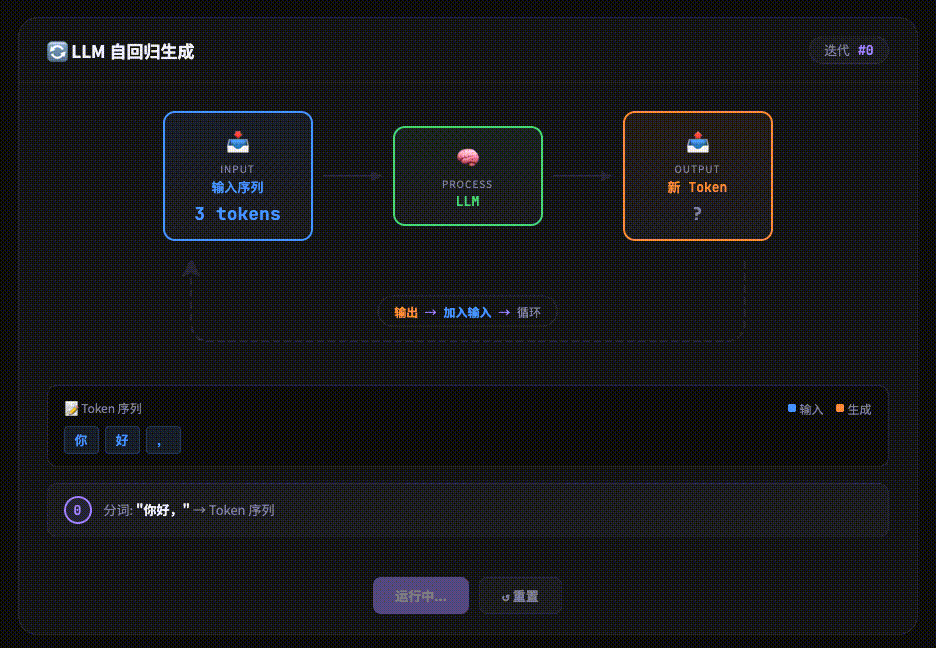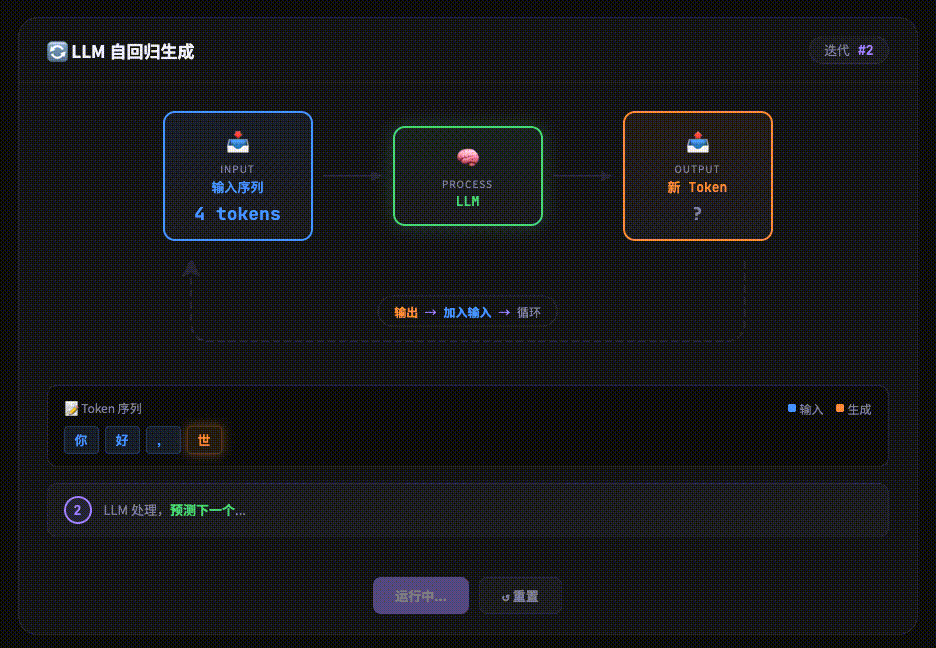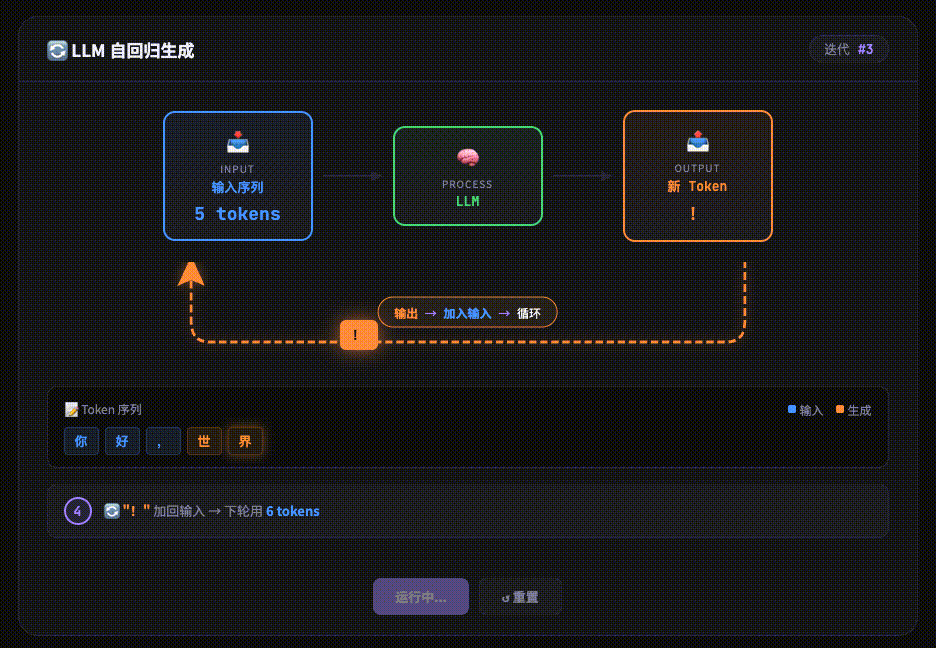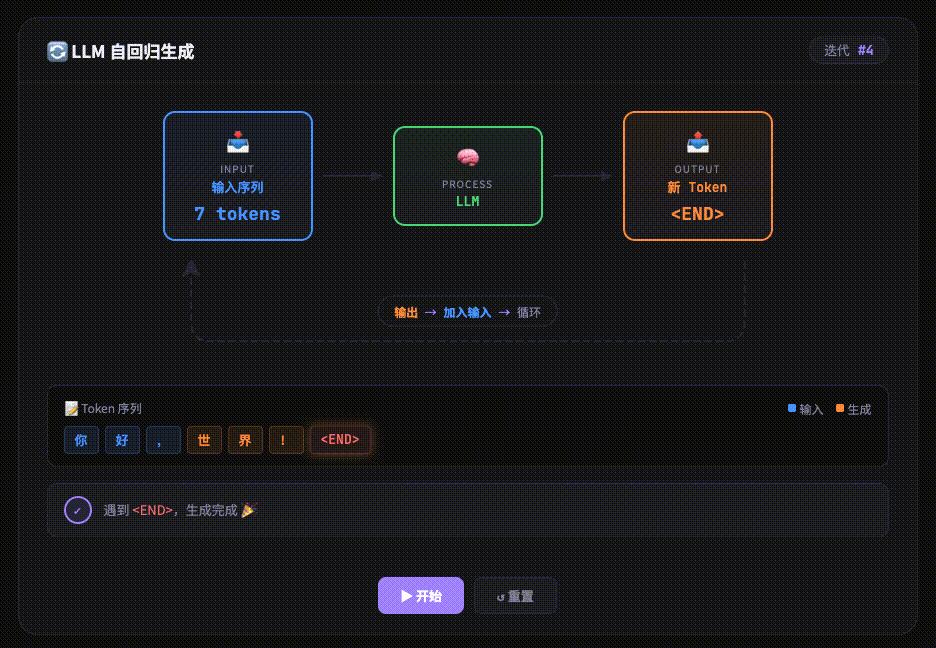
实现原理
了解了之前这些背景知道,我们就可以解释 Cached Token 的技术原理了。
在 LLM(大语言模型)推理过程中,Cached Token 指的是对 KV Cache (Key-Value Cache) 的复用技术。
Transformer 架构是自回归的。在生成回答(Decode 阶段)之前,模型必须先 “理解” 输入(Prefill 阶段)。这个 “理解” 过程涉及大量的矩阵运算,计算出每个 Token 的 Key 和 Value 向量(即注意力机制的中间状态)。对于长文本(如 RAG 场景中的大量文档),每次请求都重新计算这些 KV 向量是巨大的算力浪费,这就是 Cached Token 解决的问题。
实现机制:
- 存储状态: 当模型第一次处理前缀(Prefix,例如 System Prompt 或长文档)时,将计算好的 KV 向量驻留在 GPU 显存(VRAM)或层级存储中。
- 前缀匹配: 当新的请求进来,如果开头部分(Prefix)与缓存中的 Token 完全一致,推理引擎(如 vLLM, SGLang)会直接加载已计算好的 KV 状态,跳过 Transformer 的前向计算过程。
- PagedAttention: 现代推理引擎(如 vLLM)使用类似操作系统内存分页的技术(PagedAttention)来管理这些缓存块,解决了显存碎片化问题,允许多个请求共享同一份物理显存中的 Prompt 数据
想省钱,要这样用
要在应用里稳定吃到 cached tokens(prompt caching),核心就三句话:
- 提示词要够长(通常 ≥ 1024 tokens 才会开始命中)
- 前缀要 “完全一致”(缓存按 “最长相同前缀” 命中,哪怕一个字符 / 空格不同都可能全失效)
- 把不变的放前面,把变化的放后面(指令/工具/示例/长背景固定;用户问题、检索结果、时间戳等放末尾)
所以我们要从设计上进行些调整才能够 “省钱”:
设计 “可缓存的前缀结构”,把 prompt 拆成两段(非常重要):
可缓存前缀(Static Prefix):system 指令、角色设定、规范、few-shot 示例、工具定义、长期不变的背景资料
动态尾部(Dynamic Tail):用户输入、RAG 检索内容、实时数据、时间戳、request_id、实验开关等
多轮对话 / Agent 的注意事项
消息数组要 “只追加,不改历史”:如果你为了省 tokens 把历史消息重排、压缩、或插入到中间,很可能导致前缀变了 → cache miss。
工具定义(tools)必须完全一致,顺序也要一致,否则工具部分也进不了缓存前缀
“
OpenAI Cookbook 直接建议: 静态内容放开头,可变内容放结尾;工具 / 图片也一样。
常见 “踩坑清单”
- 把时间戳 / 随机 ID 放在 system 开头:每次都变,等于主动让缓存失效。
- JSON 序列化不稳定:同一份 tool schema 如果字段顺序、空格、换行变化,token 序列可能变 → miss(所以建议对 system/tools 做 “规范化输出”,并保持完全一致)
- 指令在每次请求里微调一两个字:看似小改动,可能让前 1024 tokens 出现差异,直接从 “高命中” 变成 “全 miss”。Azure 文档 明确说 “前 1024 tokens 一个字符差异就会 miss”
缓存能活多久 / 怎么保持
不同厂商策略不同,但你可以这么理解:缓存不是永久的,要么靠短时间内重复使用,要么使用更长的保留策略(如果提供)。
- Azure OpenAI:缓存通常在空闲 5–10 分钟清理,并且最晚 1 小时内会移除;还支持 prompt_cache_key 帮你影响路由提高命中,但同一前缀 + key 如果请求过猛(文档提到约 15 RPM 量级)可能溢出导致命中变差。
- OpenAI:提供 prompt_cache_retention(默认 in_memory,也可选 24h 做更长保留),并说明缓存的是 attention prefill 产生的 KV tensors,原始提示文本不以同样方式持久化。
- Anthropic Claude:通过在特定内容块上标注 cache_control 来启用 / 控制缓存(用法是显式的)。
落地建议
给开发:
- 把系统提示词拆成 STATIC_SYSTEM_PROMPT(长期不变)+ DYNAMIC_CONTEXT(每次变)
- 所有请求都按固定模板拼:STATIC_SYSTEM_PROMPT + tools + (可选固定示例) + DYNAMIC_CONTEXT + user_question
- 总结来说:把静态内容(System Prompt、Tools)置顶,动态内容(User Query、Time)置底;确保 JSON 序列化顺序固定;针对 Claude 需手动加标记;监控 “缓存命中率”(Cache Hit Rate)指标,确保不是在做负优化。
给产品:
- 缓存能让长文档分析、多轮对话变得极快且便宜。设计功能时,尽量让用户基于一个 “固定的背景”(如上传一份文档后针对该文档多次提问),这最能利用缓存优势。
实际应用场景
- 多轮对话 (Chatbot): 用户和 AI 聊了 20 轮,第 21 轮时,前 20 轮的历史记录就是 “Cached Token”。不用每次都重算历史记录,响应更快。
- 文档问答 (RAG): 上传一本 PDF 法律合同。只要文件没变,第二个问题开始,AI 就不需要重新处理这份文件
- 代码助手 (Coding Agent): 将整个项目的代码库结构作为 Prompt 发送给 AI。这部分内容巨大且变动不频繁,非常适合缓存。
- 角色扮演 / Agent: 复杂的 System Prompt(设定 AI 的性格、规则、工具定义)通常很长且固定,缓存后每次调用都极快