
LLM 采样参数:Top-k vs Top-p (一分钟极速版)
AI 说话不是确定的,它是按概率“猜”词。这俩参数就是防止它乱猜的过滤器,用来控制抽签范围与随机程度
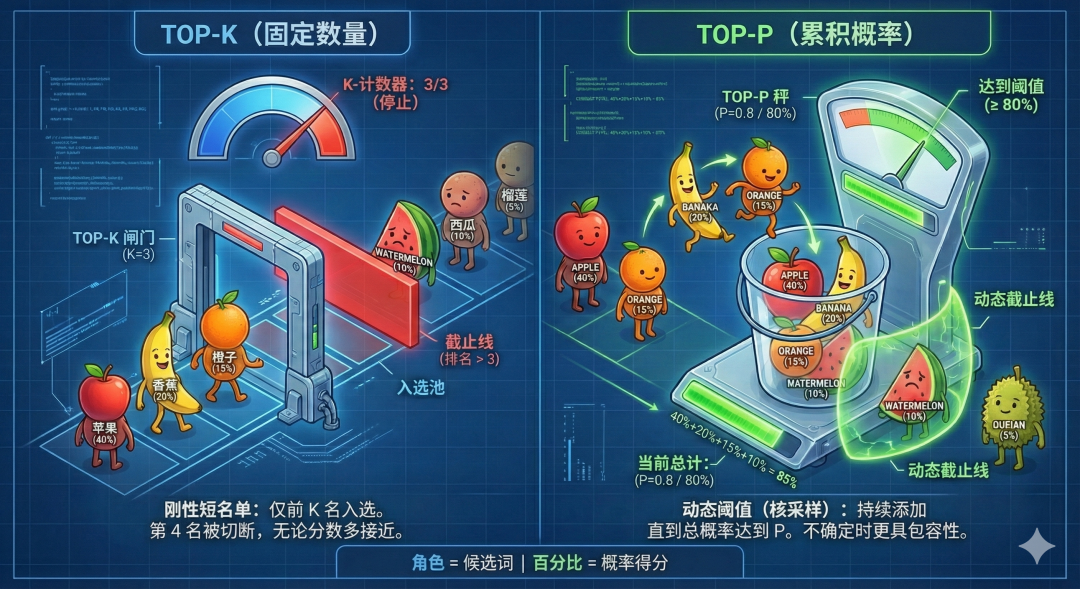
1. 核心区别
Top-k (死板排名):只取前几名
●逻辑: “不管大家分差多少,我只要前 10 个人。”
●缺点: 容易把合理的第 11 名切掉,或者把离谱的第 10 名选进来。它是硬截断。
Top-p (动态质量):只取靠谱的
●逻辑: “不限人数,但这些人的成功率加起来要达到 90%。”
●优点: 确定时它圈子小(严谨),不确定时它圈子大(丰富)。它是软截断。
2. 怎么调?
基本原则
●一次只动一个:可以先动 top_p,效果稳定后再考虑叠加。
●从默认值附近小步调整,比一上来极端值(如 top_p=0.1)更稳
●不要试图寻找“完美通用参数”,根据场景来选择
场景 A:要严谨 (代码、数学、事实问答)
目标: 别废话,别幻觉,要精准。
设置:
●Top-p: 0.7 ~ 1.0(多数时候先别动,或小幅收敛)
●Top-k: 视平台而定;如果能设置把它当作 “垃圾词兜底上限”,例如 20 ~ 100,不要盲目追求很小
●Temperature: 0.0 ~ 0.3(越低越稳定)
场景 B:要人味 (写文案、聊天、头脑风暴)
目标: 词汇丰富点,别像个复读机。
设置:
●Top-p: 0.9 ~ 1.0 (主力参数,保留长尾可能性)
●Top-k: 40 ~ 200 (用来剔除极低概率的垃圾词)
●Temperature: 0.7 ~ 1.2 (更随机、更发散)
3 调参经验
官方的一些文档对这些限制写的比较清楚,比如:
●OpenAI 官方文档反复强调: 一般只调整 temperature 或 top_p 其中一个,不要两个一起乱调。
●Gemini 3 官方文档明确写了:强烈建议 temperature 保持默认 1.0;把温度调到 1.0 以下可能导致循环或性能下降,尤其在复杂数学 / 推理任务
●在 Vertex AI 的 Gemini 3 Flash 页面里:topK 是 固定为 64(你并不能随便设 40–100)
所以建议:
●先只调一个:优先从 temperature 或 top_p 选一个小步微调
●用 Gemini 3 时:先别动 temperature,保持 1.0,需要收敛再动 top_p/top_k