最近跟业界一些朋友交流,不少公司正在做内部软件开发的 AI 自动化流程系统,正好这两天,OpenAI 在 GitHub 上低调开源了一个很值得认真看的项目:Symphony。
如果只看名字,你很容易把它理解成“又一个多 Agent 编排框架”;但只要认真读完 README、SPEC.md 和参考实现里的 WORKFLOW.md,你会发现它真正想解决的,根本不是“让 AI 会写代码”,而是另一件更大的事:
如何把软件研发中的“工作”,交给一套可以持续运行、可隔离、可调度、可回收、可观测的系统去推进。
这就是 Symphony 最重要的定位。官方原话非常值得细品:
它会把项目工作转成 isolated, autonomous implementation runs,让团队从“监督 coding agents”转向“管理 work”。README 里的 demo 也很直白:Symphony 盯着 Linear 看板拿任务,拉起 agent 处理 issue,回传 CI 状态、PR review 反馈、复杂度分析和 walkthrough 视频,最后在被接受后安全落 PR。
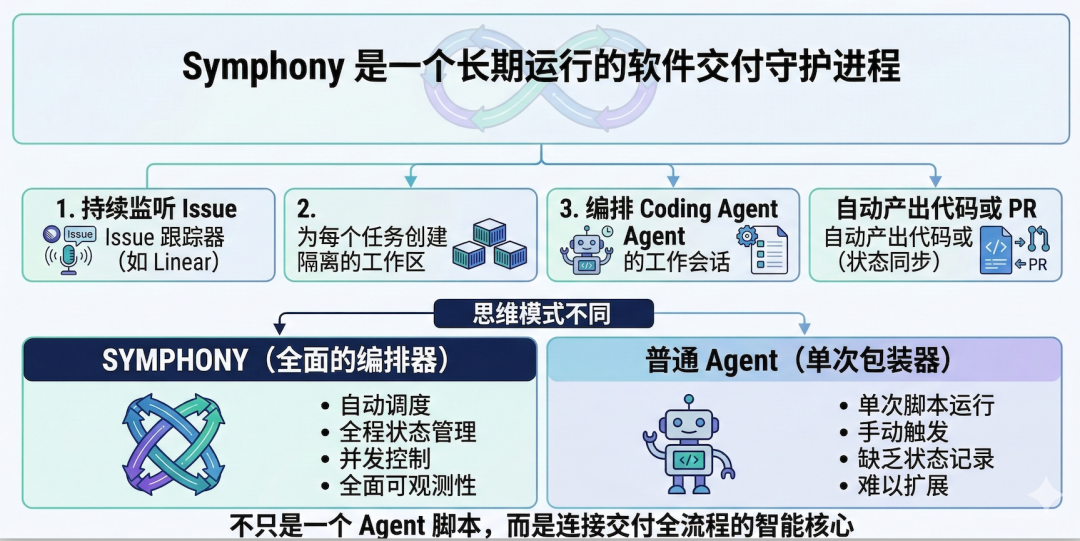
很多人第一次看到这里,会本能地把它和 Copilot、Cursor、Claude Code 之类工具放在一起比较。但我觉得,真正准确的比较方式不是“谁代码写得更强”,而是:谁更接近一个面向研发现场的执行系统。 Copilot 类产品解决的是“我写代码时,旁边有个聪明助手”;Symphony 想解决的是“我有一堆 issue,能不能让系统自己取单、分配环境、拉起 Agent、推进状态、处理失败、保留上下文,并把结果交回给我验收”。这已经不只是“辅助编码”,而是开始触碰软件交付流水线本身。
一、Symphony 到底是什么?
从 SPEC.md 看,Symphony 的定义非常清晰:它是一个 long-running automation service。在当前规范版本里,它会持续从 issue tracker 读取工作(v1 里明确是 Linear),为每个 issue 创建独立 workspace,并在这个 workspace 里运行 coding agent session。规范还特别强调了它要解决的四类问题:
1.把 issue 执行变成守护式工作流
2.把每个任务隔离到独立 workspace
3.把工作流策略放回 repo 内的 WORKFLOW.md
4.以及为多任务并发运行提供足够的 observability。
这段定义很重要,因为它一下子把 Symphony 和大量“Agent Demo”拉开了距离。它不是一个写几个 prompt、串几个工具的 toy project,也不是一个单轮任务脚本。它有轮询、有调度、有状态机、有重试退避、有 workspace 生命周期、有运行期事件、有恢复逻辑。换句话说,它的思维方式更像一个 orchestrator,而不是一个单纯的 agent wrapper。
更关键的是,SPEC 还专门写了一个“重要边界”:Symphony 是 scheduler/runner 和 tracker reader。这句话很克制,也很专业。它的意思是,Symphony 的职责重点不是替你定义所有业务流程,而是负责任务编排、执行承载和状态协调;而 ticket 状态变更、评论、PR 链接等写操作,通常还是由 coding agent 借助工具在运行时完成。也就是说,它不是一个万能 PM 系统,而是一层面向软件交付的 agent orchestration 壳。
二、它为什么比“会写代码”更进一步?
因为真正麻烦的,从来不是 AI 能不能生成一段代码,而是几十个任务并行推进时,系统怎么不失控。
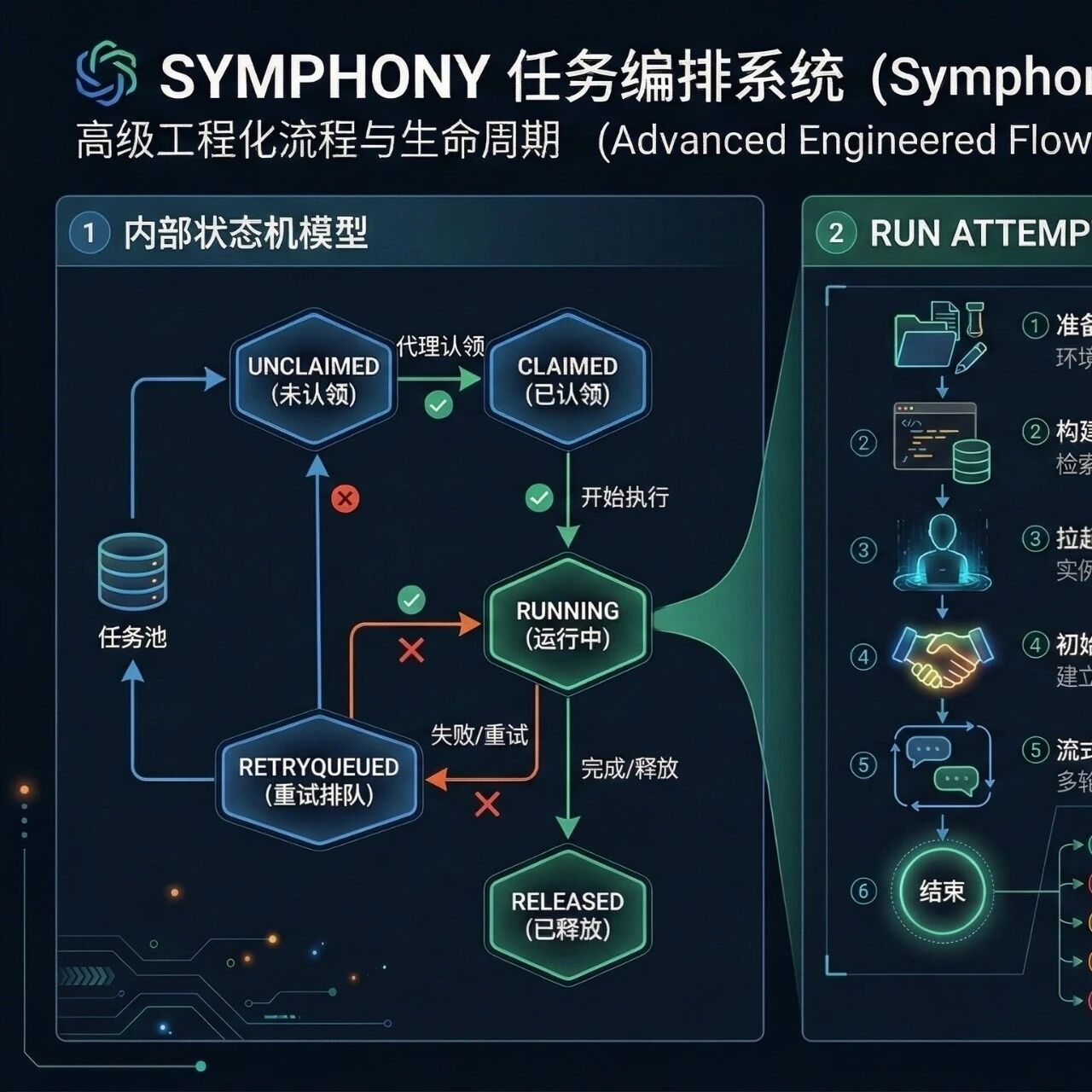
Symphony 在这方面做得非常工程化。它有明确的内部状态机:Unclaimed、Claimed、Running、RetryQueued、Released。它还定义了 run attempt 的阶段:准备 workspace、构建 prompt、拉起 agent 进程、初始化 session、流式执行 turn、结束、成功、失败、超时、卡死、被 reconciliation 取消。它甚至规定了每次 poll tick 到来时,先 reconciliation,再校验配置,再拉候选 issue,再按优先级分发,最后通知 observability 消费者。
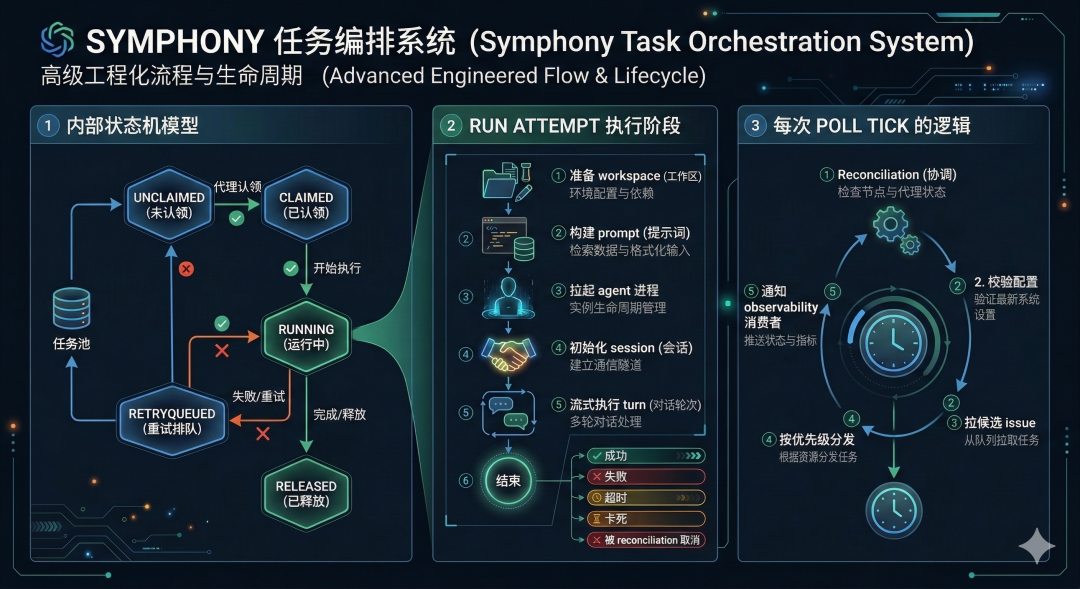
这套设计背后的思想可以概括成一句话:
不要先问“怎么让 Agent 跑起来”,而要先问“怎么避免它跑重、跑错、跑飞”。
比如 candidate selection 里就有一条很像真实研发现场的规则:如果 issue 还处于 Todo,而它依赖的 blocker 还没进入终态,那就不要派发。排序也不是瞎来,而是按 priority、创建时间、issue 标识顺序稳定分发。失败之后也不是简单重试,而是区分正常退出后的短延迟 continuation retry 和异常退出后的指数退避重试。这样的设计,明显已经不是“写代码助手”的思路,而是“任务执行系统”的思路。
三、每个 issue 一个 workspace:这是 Symphony 最值钱的工程细节
如果你只让我挑 Symphony 里最关键的一点,我会选这个:per-issue workspace。
SPEC 写得非常清楚:
每个 issue 的 workspace 路径都必须位于配置的 workspace root 之下;coding agent 只能在该 issue 的 workspace 里执行;workspace 目录名必须净化;还支持 after_create、before_run、after_run、before_remove 等 hooks。工作区会跨运行复用,但终态 issue 可以在启动或状态变更时清理。
**为什么这个设计这么重要?**因为一旦没有隔离,Agent 系统很快就会碰到三个问题:上下文污染、任务互相踩踏、失败后难以恢复。Symphony 的思路很像给每个工单都分配一个独立工位,Agent 只能在自己的工位里思考、改代码、跑测试、记录状态。哪怕它中途失败了,下次重试回来,也可以在同一个 workspace 上继续,而不是重新失忆。
这也是为什么我说 Symphony 更接近“工程执行系统”而不是“聊天式 Agent”。聊天系统强调对话连续;Symphony 强调的是 任务连续性。这两个东西,根本不是一个层级。
四、WORKFLOW.md 才是灵魂:把 Prompt 升级成 repo 内契约
Symphony 很聪明的一点,是它没有把流程硬编码进平台,而是把策略收回到仓库里。SPEC 规定 WORKFLOW.md 由 YAML front matter 和 Markdown prompt body 组成,运行时会解析出 config 与 prompt template;很多核心行为——轮询间隔、workspace root、并发限制、hooks、agent 参数——都来自这份 repo-owned contract。
参考实现里的 WORKFLOW.md 更是把这种思想写得非常彻底。它规定了 issue 在不同状态下该怎么流转:
●Todo 要立即切到 In Progress,然后找或建唯一的 ## Codex Workpad 评论,再开始分析与实现;
●Human Review 阶段不再改代码,只轮询 review 结果;
●进入 Merging 后必须走专门的 land 技能,不能直接 gh pr merge。文档还要求把单个 workpad comment 当作进度和交接的唯一真相源,并且把 out-of-scope 改进拆成新的 Backlog issue,而不是在当前任务里偷偷扩 scope。
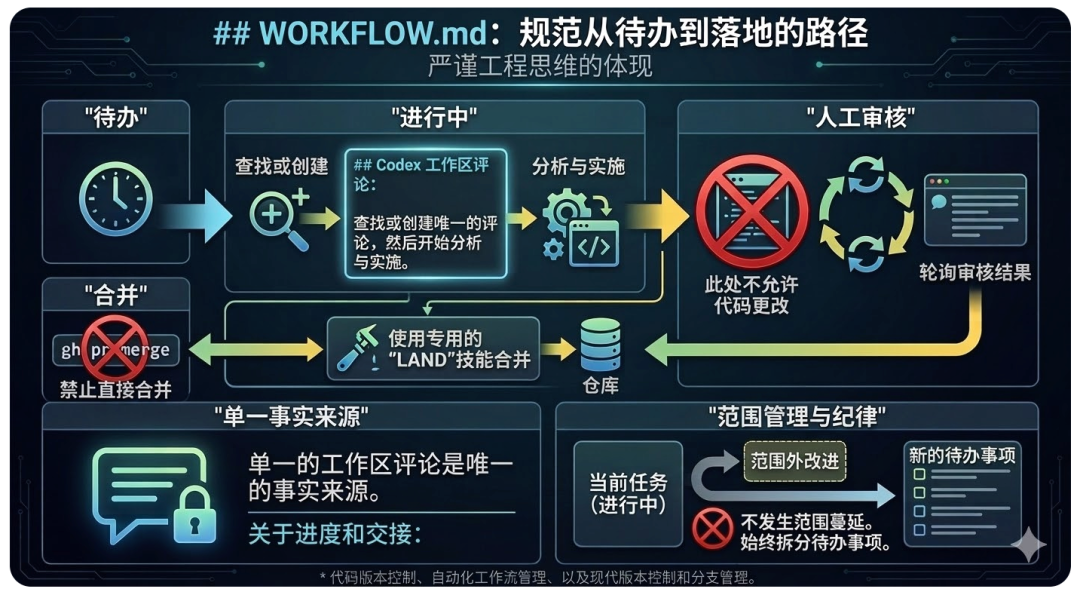
这件事的意义非常大。它意味着团队以后真正需要打磨的,不只是“怎么写 prompt”,而是“怎么把流程、约束、验收标准、状态流转、回退机制,写成一份和代码一起版本化的工程契约”。这比 prompt engineering 更接近组织能力。
五、为什么参考实现偏偏选了 Elixir?
这不是噱头,反而是我觉得 Symphony 最有工程味的地方之一。
GitHub 仓库当前语言分布里,Elixir 约占 94.9%;README 也直接写了 Why Elixir?:因为 Elixir 运行在 Erlang/BEAM/OTP 之上,很适合监督长时间运行的进程,并且支持在不停止活跃 subagents 的情况下做 hot code reloading。
这和 Symphony 的问题形态是高度匹配的。一个普通 Web 请求可能几十毫秒就结束,但一个 coding agent 处理复杂任务时,可能会持续很久,还要接收事件、处理重试、维持会话、更新状态、暴露观测数据。BEAM/OTP 擅长的,恰好就是这种长生命周期、并发多、失败要可控隔离的系统。OpenAI 官方没有在 README 里展开讲 supervision tree 这些词,但它给出的理由已经足够说明方向:Symphony 不是在追求“AI 生态默认语言”,而是在追求“最适合承载 agent orchestration 的运行时”。
六、真正的前提不是更强模型,而是 Harness Engineering
如果说 Symphony 讲的是“如何调度 Agent”,那 Harness Engineering 讲的就是“怎样让 Agent 值得被调度”。
OpenAI 在官方文章里把这件事说得很重:他们构建的产品里,应用逻辑、测试、CI、文档、可观测性和内部工具,全部由 Codex 写出;而人类工程师的角色,从直接写代码,转向设计环境、明确意图、构建反馈回路。文章里那句“Humans steer. Agents execute.”,几乎可以看作整个 Symphony 时代的软件工程宣言。
也正因如此,README 才会明确写:Symphony 最适合已经采用 harness engineering 的代码库。意思很简单:如果你的仓库没有可靠测试、没有清晰边界、没有稳定构建入口、没有可验证的反馈回路,那么再强的 Agent 也只是更快地在混乱里打转。Symphony 的价值,不是替代工程纪律;恰恰相反,它会把工程纪律的重要性放大十倍。
七、它的边界也必须讲清楚
一个成熟的技术判断,不能只讲想象力,不讲边界。
Symphony 现在仍是一个工程预览版,README 明确写了适用于 trusted environments;SPEC 也写了 approval policy、sandbox policy、operator confirmation posture 都是 implementation-defined,不同实现可以高信任,也可以更严格。它当前规范版本只定义了 Linear 作为 tracker,至于更多 issue tracker 适配器,还是 TODO。参考实现虽然带可选 Phoenix observability 服务和 JSON API,但整个项目还远没到“所有团队直接开箱上生产”的阶段。
所以,最稳妥的结论不是“研发彻底无人化已经到来”,而是:
OpenAI 正在把 AI Coding 从“单点能力演示”推进到“工程系统形态演示”。
这一步,比单纯再出一个更强的代码模型,更值得关注。
结语
如果一定要用一句话概括 Symphony,我会这样说:
它不是在教 Agent 如何写代码,而是在教团队如何把“软件交付”本身改写成一套可执行、可编排、可观测的系统。
过去,AI 是工程师的副驾驶;现在,Symphony 展示的是另一种可能:工程师不再盯着每一行代码,而是站到更高一层,去设计流程、约束环境、设定验收标准,然后管理一批持续运行的 agent 去推进工作。真正的变化,不是“AI 会不会写 CRUD”,而是“软件组织会不会因此改写自己的工作方式”。
这,才是 Symphony 最值得认真读的地方。