
2025 年终于翻篇了。
回看过去这一年,全球 AI 行业简直是在 “神仙打架”。从美国的 OpenAI 到中国的各大厂,大家都在疯狂迭代,没有谁敢在舒适圈里躺平。 但在如此窒息的竞争节奏下,DeepSeek 依然是个异类。 无论是综合能力极强的 V3,还是推理模型 R1,亦或 Coder 系列,DeepSeek 总能以一种 “不仅强,而且便宜得不可思议” 的姿态出现。
大家都在研究他们的显卡利用率,研究他们的 MoE 路由。 然后 2025 年的最后一天,DeepSeek 又默默丢出了一篇名为 mHC 的论文 。

看完这篇论文,我才真正理解了 DeepSeek 这个生态为何能爆发得如此之快。 这不仅仅是一项技术优化,更是一种敢于挑战权威和规则的勇气。
当大多数团队还在常规的架构上修修补补时,DeepSeek 的研究员们已经把手术刀伸向了模型最基础、也最敏感的 “血管”—— 残差连接。 这是一次极高风险的赌博:他们为了追求极致的模型容量,选了一条理论上极不稳定的路,用一道优雅的数学公式,硬生生把这条路给铺平了。
DeepSeek 最可怕的不是某一个具体的模型,而是他们对底层数学原理的掌控力。正是这种能力,支撑起了从 R1 到 V3 这一条条产品线的快速突破。DeepSeek 的护城河,比我们想象的还要深。
即使是 GPT-5,也逃不掉的 “老祖宗之法”
在深度学习领域,网络越深,越需要一条 “直通车”。残差(ResNet)就是那条车道:不一定唯一,但几乎是默认选项。
不管是 GPT-5 还是 Gemini 3,扒开代码,核心逻辑都长这样:
⚡ 代码片段下一层的输入 = 上一层的输出 + 这一层的变化
这叫恒等映射。它像一条笔直的管道,保证信号能安全地流到第 100 层。从何凯明的《Deep Residual Learning for Image Recognition》开始,十年了,哪怕是最激进的架构师,也不敢轻易动这个地方。
但创新的接力赛其实已经开始了。 2024 年 9 月,字节跳动(ByteDance) 的 Seed 团队率先搞出了一个叫 Hyper-Connections (HC) 的理论 (https://arxiv.org/abs/2409.19606)。 这帮人的脑洞很大:为什么要死守着原封不动?把信号打散、揉碎,多搞几条路混合在一起,模型的脑容量不是更大吗?
不得不说,字节跳动这个想法很有前瞻性,但在当时来看,它更像是个 “半成品”。 因为它有个致命缺陷:极其不稳定。对于追求稳妥的大模型团队来说,这种 “理论收益高、实际风险大” 的方案,通常看完论文就扔进收藏夹吃灰了 —— 毕竟谁也不想拿几千万的显卡去赌一个可能会炸的模型。
但 DeepSeek 的工程师思路不太一样。 他们看完论文,没盯着风险看,而是死死盯着那个 “收益”。 他们觉得,这玩意儿虽然现在会炸,但原理没毛病。只要能想办法给它装个 “刹车”,它就是跑得最快的。 于是,他们做了一个非常务实的决定:把这个友商没跑通的架构捡起来,自己动手修好,然后真的用到了自家的大模型上。
但这毕竟是给高速行驶的赛车换引擎,稍微手抖一下就是车毁人亡。DeepSeek 真的稳住了吗?
压力测试
DeepSeek 为了证明自己的方案(mHC)到底稳不稳,他们在 27B 的模型上,用 mHC(灰线) 和 HC(蓝线)做了个对比测试:
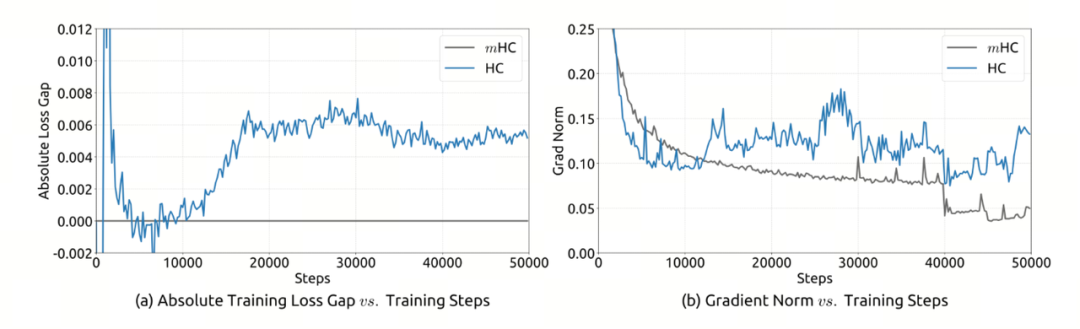
大家注意看这两条线的走向。
●左图 (a) :蓝线(HC)的 Loss Gap 在 12000 步之前,它还在 0 附近徘徊;但过了 12000 步,蓝线突然旱地拔葱,直线飙升。
●右图 (b) :蓝线(HC)的梯度在 12000 步左右突然开始疯狂抖动,全是毛刺。
HC 在训练进行到 12000 步时,梯度范数(Grad Norm)突然开始剧烈震荡。 这意味着什么?意味着模型内部的信号传导出问题了,每一次参数更新都在 “乱指路”。这就好比赛车开到 200 码时,方向盘突然开始疯狂抖动,车身剧烈摇摆。结果就是车彻底撞毁了,因为右边的梯度乱了,左边的 Loss 自然就崩了。 蓝线(Loss Gap)的瞬间飙升,就是梯度失控的直接后果。模型不仅学不到新东西,反而把之前学到的也吐出来了。这就是典型的 “训练崩溃”。
再看那条灰线,对比简直不要太强烈。 无论右边的梯度怎么波动,加了数学约束的 mHC(灰线)始终把梯度按得死死的,平滑得像条直线。 因为内部稳住了,外部的表现自然就稳了 —— 所以在左图中,它的 Loss 始终贴着基准线走,完全没有出现暴涨。
DeepSeek 用这组图证明了: HC 的崩溃不是偶然,而是必然(右图的梯度震荡)。 而 mHC 成功的原因是数学约束带来的平稳。
3000 倍的隐形 “通胀”
既然灰线(mHC)在结果上已经赢了,那我们必须得搞清楚:蓝线(HC)到底是怎么输的?
DeepSeek 的工程师对模型内部的信号做了一次深度 CT 扫描。他们想看看,信号在网络里传导时,到底是被放大了还是缩小了。
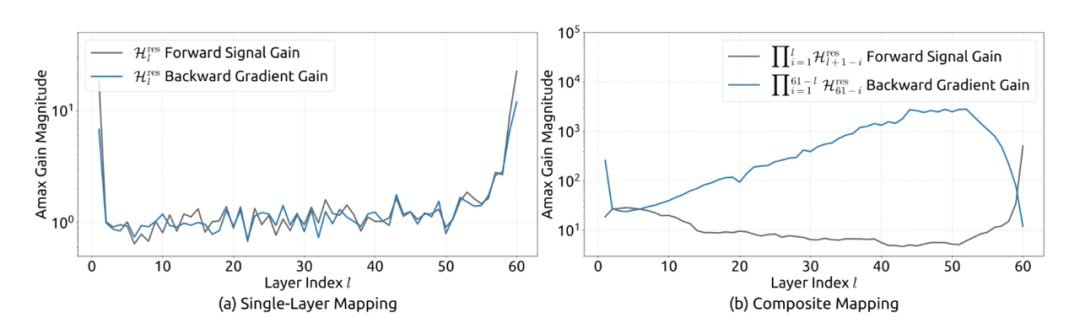
这是一组极具欺骗性的对比。
●左图 (a) 看单层:看起来很正常。每一个单独的层(Single Layer),信号增益都在 1 附近波动,稍微大一点点而已。
●右图 (b) 看叠加:灾难发生了。当几十层叠加在一起(Composite Mapping),那个微小的 “一点点” 被指数级放大,蓝线直接飙到了天际。
这两张图揭示了 HC 架构最隐蔽的致命伤。如果你只看单层(左图),你会觉得 HC 没啥大毛病。它的信号放大倍数也就 1.1、1.2 的样子。很多工程师看到这就放心了:“这不挺稳的嘛?” 但别忘了,大模型动不动就是 60 层起步。真正的恐怖在右图。 当信号穿过 60 层网络时,那些看似无害的 1.1 倍被连续相乘。 1.1 的 60 次方=304。 如果是 1.2 呢?结果是 56000。
图中蓝线(HC)清晰地记录了这个失控的过程:在深层网络,反向传播的梯度增益(Backward Gradient Gain)最高飙到了 3000 。这是什么概念? 正常模型的信号增益应该是 1(能量守恒)。 但蓝线飙到了 3000。这就好比你在第一层对模型耳语了一句 “你好”,传到第 60 层时,变成了 3000 个广场舞大喇叭同时贴着你耳朵尖叫。
在这种噪音下,梯度瞬间爆炸,前面提到的梯度震荡就是这么来的。这简直是个死局: 想聪明(用宽连接),就会爆炸;想稳定(用老架构),就得忍受平庸。
一道 “小学数学题” 救场
面对这个死局,DeepSeek 的解法简单得很。 既然信号会因为连乘而无限放大,那就给它加个 “会计”,强制它遵守能量守恒。
他们引入了一个概念:双随机矩阵(Doubly Stochastic Matrices)。 名字很唬人,但本质极简。它其实就是强制模型做 “加权平均” 。
DeepSeek 给那个狂暴的混合矩阵定了一条死规矩: “不管你怎么折腾,你每一行的权重加起来必须等于 1,每一列加起来也必须等于 1。”
这就是数学的魔力: 你想想,如果你计算一组数的 “平均值”,结果有可能超过最大值吗?绝对不可能。DeepSeek 证明了:这种矩阵就算乘上一万次,它依然守规矩,永远不会让能量溢出(信号范数 ≤ 1)。
效果立竿见影。看看这组热力图对比,这就是 “无序” 和 “有序” 的区别:
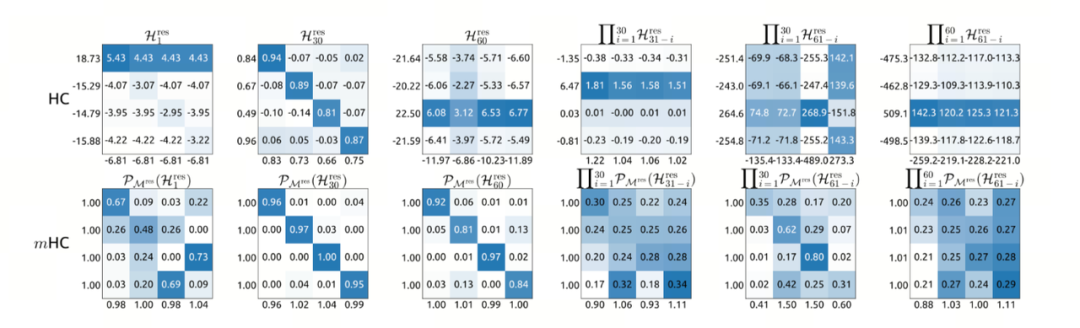
●第一排是失控的 HC 方案,那些深蓝色的色块代表数值极大的异常点(有的飙到了 268.9,有的跌到 -255.2),整个矩阵一片混乱
●第二排是加了 “紧箍咒” 的 mHC 方案,颜色立刻变浅且均匀,所有数值被死死锁在 0 到 1 之间,井井有条。
那个飙到 3000 倍的信号核爆,被瞬间按回了 1.6 倍 。 面对 3000 倍的信号核爆,DeepSeek 没有用工程上的 “补丁”(比如强行截断数值),而是从数学底层定义了一个新的流形(Manifold)。这道 “数学题” 的真面目,其实就是著名的 Birkhoff 多面体投影。
生态爆发的秘密
如果你觉得这只是个学术实验,那就太天真了。注意看原文中这句容易被忽略的话:
This conclusion is further corroborated by our in-house large-scale training experiments
“这一结论得到了我们内部大规模训练实验的进一步证实。”
这句话翻译过来就是:虽然这篇论文展示的是 27B 小模型的实验数据,但我们在内部那个庞大的模型矩阵(包括大家熟知的 V3 等)身上,早就验证过这一套了。
这就解释了为什么 DeepSeek 总能比别人 “多算一步”: 当行业还在卷应用层时,他们已经在底层的连接方式上,用 6.7% 的额外计算时间 ,换来了一个容量更大、表达更强、且绝不炸膛的通用架构。正是这种底层技术的溢出,才支撑起了 DeepSeek 从 V3 到 R1 再到 Coder 的全线开花。
另外,离春节不远了,你应该知道我要说什么。哈哈
总结
读完这篇论文,我最大的感受是:DeepSeek 赢的不是显卡数量,而是对数学的直觉。
如果非要用一句话总结这篇论文,我想引用一位网友的神评论:
以前的模型像个 被牵着手的乖孩子(ResNet),安全但学不会跑。 后来大家撒手让它跑,结果它是 撒手没,跑两步就疯了(HC)。
DeepSeek 做的事,就是给孩子画了个 圈(双随机矩阵)。 不管你在圈里怎么跑、怎么翻跟头都行,但绝对不许出圈。
于是,孩子既学会了跑,又没跑丢。
当硅谷还在比拼谁的 H100 更多时,DeepSeek 用一道数学题证明了: 有时候,约束才是最大的自由。
附录
●DeepSeek 的跨年 “交卷” 之作:https://arxiv.org/pdf/2512.24880
●字节跳动的大胆尝试:https://arxiv.org/abs/2409.19606
●不可动摇的 “老祖宗”:https://arxiv.org/abs/1512.03385
●那道神奇的 “数学题”:Sinkhorn, R. (1964). A Relationship Between Arbitrary Positive Matrices and Doubly Stochastic Matrices.