
如果你最近在 GitHub 上关注过 AI Agent 领域,大概率已经看到过 OpenClaw。到 2026 年 3 月 10 日,它的 GitHub 仓库已经来到约 297k stars,超过了 React 的约 244k 和 Linux 的约 222k。更重要的不是数字本身,而是它火起来的方式:它不是靠一个漂亮网页,也不是靠一个“会聊天的套壳”,而是靠一整套把大模型接入真实消息渠道、真实设备、真实浏览器、真实文件系统的系统架构,硬生生把“AI 助手”做成了一个长期在线的工程系统。
但如果你只把 OpenClaw 理解成“接了很多 IM 的机器人”,你会完全错过它最有价值的部分。OpenClaw 官方 README 写得很直白:“The Gateway is just the control plane — the product is the assistant.” 这句话几乎就是读懂整个项目的钥匙。它的重点从来不是“有多少入口”,而是:有没有一个统一控制面,把消息、状态、路由、模型、工具、节点、权限和安全边界收在一起。 README、架构文档和 Vision 文档都在强调同一件事:OpenClaw 想做的是“真正会做事的 AI”,运行在你的设备、你的渠道、你的规则之内。
这篇文章,我想尽量回答七个问题:
1.它到底是什么?
2.它为什么会采用现在这套架构?
3.Gateway 到底在系统里扮演什么角色?
4.Agent 是怎么运行起来的?
5.Memory、Workspace、Session 为什么是它的关键设计?
6.多 Agent、节点、工具体系是怎么拼到一起的?
7.以及最后,为什么它值得被看作下一代 AI 助手的典型系统样本。
在回答这些问题之前,我不得不说,现在龙虾有些过热了,对于想 “卖铲子” 的公司当然觉得这是好事,于是他们推波助澜,但对于专业人士不能人云亦云。openClaw 有它优秀的一面,也有被炒作夸大的一面,应该客观地看。
一、OpenClaw 的本质,不是聊天机器人,而是“个人 AI 助手控制面”
一句话定义 OpenClaw,我会这样说:
OpenClaw = 一个以 Gateway 为中心的个人 AI 助手控制平面,下面挂着嵌入式 agent runtime、会话系统、工具系统、消息渠道、节点设备和安全边界。
这个定义不是我自己拔高出来的,而是官方文档本身就在往这个方向写。
●README 说它是“你运行在自己设备上的 personal AI assistant”;
●架构文档说它是一个 single long-lived Gateway,拥有所有 messaging surfaces;
●Vision 文档则把它描述为“the AI that actually does things”,运行在你的设备、你的渠道、你的规则里。
把这些信息放在一起看,你会发现 OpenClaw 的设计起点根本不是一个“聊天 UI”,而是一个长期在线、可被多入口触发、可调用工具、可连接设备、可持续维护状态的 AI 系统。
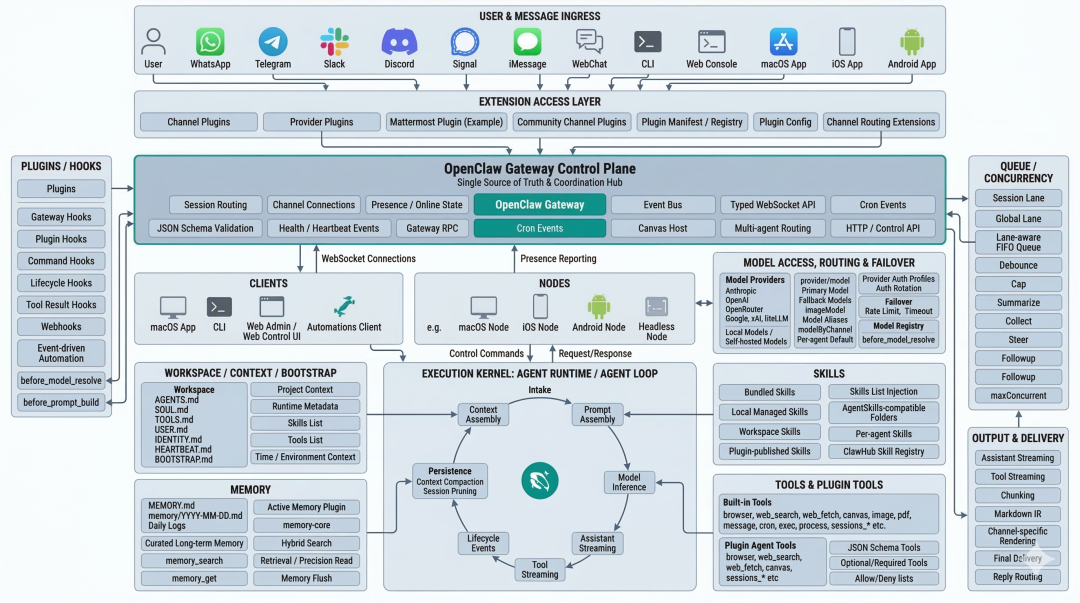
这也是为什么我认为 OpenClaw 更接近“控制面”而不是“应用层”。在很多 AI 产品里,用户打开网页,输入问题,后端调一下模型,返回一段文本,交互就结束了。OpenClaw 则完全不是这种形态。它默认有一个长期运行的 Gateway 进程,消息渠道接到这个 Gateway,上层的 CLI、Control UI、WebChat 接这个 Gateway,macOS/iOS/Android/headless 节点也接这个 Gateway,甚至定时任务、exec approvals、pairing 和 health 事件都围绕 Gateway 展开。也就是说,Gateway 不是一个消息转发器,而是系统中枢。
二、Gateway 为什么是 OpenClaw 最关键的设计
OpenClaw 官方架构文档里最重要的一句话,是它把 Gateway 明确成 single control plane。一个长期运行的 Gateway 拥有所有 messaging surfaces;control-plane clients 通过 WebSocket 连进来;nodes 也通过 WebSocket 连进来,但会声明自己是 role: node;Canvas host 也由 Gateway 的 HTTP server 提供,而且默认和 Gateway 共用 127.0.0.1:18789 这个端口。
这意味着什么?意味着 OpenClaw 的系统设计不是“每个端各做一套逻辑”,而是“先做一个统一控制面,再让所有端接入它”。这在工程上有三个非常大的好处。
第一,状态是统一的。
会话在哪里维护?在 Gateway。
路由在哪里决策?在 Gateway。
设备配对、认证 token、事件广播、健康状态、cron、工具审批在哪里收敛?还是在 Gateway。
这让系统不会因为前端入口变多而出现多套状态、多个事实来源。
第二,协议是统一的。
Gateway protocol 文档明确写了:OpenClaw 不是“随便传一段 JSON”,而是有明确握手流程和版本约束的 WebSocket 协议。服务端先发 connect.challenge,客户端再带着 device identity、role、scopes、caps、auth、签名等参数发起 connect,通过后才返回 hello-ok。协议版本有 minProtocol/maxProtocol 协商,协议 schema 由 TypeBox 定义,再生成 JSON Schema 以及 Swift model。对一个跨 CLI、网页、桌面、移动端、节点设备的系统来说,这种 typed protocol 的价值非常高。
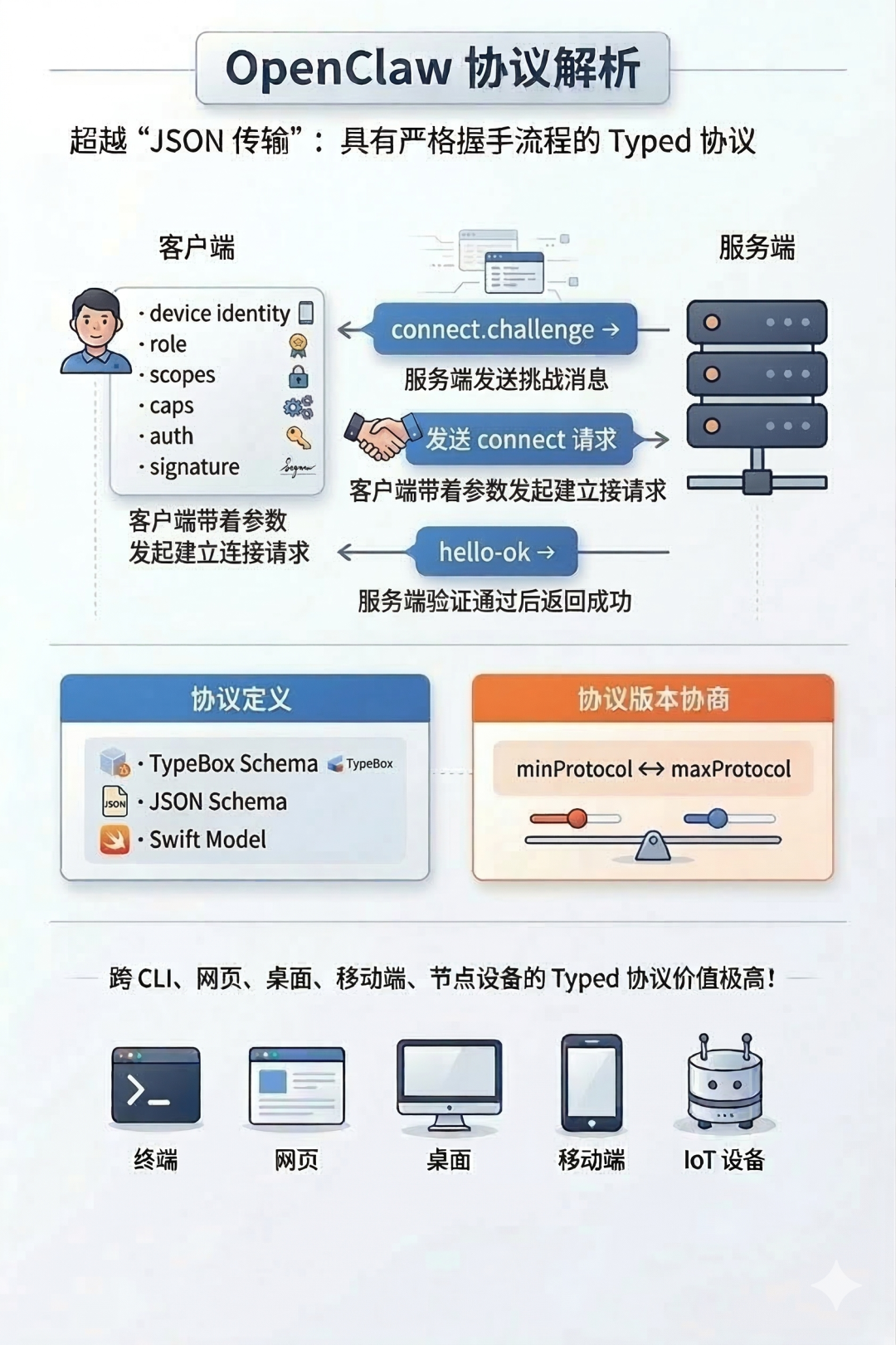
第三,能力是统一暴露的。
比如 Control UI 不是一个独立后端,而是 Gateway 在同一端口上提供的浏览器管理界面;WebChat 直接连 Gateway WebSocket;nodes 也不是第二套服务,而是带 role:node 的外围设备。也就是说,OpenClaw 并不是“一个 App + 一堆外挂”,而是“一个控制面 + 多个表面”。
很多人第一次看 OpenClaw,会把注意力放在“它居然支持这么多渠道”。但真正懂架构的人,会先看 Gateway。因为能不能把多个入口、多种设备、多条事件流、多种工具执行方式,全都压到一个长期运行的控制面里,决定了它到底是“一个功能”还是“一个系统”。OpenClaw 的做法很明确:先有控制面,再有助手。
三、它最强的抽象,不是对话框,而是 Agent、Session 和 Route
很多 AI 产品最基础的抽象单位是“聊天窗口”。OpenClaw 不是。
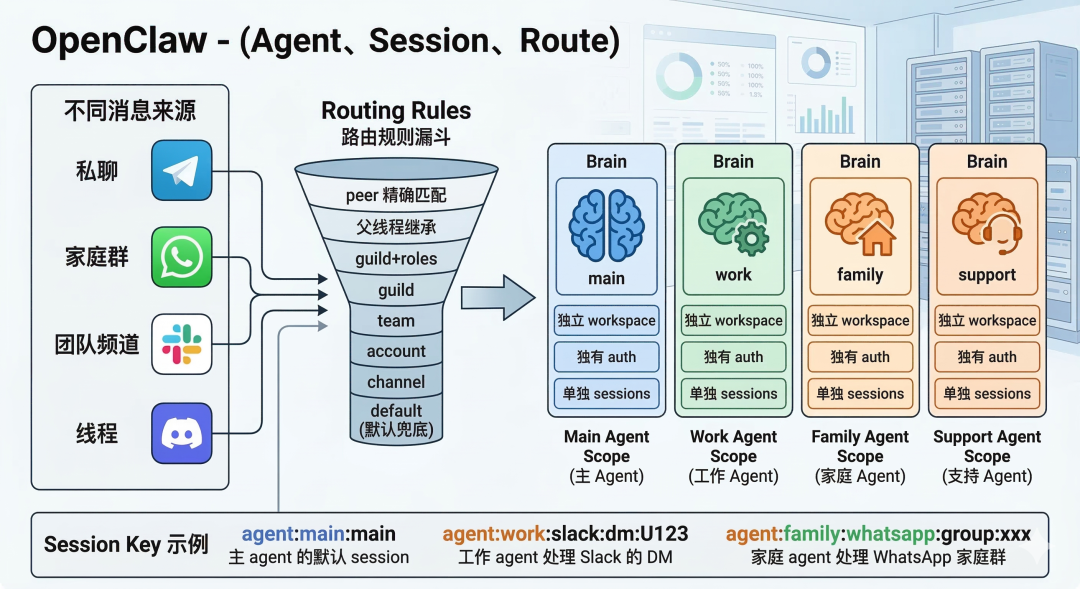
OpenClaw 的真正基础模型,是:
●谁来回复(Agent)
●回复落在哪段连续上下文里(Session)
●一条消息应该被路由到哪个 agent 和哪个 session(Route)
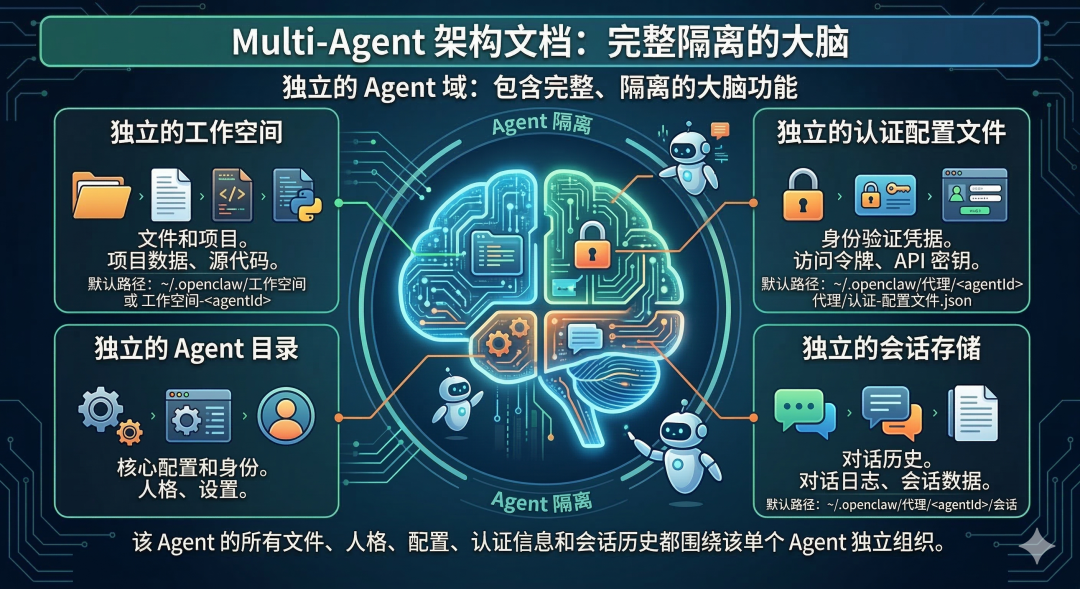
Agent:一颗完整隔离的大脑
Multi-Agent 文档里写得很清楚:一个 agent 是一个 fully scoped brain,拥有
●自己的 workspace
●自己的 agentDir
●自己的 auth profiles
●自己的 session store
它的文件、人格、配置、认证信息和会话历史都是围绕这个 agent 单独组织的。默认路径也很清晰:
●workspace 在 ~/.openclaw/workspace 或 workspace-<agentId>
●session 存在 ~/.openclaw/agents/<agentId>/sessions
●auth profile 在 ~/.openclaw/agents/<agentId>/agent/auth-profiles.json
这件事非常重要。因为这说明 OpenClaw 的多 Agent,不是“在一个上下文里换不同 system prompt 假装多人格”,而是真的把状态、身份、凭证和工作目录做成了隔离单元。但要注意,这种独立是为了让系统跑得更有条理,属于“防君子不防小人”的内部隔离。官方的意思很明确:同一个网关(Gateway)里的 Agent 默认都是“自己人”,不能把互不信任、甚至带有敌意的任务强行塞进同一个网关里,它并没有提供那种级别的安全防御。
Session:上下文连续性的主键
Session 文档里有一句特别关键的话:
OpenClaw treats one direct-chat session per agent as primary.
这句话可以理解成:对每一个 agent,OpenClaw 都认为它有一个“主私聊会话”
OpenClaw 默认会将一个 Agent 接收到的所有私聊(Direct Message, DM)都汇聚到一个主会话里(即 agent:<agentId>:<mainKey>)。对于群聊、频道或特定的话题(Thread),则会自动拆分独立处理。
对于 direct chat, agent 有一个规范意义上的主会话;默认所有 DM 都往这里归并,以保证连续性。
假设你有一个 agent 叫 main。默认情况下:
●你在 Web UI 私聊它一次
●之后又在 CLI 私聊它
●再后来在手机端私聊它
如果这些都被识别为 direct chat,而且你没有改 session.dmScope,那么这些私聊会折叠进同一个主 session,这样做的好处是:agent 会把这些私聊视为同一条连续对话,而不是三个彼此割裂的会话。
默认的主会话机制在单用户场景下很完美,但在多用户场景下就是一个巨大的安全漏洞。
如果 Alice 和 Bob 都去私聊同一个 Agent,在默认配置下,他们实际上是在向同一个“上下文沙箱”里写入数据。这就好比两个人共用一个日记本:
●Alice 刚和 Agent 聊完财务密码。
●Bob 接着去问 Agent“我们刚才聊了什么?”
●Agent 就会直接把 Alice 的密码复述给 Bob,造成严重的信息泄露。
为了应对多用户场景,OpenClaw 提供了 session.dmScope 配置,允许你在架构层面把私聊的上下文切分成更安全的细粒度:
●按发信人隔离(per-peer)。
●按频道+发信人隔离。(per-channel-peer)
●按账号+频道+发信人隔离(per-account-channel-peer)。
⚠️ 如果你在开发面向多用户的 AI Agent,绝对不能盲目使用默认的私聊配置。必须根据业务需求,通过调整 dmScope 将用户的对话状态彻底隔离开,防止你的 Agent 变成一个没有隐私边界的“大喇叭”。
Route:决定消息进入哪颗大脑
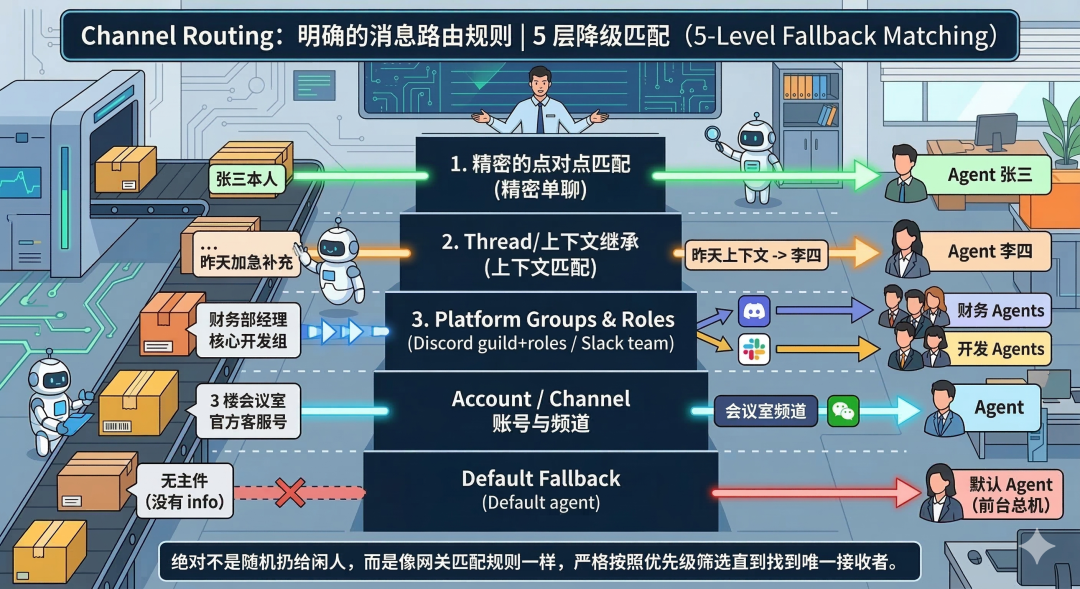
Channel Routing 文档把消息路由规则写得非常明确,一条消息发过来,绝对不是“哪个 Agent 闲着就扔给谁”,而是像网关(Gateway)匹配规则一样,必须严格按照优先级一层层往下筛,直到找到唯一确定的接收者。
我们可以用**“公司收发室分拣快递”**来打个比方,看一下这 5 层降级(Fallback)匹配规则:
1.精准单聊 (Exact peer match):快递单上写着“直接交到张三本人手里”。
○明确的点对点直接交互,优先级最高。
2.跟帖/线程继承 (Parent peer match):快递单没写名字,但备注了“这是昨天那个加急件的补充材料”。收发室一查昨天是李四负责的,直接给李四。
○识别 Thread 或上下文,让同一个 Agent 连贯处理同一个话题。
3.平台级群组与角色 (Discord guild+roles / Slack team):快递写着“给财务部经理”或“给核心开发组”。
○根据外部平台(如 Discord/Slack)的特定权限组或大团队来分配对应的 Agent。
4.账号与频道 (Account / Channel):快递写着“送到 3 楼会议室”或“交给官方客服号”。
○匹配特定的聊天频道或绑定的公共账号。
5.默认兜底 (Default agent):啥也没写清楚的无主件,统统扔给“前台总机”处理。
○如果上面所有条件都未命中,最后由默认的 Agent 统一接管。
这意味着 OpenClaw 的“消息归属”不是模糊的。一条消息不是“谁在线谁回”,而是经过一套确定性规则,先判定该由哪个 agent 接管,再决定落到哪个 session 里。
所以 OpenClaw 能天然处理这些现实世界场景:
●同一个 Gateway 托管多个 agent;
●一个 Telegram 群给 work agent;
●一个 WhatsApp 家庭群给 family agent;
●一个 Slack team 给 support agent;
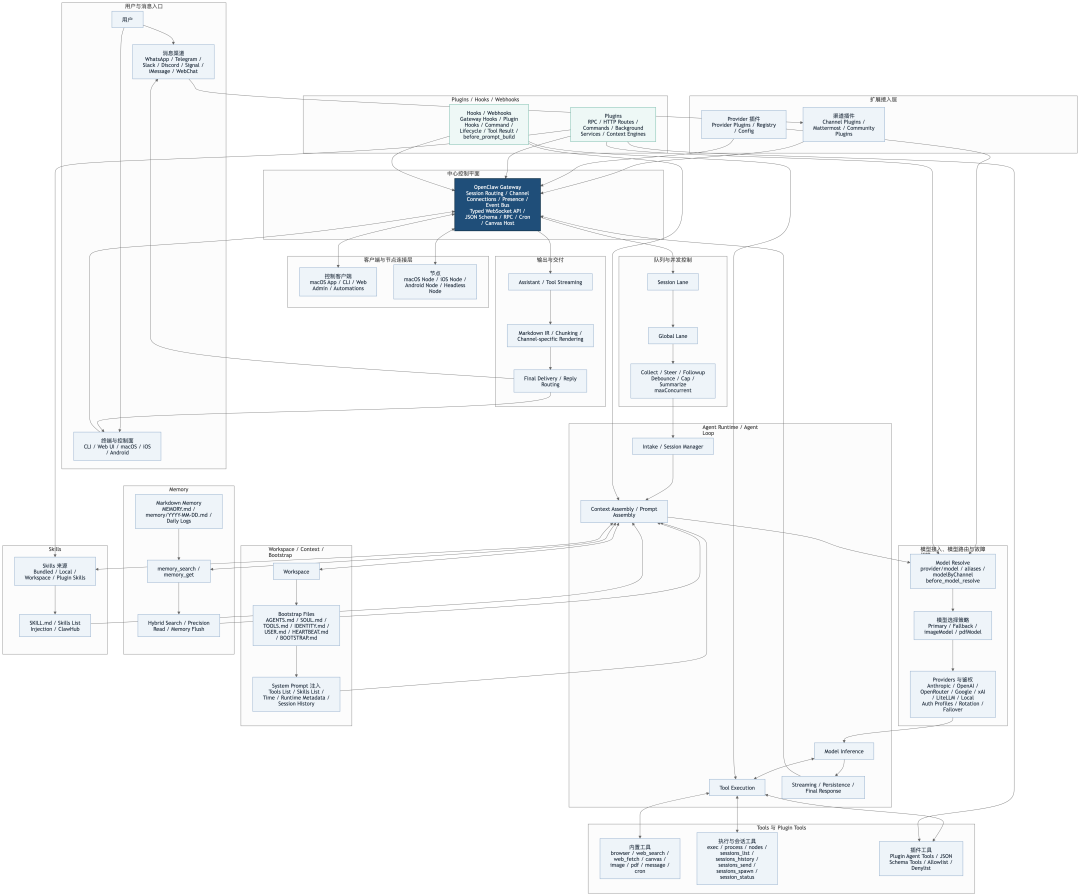
四、Agent 不是外挂调用,而是嵌入式运行时
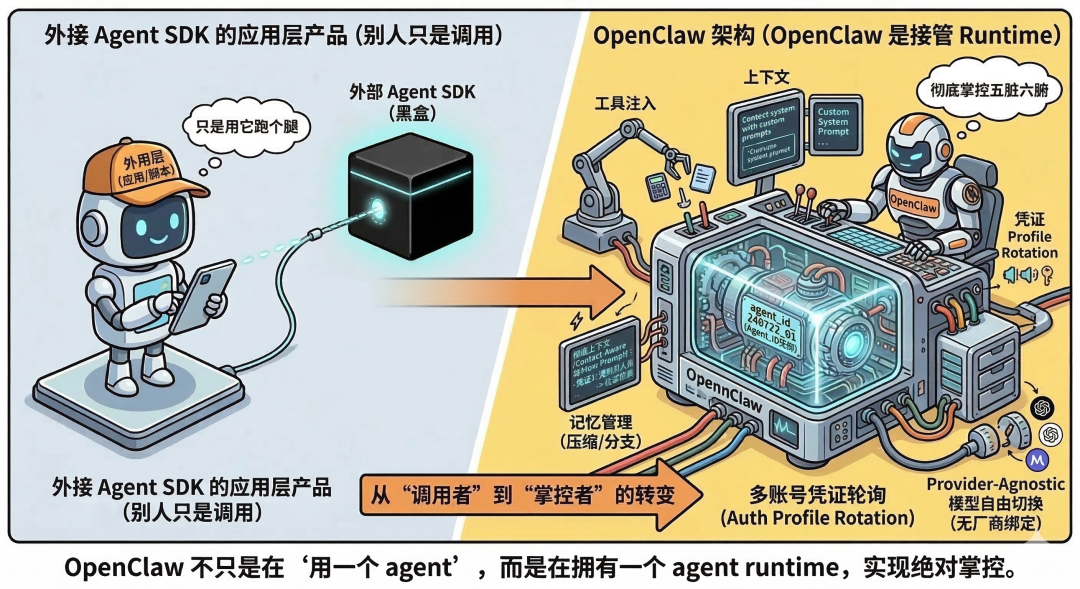
很多人对 OpenClaw 最大的误解,是把它当成了一个简单的“任务调度员”——以为它只是在收到消息时,拉起一个外部的子进程(Subprocess)去跑一下,或者通过接口(RPC)远程调一下就完事了。
但架构文档明确指出:OpenClaw 是将 Agent 运行时“原生内嵌”到自己的网关里的。 它不是把 Agent 当作一个不可控的外部黑盒,而是直接在内部实例化 Agent 的核心会话(AgentSession)。
Pi Integration Architecture 文档写得非常明确:OpenClaw 不是 把 pi 作为 subprocess 或 RPC mode 的外部黑盒去调用,而是直接导入并实例化 pi 的 AgentSession,通过 createAgentSession() 把 agent runtime 嵌入 到自己的消息网关架构里。
这种“深度内嵌”的架构设计,直接赋予了系统 6 大核心优势:
1.全局生命周期掌控: 从对话的创建、挂起、恢复到销毁,网关层拥有绝对的控制权。
2.动态能力扩展: 可以在运行时,随时把自定义的外部工具“塞”给 Agent 使用。
3.“看人下菜碟”的人设: 能够根据消息来源(不同的平台渠道或上下文),动态切换 Agent 的系统提示词。
4.强悍的记忆管理: 不仅能持久化保存对话,还支持高级的“记忆压缩(Compaction)”防止上下文爆满,甚至支持像 Git 一样对对话“开分支(Branching)”。
5.智能凭证轮询: 在多个账号或 API Key 之间自动无缝切换,轻松应对并发和限流问题。
6.模型厂商解绑: 底层的大模型想换就换,完全不受单一服务商(如 OpenAI、Anthropic)的绑架。
简单来说,OpenClaw 走的是“直接收编”的路线,它把 Agent 的核心大脑直接“拔”过来,原生种植在了自己的神经中枢里。这就好比你不再是打电话咨询外部专家,而是直接把这位专家招进了自家的核心指挥部。正因为“人”彻底成了内部员工,你才能拥有上帝视角般的掌控力:你可以全面接管他的作息安排(会话生命周期),随时往他手里塞各种定制兵器(动态注入工具),根据不同场合要求他扮演不同的角色(按渠道切换提示词),像操作代码仓库一样去整理甚至分叉他的记忆(支持压缩与分支的持久化),甚至连他背后的“脑力供应商”(随时无缝切换各家大模型)和权限账号,都能在底层悄无声息地替他自动轮换。说白了,OpenClaw 不是在和 Agent “跨部门合作”,而是直接把 Agent 融为了自己身体的一部分。换句话说,OpenClaw 不是“在用一个 agent”,而是“在拥有一个 agent runtime,并把它纳入自己的控制面”。这也是它跟很多“外接 Agent SDK 的应用层产品”最大的差别之一。别人只是调用,OpenClaw 是接管。
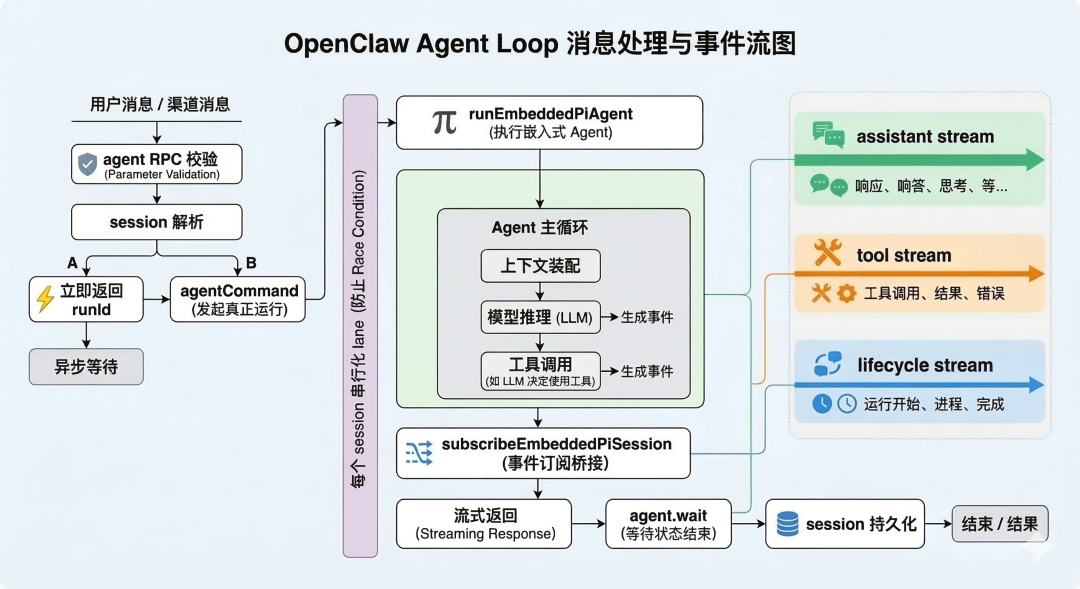
五、Agent Loop:一条消息的"真实旅程"
前面我们讲了 Gateway 如何把消息路由到正确的 Agent。现在让我们跟随一条消息,看看它进入 OpenClaw 后,到底经历了什么。
不是"一次请求",而是一个完整生命周期
如果你习惯了网页聊天框的"发消息→等回复"模式,OpenClaw 的处理方式会让你有点意外。
传统模式:
⚡ 代码片段用户发消息 → 后端调用模型 → 返回文本 → 结束
OpenClaw 模式:
⚡ 代码片段用户发消息 → 分配 runId → 解析 session → 装配上下文 → 运行 agent → 流式返回事件 → 持久化 session → 结束
这一条链路,实际上就是你给 OpenClaw 发一句话之后,系统内部真实发生的事情。它不是“一次 HTTP 请求”,而是一个完整的运行生命周期。
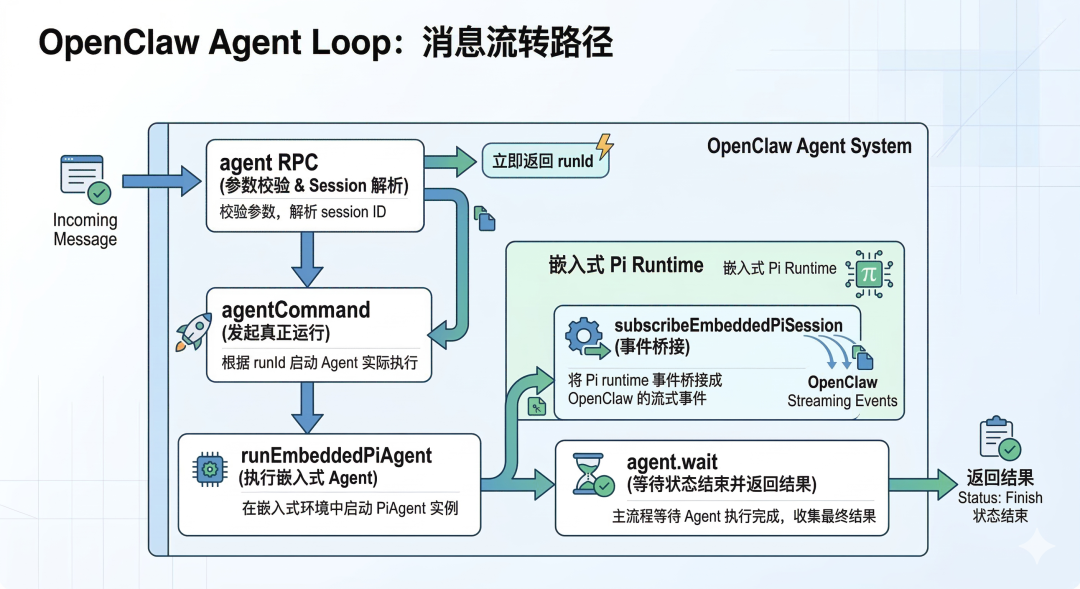
OpenClaw 把你的消息视为一个进程而非请求。它会给这个进程分配ID、监控生命周期、管理并发、持久化状态。
并发控制:为什么同一聊天窗口的消息要"排队"?
想象一下这个场景:你在 Telegram 连续发了三条消息:
●“帮我查一下明天天气”
●“顺便看看日程”
●“把第一封邮件标为已读”
如果这三条消息并发执行,会发生什么?
●Agent 可能先处理了邮件,再处理天气
●Session 历史会乱序写入
●工具调用可能互相冲突
OpenClaw 的解决方案很简单:每个 session 串行化执行。这不是性能问题,而是状态一致性问题。长期在线的助手,必须保证"记忆"不会被乱序操作搞乱。是防止工具竞争和状态污染的工程必要选择。
流式事件:你看到的不是"打字动画",而是真实的工作过程
OpenClaw 的流式输出,不是简单的"逐字显示",而是三种事件流:
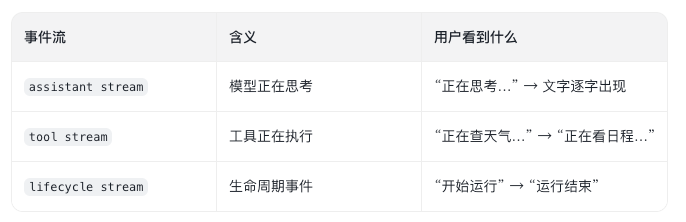
为什么要这样设计? 因为这让用户能真正"看到 AI 在工作"。不是动画,不是假进度条,而是系统内部真实发生的事件被推送到前端。它的体验更像一个"正在办公的助手"而非"死寂的输入框"
六、真正让它“像一个人”的,不是模型,而是 Workspace、System Prompt 和 Memory
很多人体验 OpenClaw 后会有一种明显感觉:它比普通网页聊天更像一个“持续存在的助手”。这种感觉,核心不是来自模型,而是来自它对工作区、提示词和记忆的系统化设计
Workspace:AI 的家,而不是一个临时目录
简单说,Workspace 就是 AI 的"家":
●它有固定的位置(~/.openclaw/workspace/)
●它有固定的文件结构
●它是 AI 长期工作的地方,不是临时落脚点
OpenClaw 在 Workspace 里约定了一整套"说明书文件":
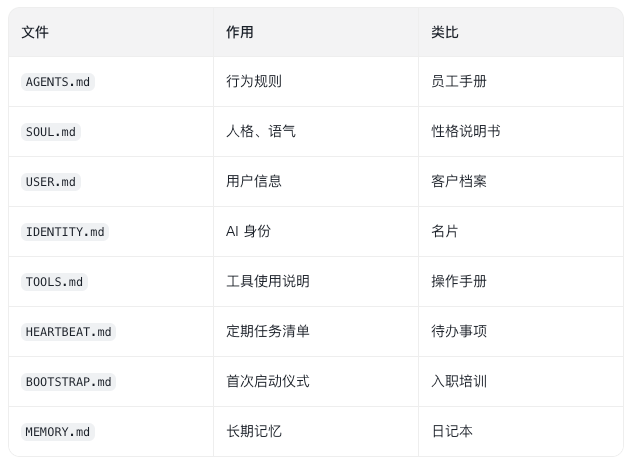
这个设计特别妙。因为它把很多系统会偷偷塞进 prompt 模板或数据库里的东西,变成了用户可见、可读、可改、可备份的文件系统资产。你不是在“配一个人设”,而是在维护一个 AI 的长期工作环境。
这里有一个非常重要的提醒:workspace 是默认工作目录,但不是硬沙箱(hard sandbox);相对路径默认在 workspace 内解析,但绝对路径仍可能访问宿主机其它位置,除非你开启 sandbox。
System Prompt:每次运行都在"编译上下文"
OpenClaw 不是把用户的问题直接扔给模型,而是每次都重新构建一份完整的上下文:
1⚡ 代码片段System Prompt 结构:
2├── Tooling(可用工具列表)
3├── Safety(安全规则)
4├── Skills(技能列表)
5├── Workspace Context(工作区文件)
6├── Documentation(相关文档)
7├── Current Date & Time(当前时间)
8└── Runtime(运行环境信息)
Context 文档还补充了细节:默认会把 AGENTS.md、SOUL.md、TOOLS.md、IDENTITY.md、USER.md、HEARTBEAT.md、BOOTSTRAP.md 等文件作为 Project Context 注入系统提示;技能本身只会注入“技能列表和描述”,真正的 SKILL.md 需要模型按需读取。
类比:
●传统聊天:像"临时起意打电话"
●OpenClaw:像"开会前先发会议议程和背景资料"
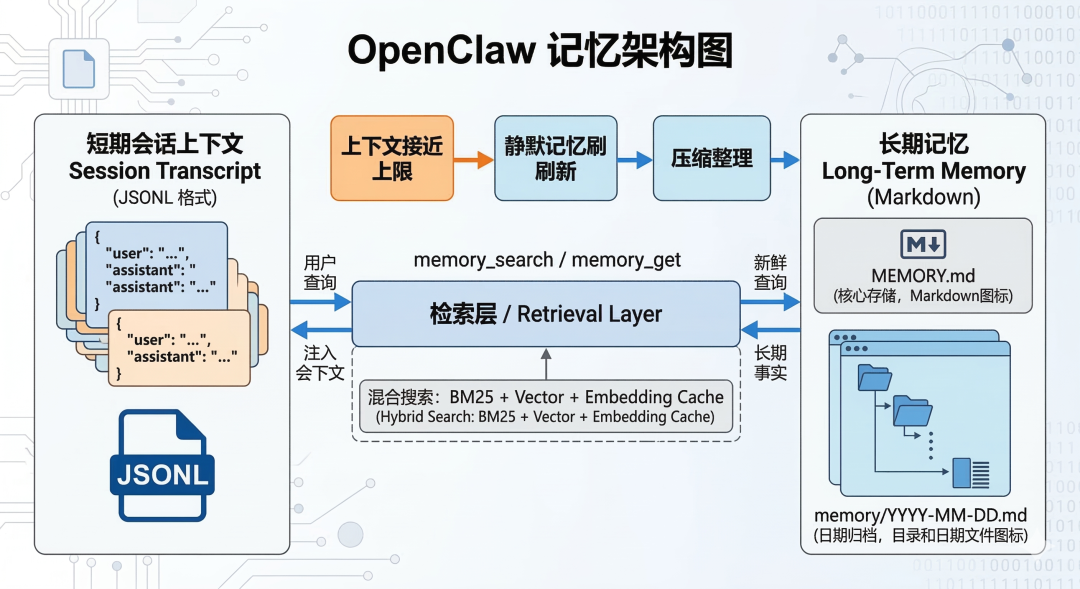
Memory:真正写到磁盘,才算记住
Memory 文档里我最喜欢的一句话是:
The files are the source of truth; the model only “remembers” what gets written to disk.
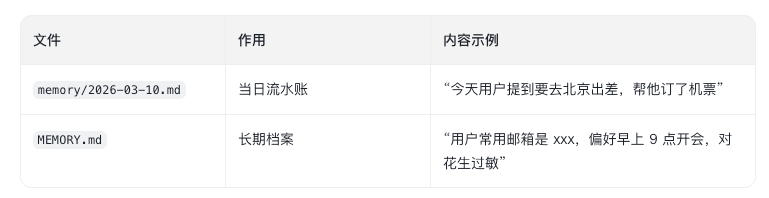
OpenClaw 默认的记忆结构非常简单,但非常工程化:
1⚡ 代码片段workspace/
2 ├── memory/
3 │ ├── 2026-03-10.md ← 今天的日志
4 │ ├── 2026-03-09.md ← 昨天的日志
5 │ └── ...
6 └── MEMORY.md ← 长期、精炼的永久记忆
两种记忆的区别:
检索机制:不是"只有文件",也不是"只有向量"
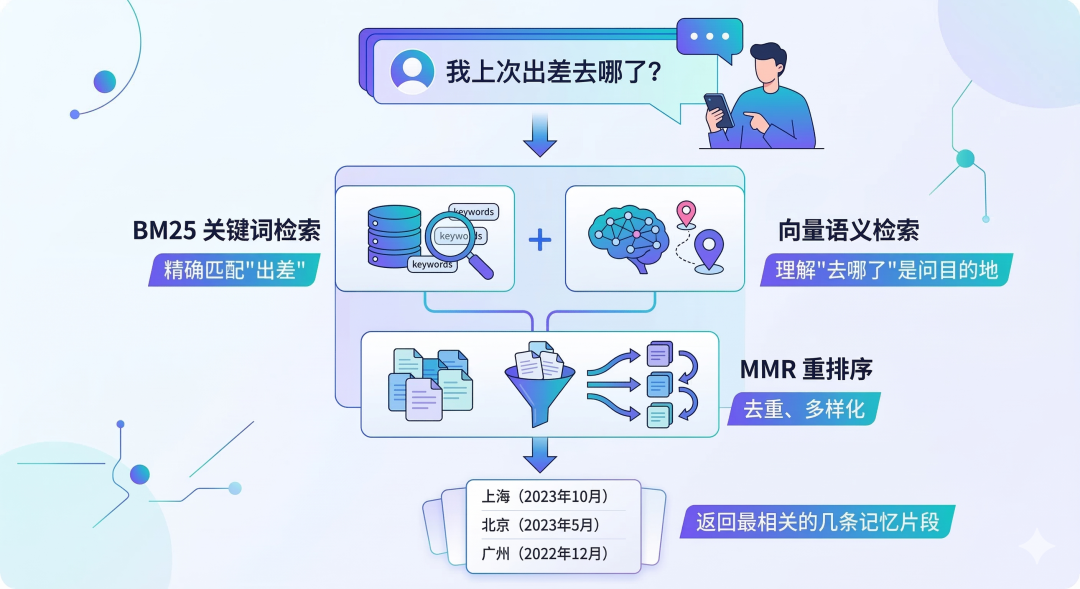
OpenClaw 使用混合检索,它明确暴露了两个 agent-facing tools:
●memory_search 负责检索
●memory_get 负责精确读取某个 Markdown 文件或行段
1⚡ 代码片段用户问"我上次出差去哪了?"
2 ↓
3 BM25 关键词检索 ← 精确匹配"出差"
4 +
5 向量语义检索 ← 理解"去哪了"是问目的地
6 ↓
7 MMR 重排序 ← 去重、多样化
8 ↓
9 返回最相关的几条记忆片段
记忆刷新:在"遗忘"前先"存档"
OpenClaw 有一个很巧妙的设计:pre-compaction memory flush
当 session 接近上下文上限(比如对话太长,快塞不进模型窗口了),OpenClaw 会:
●触发一次"静默回合"(用户看不到)
●提醒模型:“把值得记住的信息写入记忆文件”
●然后再压缩上下文
七、工具体系:分层设计,不是堆砌功能
如果说 Gateway 是控制面,Session 是状态骨架,那么 Tools / Plugins / Skills 就是 OpenClaw 的执行肌肉。
OpenClaw 的工具体系有三个层次,很多人会混淆。让我们分清楚:
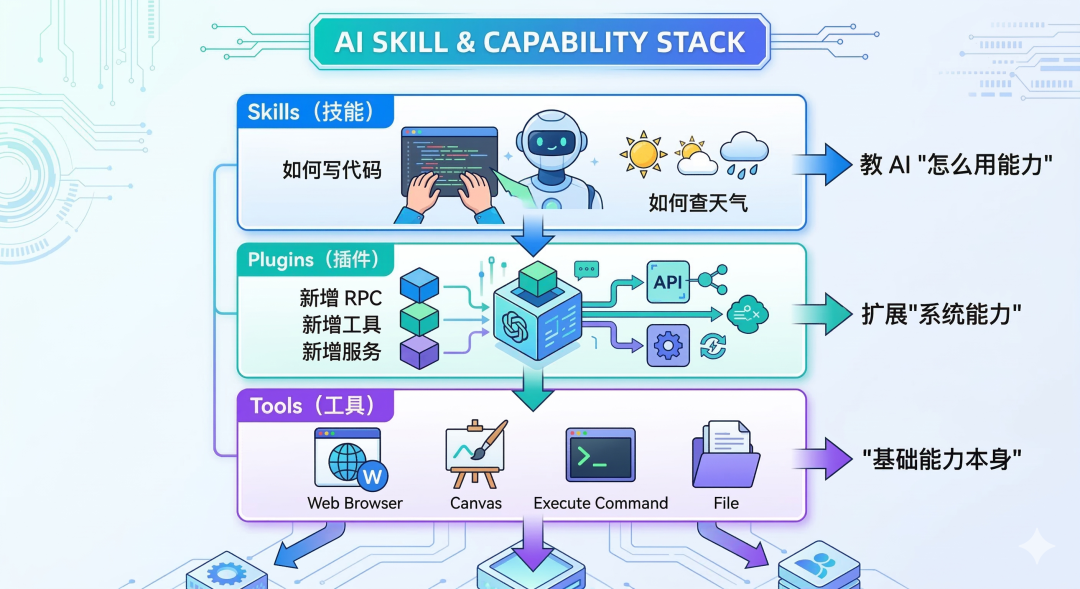
Tools:第一等公民
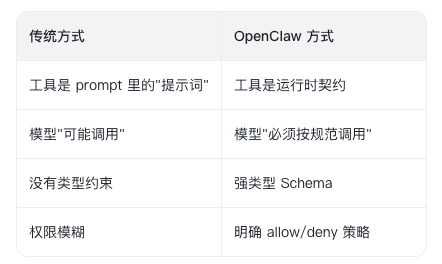
OpenClaw 暴露的是 first-class agent tools,不是外挂脚本。 包括 browser、canvas、nodes、cron、gateway、session 相关工具、agents_list、image、pdf、message、exec 等。
OpenClaw 没有把“能力调用”做成 prompt 技巧,而是做成了运行时契约。Tool list 和 tool schema 会进入模型上下文;tool allow/deny、tool profiles、per-agent 工具策略、provider-specific 工具策略和 sandbox 工具策略共同决定模型实际能拿到哪些工具
Plugins:扩展系统本身
插件是运行在 Gateway 内部的代码模块,可以:
●注册新的 RPC 方法
●添加新的 HTTP 路由
●注册新的工具
●启动后台服务
类比:
●Skills:像"使用说明书"
●Tools:像"内置功能"
●Plugins:像"给系统装新器官"
Skills:教 AI 如何做事
每个 Skill 就是一个目录,核心是 SKILL.md——一份详细的操作指南。Skill 的三个来源(优先级从高到低):
●<workspace>/skills/:当前工作区专属
●~/.openclaw/skills/:用户私有技能
●Bundled skills:系统内置技能
与Plugins的本质区别:Plugins是给手机增加新硬件(如外接摄像头);Skills是相机APP里的"夜景模式"说明书。
八、Node:让 AI “有手有眼”
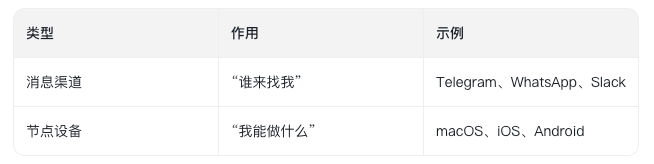
OpenClaw 严格区分了两个概念:
为什么这样设计?
如果把它们混在一起:
●Telegram Bot 只能干 Telegram 允许的事
●WhatsApp Bot 只能干 WhatsApp 允许的事
每个渠道都要重新实现一遍"控制电脑"的能力
OpenClaw 的设计:
●所有消息渠道都汇聚到 Gateway
●所有设备能力也汇聚到 Gateway
Gateway 负责调度:“这个 Telegram 消息需要控制 iPhone,我来协调”
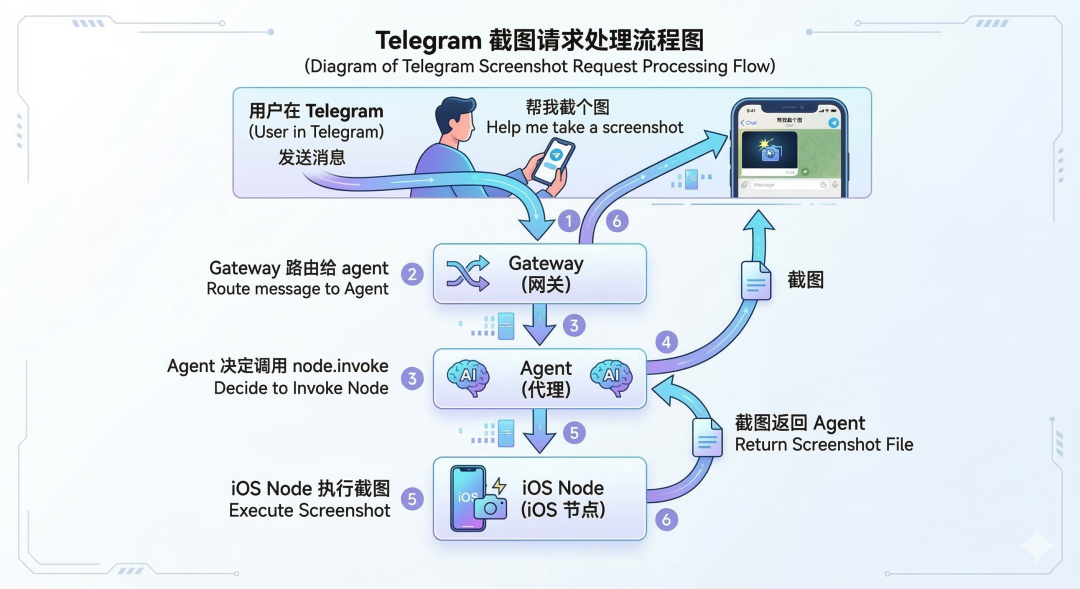
Node 是什么?
node 是 companion device,可以是 macOS、iOS、Android 或 headless 设备;它通过和 operator 一样的 Gateway WebSocket 接入,但使用 role: “node”,向 Gateway 暴露一组命令面,比如 canvas.、camera.、device.、notifications.、system.*,再由 node.invoke 触发。官方还特别强调:nodes are peripherals, not gateways。消息还是落在 Gateway,不是落在 node
Node 是一台"伴侣设备",它:
●通过 WebSocket 连接到 Gateway
●向 Gateway 暴露一组能力(camera、notifications、system…)
●等待 Gateway 的指令
类比:
●Gateway:大脑
●消息渠道:耳朵和嘴
●Node:手和脚
没有 Node 的话:
●Telegram Bot 无法直接控制你的 iPhone
●需要你自己手动截图,再发给 Bot
●AI 无法真正"替你做事"
有了 Node:
●AI 可以跨设备协同工作
●你在 Telegram 发指令,它在你的 Mac 上执行
●真正的"个人助手"体验
九、安全边界:诚实比承诺更重要
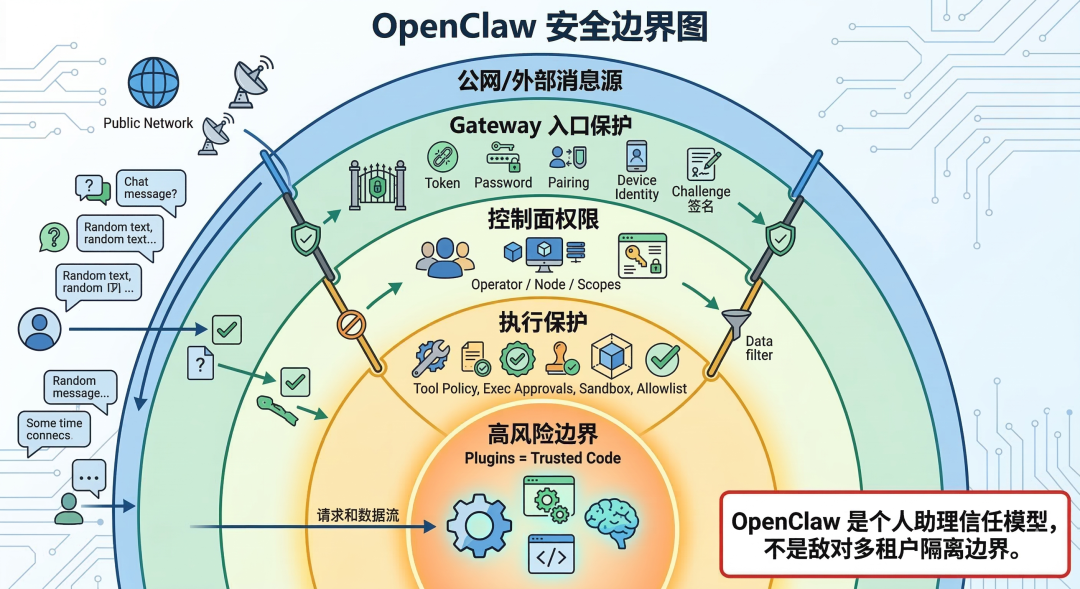
OpenClaw 的安全模型假设的是 one trusted operator boundary per gateway
OpenClaw 的安全文档非常诚实,这句话翻译成人话是:
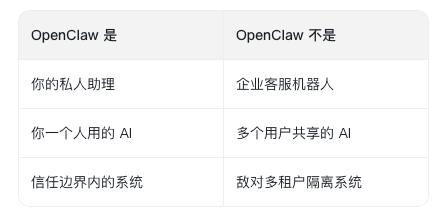
这意味着:如果你把Gateway密码给朋友,让他也连进来,你们的对话历史、文件访问、记忆内容默认不隔离。这不是漏洞,是设计选择——为了简化架构,OpenClaw牺牲了多租户隔离,换取单用户场景下的极致能力。
安全层次
1⚡ 代码片段外层:公网/外部消息源
2 ↓
3第一道门:Gateway 入口保护
4 - token/password 认证
5 - challenge 签名验证
6 - device identity 校验
7 - pairing 审批
8 ↓
9第二道门:权限控制
10 - operator / node 角色
11 - scopes 权限范围
12 ↓
13第三道门:执行保护
14 - tool policy(工具策略)
15 - exec approvals(执行审批)
16 - sandbox(沙箱隔离)
17 - allowlist(白名单)
18 ↓
19内层:高风险边界
20 - plugins = trusted code
21 - 插件和 Gateway 同等权限
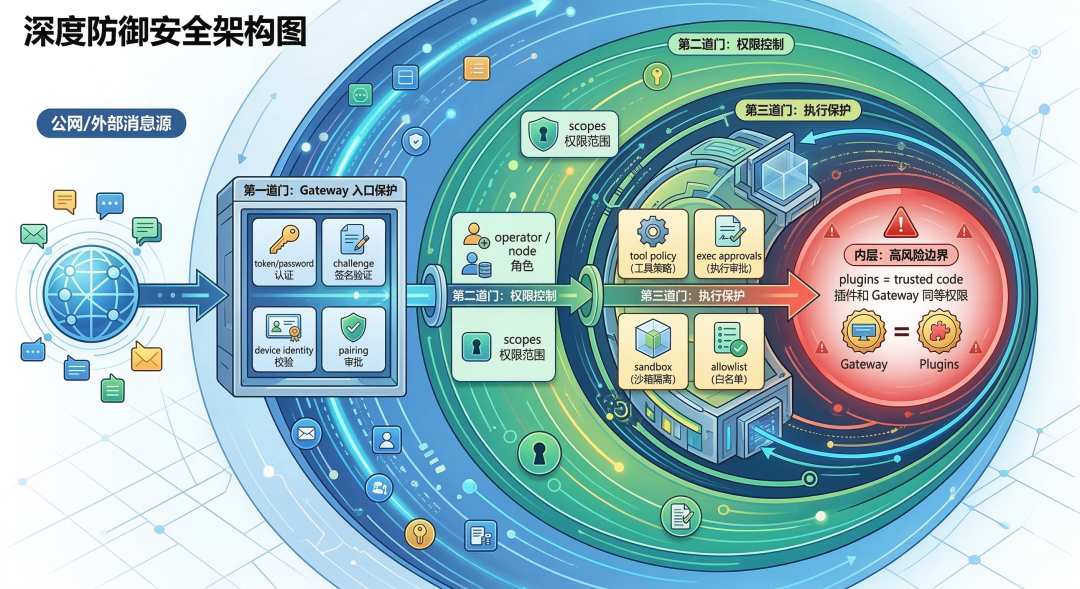
Sandbox:可以隔离,也可以放行
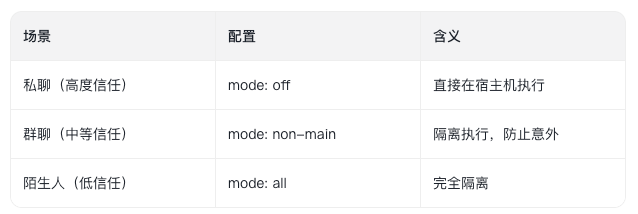
OpenClaw 的沙箱设计非常灵活:
配置维度:
●mode:off / non-main / all(是否启用沙箱)
●scope:session / agent / shared(沙箱范围)
●workspaceAccess:none / ro / rw(工作区访问权限)
实际用法举例:
浏览器隔离:不是接管你的 Chrome
OpenClaw不会接管你的日常Chrome(那里面可能有银行登录态),而是拉起独立的Chrome Profile:
●独立的Cookie、缓存、扩展
●Agent专用,与你的个人浏览数据隔离
●支持截图、点击、PDF生成,但无法访问你个人的浏览器历史
这是"能力"与"安全"的折中:AI需要浏览器自动化,但不能拥有你的全部数字生活。
十、为什么这是"个人AI操作系统"的雏形?
OpenClaw 之所以值得研究,不是因为它 GitHub stars 多,而是因为它回答了一个未来会越来越重要的问题:
如果 AI 不再是网页对话框,而是一个长期在线、能操作设备、能记住一切的助手,它的系统架构应该长什么样?
OpenClaw 的答案是:
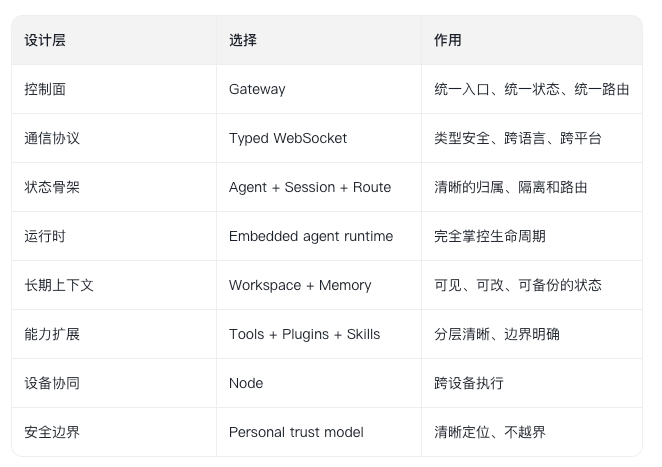
这套答案不一定是终局,也还远没到“完美”。Vision 文档自己都说,项目还很早,当前重点依然是 security、safe defaults、bug fixes、stability 和 setup reliability。也就是说,它依然在快速迭代,仍然带着实验性。
但它已经足够有代表性。因为它第一次比较完整地把“个人 AI 助手”这件事,从概念拉成了系统工程:
●消息不再只是消息,而是事件入口;
●模型不再只是回答器,而是运行时里的推理核心;
●工具不再只是 function calling 演示,而是被策略、审批和沙箱约束的系统调用;
●记忆不再只是“模型好像记得”,而是落到磁盘、可检索、可审计、可 Git 备份的工作区资产
它具备了"操作系统"的味道
不是说它替代 Windows 或 macOS,而是说它有那种系统级的感觉:
1⚡ 代码片段传统应用:打开 → 用 → 关闭
2操作系统:开机 → 长期运行 → 管理所有应用 → 关机
3
4传统 AI:聊天 → 结束
5OpenClaw:启动 Gateway → 长期在线 → 管理所有 Agent → 关闭
最后,再强调一次:OpenClaw 的本质,不是一个接了很多渠道的聊天 Bot,而是一套以 Gateway 为控制面、以 Agent/Session/Memory 为状态骨架、以工具与节点为执行面,把大模型真正接入现实世界的个人 AI 助手系统。