很多人第一次用龙虾时都会有一个直觉:
“聊久了,它应该会忘吧?”
这个直觉没错。模型的上下文窗口是有限的,不可能把几万句对话永远都放在眼前。
但你会看到系统表现得像这样:
●不切 thread,也能连续推进一个长期任务
●记得你之前的偏好、决定和待办
●对话很长后也不会突然“失忆”
这篇文章讲清楚它背后的工程逻辑。
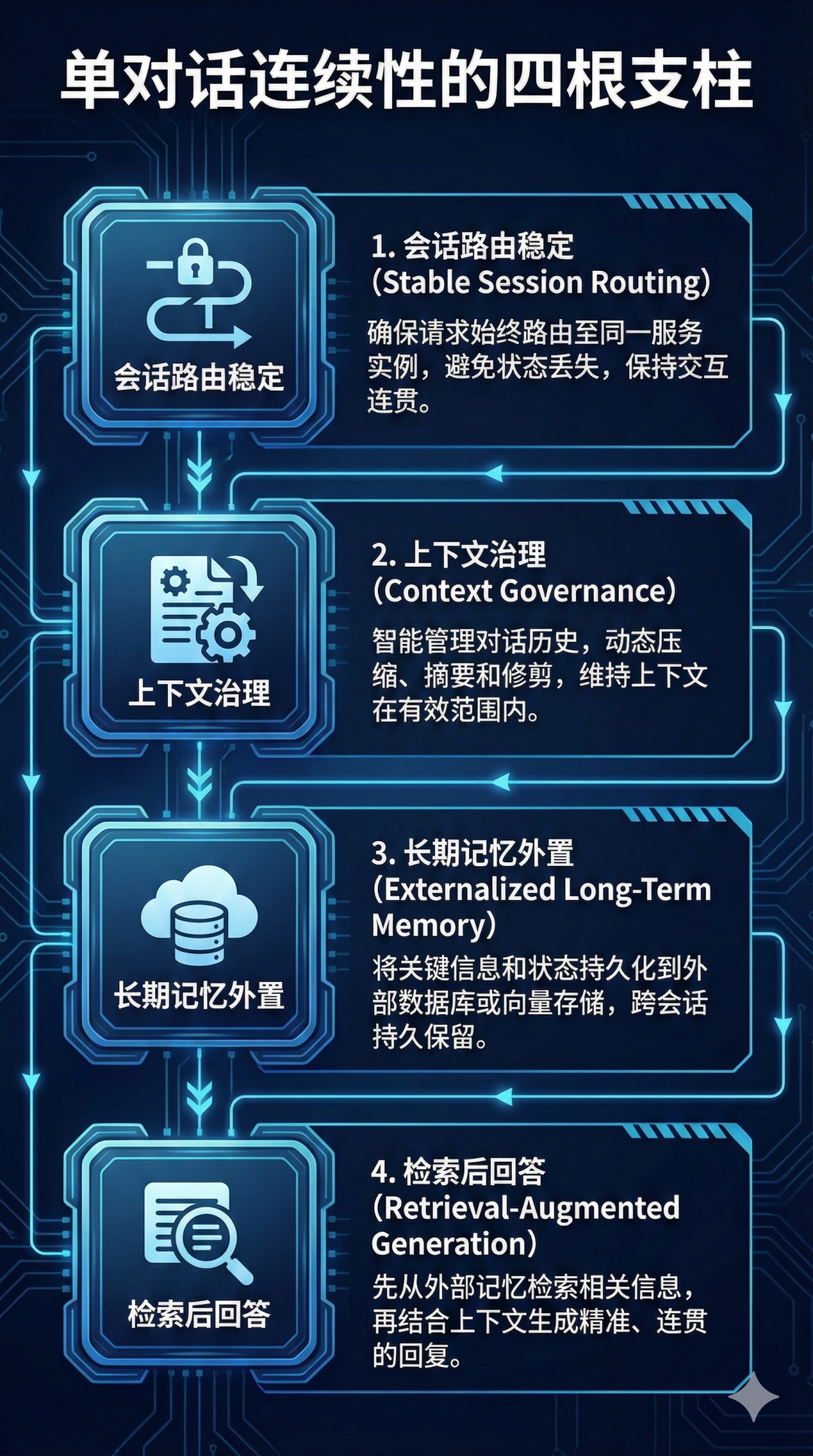
先讲结论:它靠的不是“超大脑子”,而是“分层记忆”
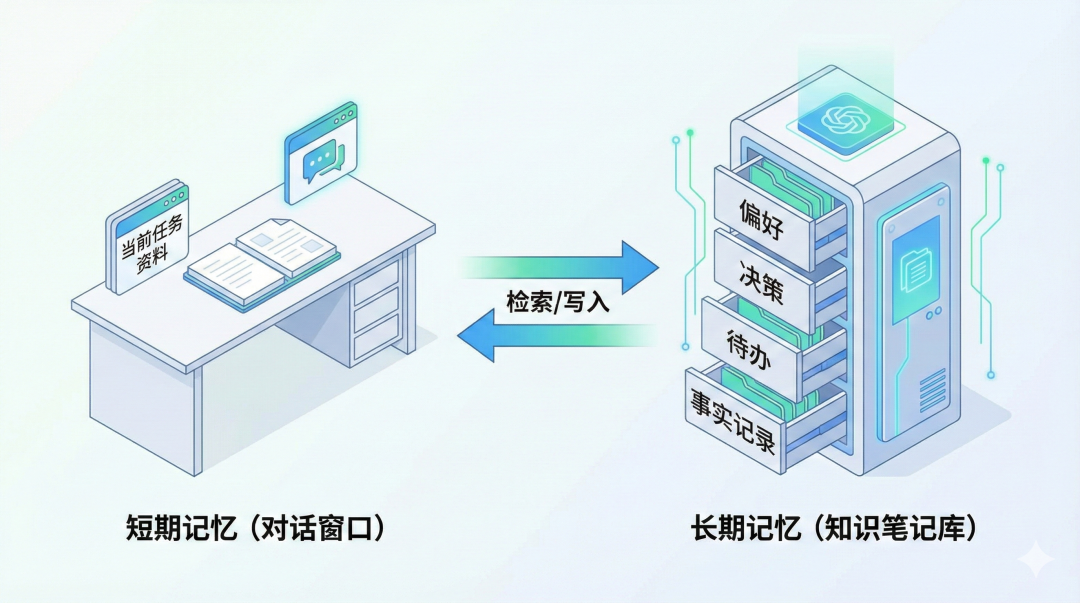
一个能长期连续工作的 AI 助手,通常不是在“硬记全部聊天记录”。
它更像一个做事很靠谱的人:
●脑子里保留当前任务所需的短期信息
●把长期重要信息记到笔记本
●需要时再去查笔记,而不是靠猜
所以关键不是“记住一切”,而是“该记哪里、什么时候记、怎么取回来”。
1 为什么“一个对话一直聊”不会乱
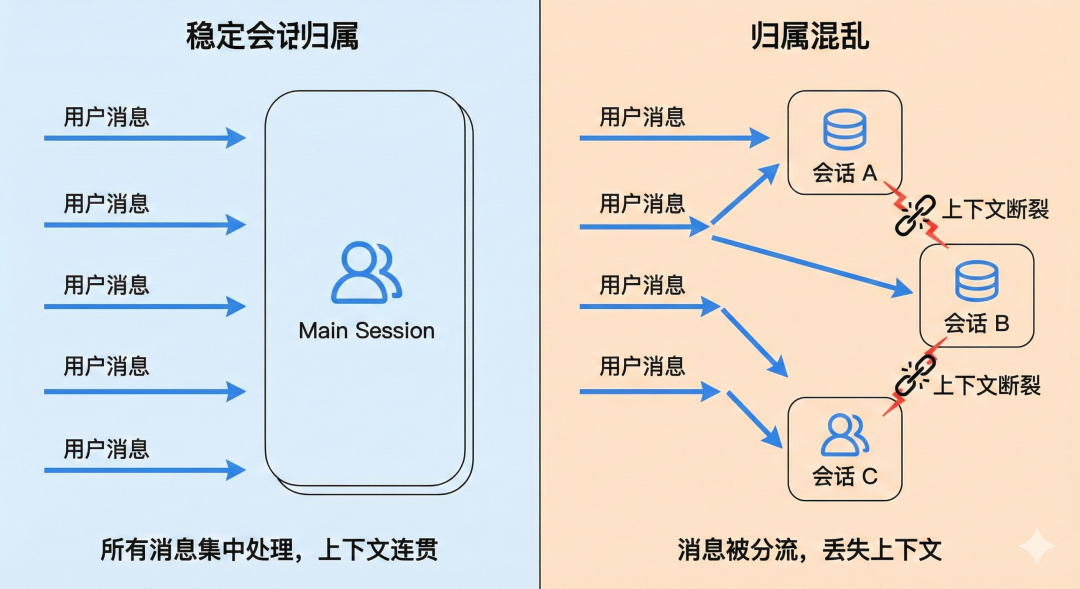
要做到这件事,第一步不是 memory,而是“会话归属稳定”。
你可以把它理解成:
●每条新消息进来,系统都要先回答“这条消息属于哪条连续会话?”
●只要这个归属规则稳定,用户就会感受到“我一直在同一个对话里”
如果归属不稳定,会发生什么?
●今天这句进 A 会话
●明天那句进 B 会话
●用户感觉就是“它忽然不记得了”
所以,连续性首先是路由问题,不是模型智商问题。
2 长对话为什么不会把模型撑爆
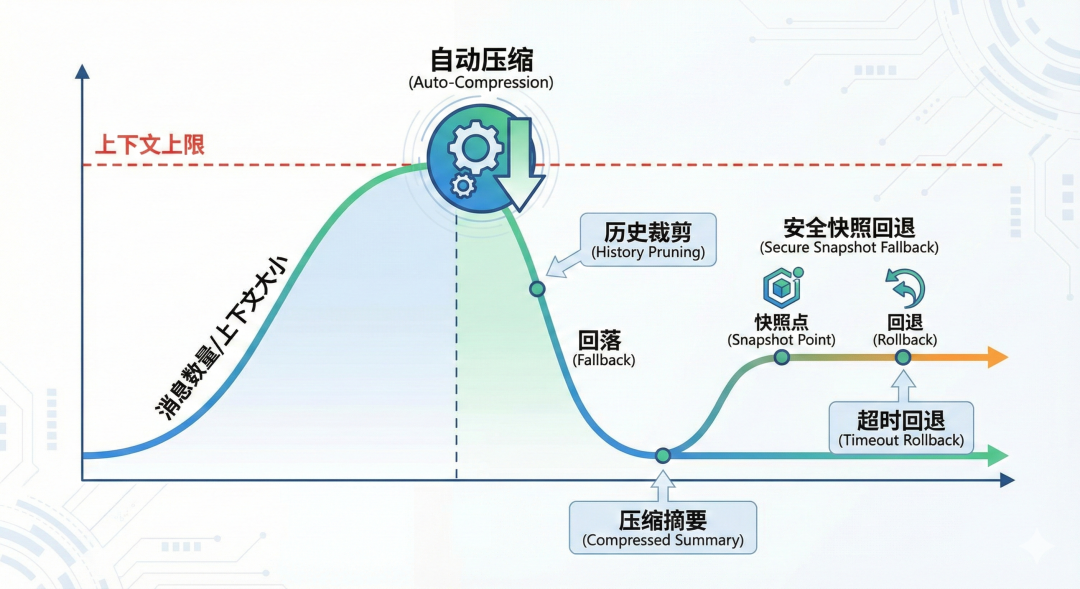
即使会话归属稳定,也还有第二个难题: 上下文窗口会满。
成熟系统会做三件事:
1.限制最近历史 :只保留与当前问题最相关的“最近若干轮”。
2.自动压缩旧历史(compaction):把很长的旧对话压成“结构化摘要”,保留关键决策和状态。
3.失败兜底:如果压缩中断或超时,回退到安全快照,不让会话进入半坏状态。
这和人工作很像:
●桌上只放当前要处理的文件
●老文件归档成摘要
●归档出错就先回到上一个可用版本
3 真正关键:Memory 不是“备份聊天记录”
很多人把 memory 理解成“把聊天全存起来”。
这不够。
真正可用的 memory 系统至少要回答 4 个问题:
1.存什么
2.什么时候存
3.怎么找
4.找到后给模型喂多少
1 存什么
不是所有对话都值得永久存。
通常要存的是:
●稳定偏好(口味、风格、边界)
●已确认决策(做过什么决定、为什么)
●长周期任务状态(进行到哪一步)
●关键事实(日期、人物、账号约束)
2 什么时候存
好的系统会在“即将压缩上下文”前触发一次静默写入(memory flush):
●先把耐久信息落盘
●再去压缩历史
这样就不会因为压缩导致关键信息漂掉。
3 怎么找
常见做法是“混合检索”:
●关键词检索(你说了某个明确词)
●语义检索(你换了说法但意思相近)
然后把结果融合排序,优先给出最相关片段。
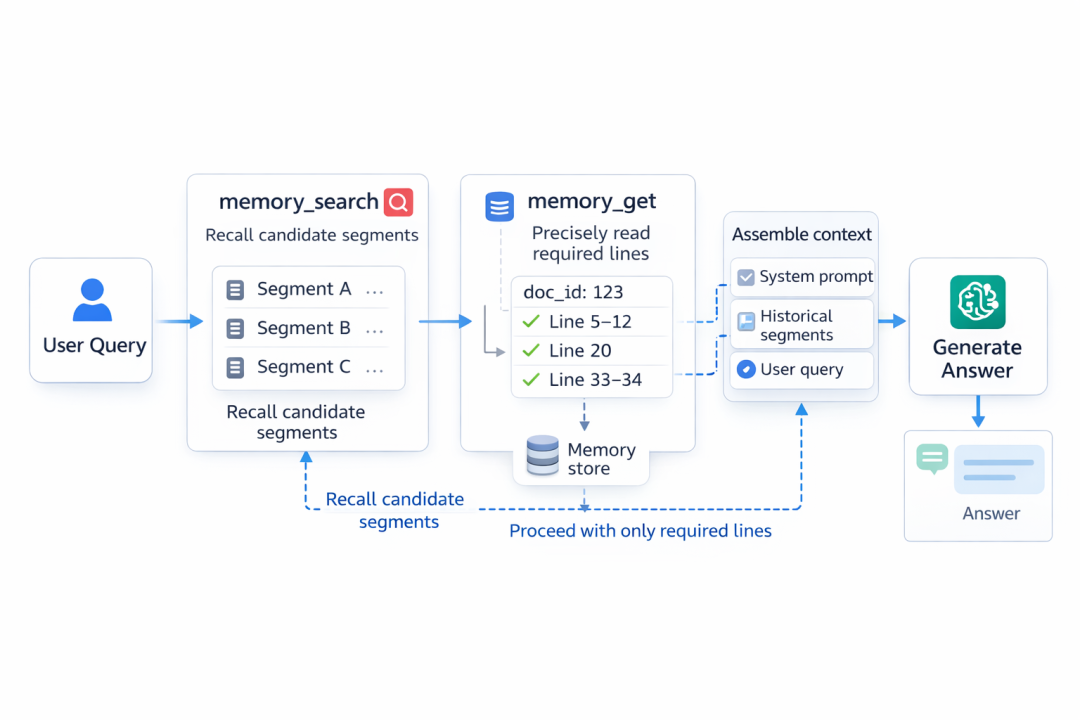
4 找到后喂多少
成熟系统不会把整本记忆库都喂给模型。
而是两步:
●先 search,拿候选
●再 get,只读取必要行
这样上下文干净,成本低,稳定性高。
4 一个通俗例子:为什么它看起来“真的记得你”
假设你连续三周都在推进“装修计划”。
第一周你说:
●不要开放式厨房
●预算上限 20 万
第二周你说:
●客厅采光优先
●工期希望 3 个月内
第三周你问:
“按我们之前的原则,周末我要见设计师,该先确认哪三件事?”
如果系统只靠当前窗口,它可能忘掉第一周。
如果它有分层记忆:
●会话里保留最近讨论
●长期记忆里有你前两周沉淀的偏好与约束
●回答前先检索再取关键片段
最终回答会更像“基于你的长期上下文”,而不是一次性临场发挥。
5 一个点看懂工程质量
为什么 memory flush 不会乱触发,也不会重复触发。
很多系统的问题不是“没有 memory flush”,而是“flush 触发太随意”,结果变成:
●该写入时没写
●不该写入时反复写
●一次 compaction 周期里重复写同样内容
OpenClaw 在这个点上做得很精细,核心是三段式控制。
1 先算阈值,只在快到上限时触发
在 src/auto-reply/reply/memory-flush.ts 里,触发条件本质是:
⚡ text片段//当 totalTokens >= threshold 时,才考虑 flush threshold = contextWindow - reserveTokensFloor - softThresholdTokens
这让 flush 从“拍脑袋触发”变成“窗口压力驱动”。
2 再做幂等控制,一轮 compaction 只 flush 一次
同一文件里还有一个关键判断(shouldRunMemoryFlush):
●当前会话有 compactionCount
●上一次 flush 记录了 memoryFlushCompactionCount
●如果两者相等,说明本轮已经 flush 过了,直接跳过
这一步非常工程化。它不是靠“感觉上不会重复”,而是靠状态位严格去重。
3 触发位置放在主回合之前,保证先落盘再压缩
在 src/auto-reply/reply/agent-runner.ts 中,runMemoryFlushIfNeeded() 被放在主回合执行前。
src/auto-reply/reply/agent-runner-memory.ts 里会进一步检查:
●不是 heartbeat
●不是某些不适合的 provider 模式
●工作区可写(只读沙箱不写)
通过后才跑 flush 回合,并在结束后把这两个字段写回 session store:
●memoryFlushAt
●memoryFlushCompactionCount
对应会话结构字段定义在 src/config/sessions/types.ts。
它把“写记忆”做成了可证明的状态机,而不是一段“偶尔执行的辅助逻辑”。
这就是为什么它在长对话压力下还能稳定,不会一边压缩一边把记忆策略搞乱。
6 这套设计的代价与边界
这套方案很强,但不是魔法。
优点
●单对话体验稳定
●长任务可持续
●对“历史事实”更不容易胡编
代价
●系统更复杂(路由、索引、压缩、检索都要配合)
●记忆质量取决于写入质量
●参数没调好会影响召回质量或成本
现实边界
●记忆不是 100% 真相机,仍需要来源校验
●高风险场景要保留“我不确定”与“可追溯引用”机制
7 如果你在设计类似系统,最值得抓住的三件事
1.先保证会话归属稳定
●不要一上来就追求复杂 memory,先让“同一个人同一类对话”稳定落在同一会话。
2.把长期记忆外置
●不要指望模型窗口长期记住一切。把耐久信息写进可检索存储。
3.强制“先检索再回答”
●在系统策略层明确约束:涉及历史事实必须先查 memory。
●这是把“看起来聪明”变成“工程上可靠”的分水岭。
结语
一个真正能长期协作的 AI,对外看起来像“记性很好”。
但从工程上看,它做的是更朴素、也更难的一件事:
把“记住”拆成可管理的流程。
●谁的会话
●当前保留什么
●长期写入什么
●回答前查什么
当这四件事同时做好,用户才会得到那种自然体验:
“我没有切 thread,但它一直跟得上我。”