过去几年,多模态检索一直有一种很别扭的感觉:大家都知道它重要,也都知道它有价值,但真要落地,往往就会迅速滑向一场“拼装工程”。文本一套模型,图片一套模型,音频最好先转写,视频最好先抽帧,PDF 还要单独解析。最后系统看起来像是“能搜”,可背后其实是五六条处理链硬拼在一起,复杂、昂贵,而且很难优雅。
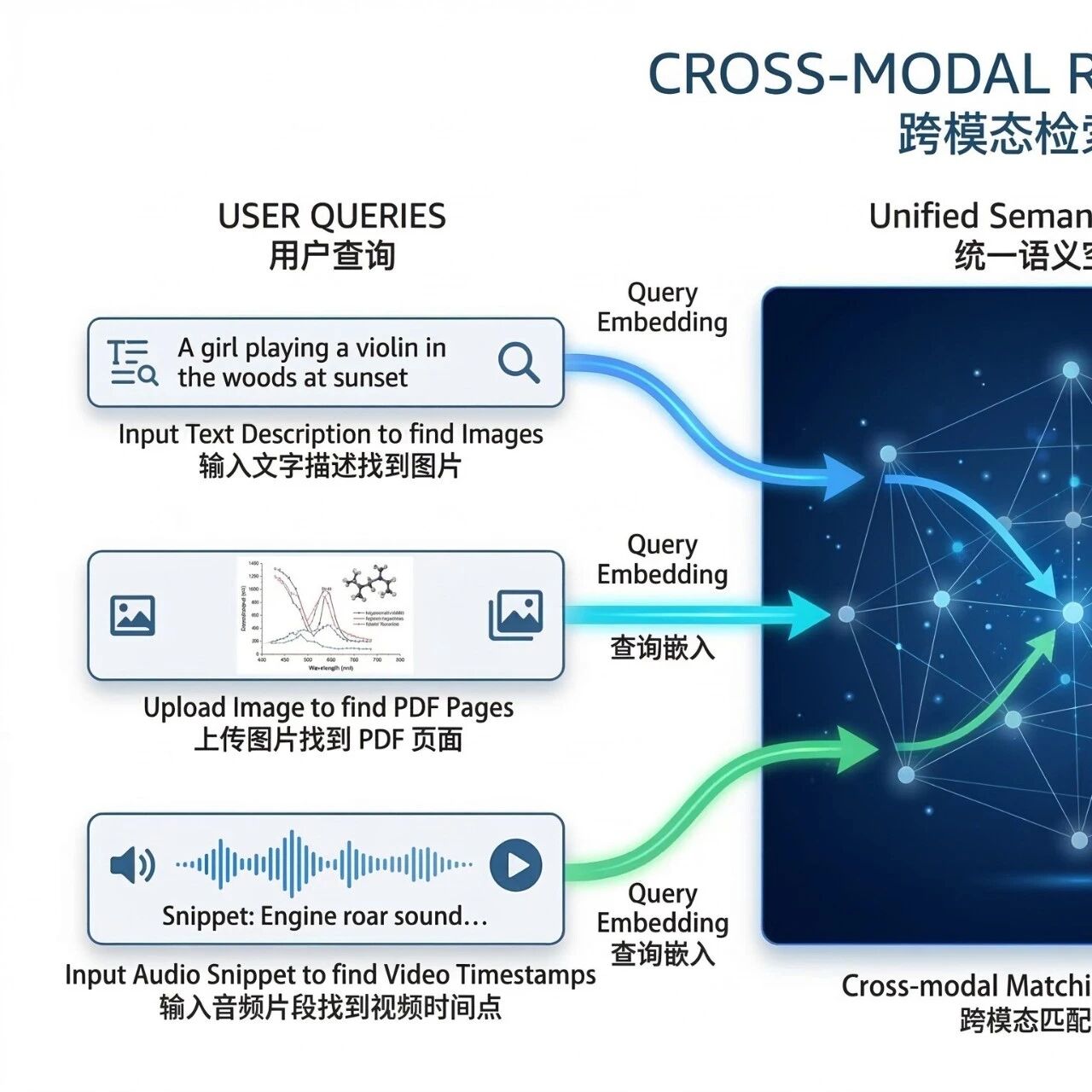
Google 新发布的 Gemini Embedding 2,真正让人眼前一亮的,不是它又把 embedding 做强了一点,而是它第一次把文本、图片、音频、视频、PDF拉进了同一个统一向量空间里。官方把它定义为 Google 首个原生多模态 embedding 模型,目前已经通过 Gemini API 和 Vertex AI 进入 Public Preview。
这件事听上去像模型更新,实际上更像一次架构层的洗牌。因为从这一刻起,多模态检索终于不再只是“大厂能做、小团队很难做优雅”的高级能力,而开始像一项真正的基础设施:可以被调用,可以被组合,也可以被更低成本地接进你的搜索、RAG、知识库和内容系统里。
它到底强在哪,不只是“支持多模态”
很多人看到这里,第一反应可能是:
“支持文本、图片、音频、视频、PDF,这不就是多模态吗?”
还真不止。
Gemini Embedding 2 的关键不只是“什么都能输进去”,而是所有模态出来以后能落在同一个 embedding space 里。这意味着什么?意味着你不再一定要为每种媒介维护完全独立的语义体系。文本可以搜图片,图片可以召回 PDF,音频可以关联视频片段,跨模态检索终于不是一层额外的“补丁能力”,而成了模型本身的默认能力。
这会直接改变系统设计思路。
以前你更像是在设计“五条平行管线”。
现在你更像是在设计“一个统一召回底座”。
注意,我这里说的是“更像”,不是说所有复杂度从此消失。长视频仍然要切片,复杂知识库仍然要做 metadata 设计,高要求场景依然常常需要 rerank。
最值钱的地方,是它终于不再要求你先做“翻译官”
过去处理非文本内容时,行业里一个非常常见的默认动作是“先降级成文本”。
●音频?先 Whisper。
●视频?先抽帧,最好再加字幕。
●PDF?先 OCR,再抽正文。
这类方案当然能工作,但本质上是在让系统把所有模态都挤进“文本入口”里。Gemini Embedding 2 做的,是把入口重新打开。它可以原生摄取音频,不需要中间文本转写;视频支持约 2 分钟级别的原生输入;PDF 也可以直接嵌入。
这意味着搜索开始更接近人真正理解世界的方式。
●你问“哪节课讲过这个图”,系统不一定非要先把整门课转成文本再去关键词匹配;
●你上传一段声音,也不一定非得先变成文字才能参与检索;
●你搜一个商品,也不一定要把图和文分开索引,最后再人工拼装成“结果页”。
一个特别容易被低估的能力:它可以表示“实体”,不只是“素材”
Gemini Embedding 2 还有一个很值得说的亮点:它支持混合输入。
如果你在一个 content entry 里传入多个 parts,比如“文字 + 图片”,模型会为这组内容生成一个聚合后的 embedding;如果你在 contents 数组里放多个独立条目,它则会返回多个独立向量。官方文档甚至直接建议:对于像社交媒体帖子这种包含多种媒体内容的复杂对象,可以把多个 embedding 聚合,形成一个 post-level representation
这件事非常关键。
因为它把 embedding 的对象,从“原子素材”升级成了“业务实体”。
一块手表,不只是商品图,也不只是商品描述;
一条社交帖子,不只是文字,也不只是配图;
一堂课程,不只是讲义 PDF,也不只是视频和录音。
过去这些东西往往是拆开建索引、拆开召回、最后在上层硬拼。
现在你可以在索引层就把它们当成一个“对象”来表示。
这对于做内容平台、商品搜索、企业知识库、课程检索,影响都非常大。因为从这里开始,RAG 的检索单元不再只能是 text chunk,它可以是一个帖子、一个商品、一段课堂内容,甚至一个带图文说明的复杂知识实体。
3072 维不是重点,重点是你终于可以按成本来调“语义密度”
做系统的人都知道,维度本身并不是越大越好。更大的维度意味着更高的存储成本、更高的计算开销、更长的检索延迟。Gemini Embedding 2 默认输出 3072 维,但支持用 output_dimensionality 调整维度,官方推荐的常见选择是 768、1536、3072,并说明它支持从 128 到 3072 的灵活输出。这个能力背后用的是 MRL(Matryoshka Representation Learning)
简单说就是:你可以根据场景,在“效果”和“成本”之间做更细粒度的平衡。
●如果你是大规模通用检索,1536 维可能就已经很香;
●如果你追求极致成本和吞吐,768 维会很有吸引力;
●如果你做的是高价值高精度场景,3072 维会更稳。
免费吗?多少钱?
Gemini Embedding 2 现在有两条主路径,想快速试、想低门槛上手,用 Gemini Developer API;想走企业治理、云权限、生产环境,走 Vertex AI。
第一条是 Gemini Developer API。
这一条更轻,适合开发者快速试。官方价格页明确写了:gemini-embedding-2-preview 当前有 Free Tier,文本、图片、音频、视频输入在免费层里都是 Free of charge。免费层数据 Used to improve our products: Yes;如果切到付费层,这一项会变成 No。付费价格方面:
●标准模式下文本是 $0.20 / 1M tokens
●图片约 $0.00012 / 张
●音频约 $0.00016 / 秒
●视频约 $0.00079 / 帧;
如果用 Batch API,价格大约是标准价的 50%。
第二条是 Vertex AI。
这一条更偏企业与云上生产环境。你需要 Google Cloud 项目、启用 billing、开启 Vertex AI API,并配置认证;而且 AI Studio 的 API key 不能直接用于 Vertex AI。模型页还写明:Gemini Embedding 2 当前支持的是 Standard PayGo,不支持 Provisioned Throughput、Flex PayGo、Priority PayGo 和 Batch Prediction,当前页面列出的区域是 us-central1。Vertex AI 价格页对它的专属条目写的是:
●文本 $0.2 / 1M tokens
●图片 $0.00012 / image
●视频 $0.00079 / frame
●音频 $0.00016 / sec
●输出不收费。
两个很容易踩的坑
第一个坑,是不要把旧向量直接拿来和新模型混用。
gemini-embedding-001 和 gemini-embedding-2-preview 的 embedding spaces 不兼容。也就是说,如果你准备升级到 Gemini Embedding 2,旧数据不能直接拿来比较,你需要重新做一遍 re-embedding。这对已经有存量索引库的团队来说,是非常现实的迁移成本。
第二个坑,是不要把“视频支持时长”写得过于绝对。
目前官方资料里有三种写法:
●Google 博客写的是支持最多 120 秒视频;
●Gemini API 文档写的是视频上限 128 秒;
●Vertex AI 模型页则更细,写成带音频视频上限 80 秒,不带音频视频上限 120 秒。
所以总结来说它当前具备 2 分钟级别的视频原生 embedding 能力,更长的视频仍建议切片后索引。
它不会消灭所有复杂度,但它确实改写了“默认架构”
Gemini Embedding 2没有神奇到让多模态检索从此没有工程问题。
它不会自动帮你解决 metadata、chunking、权限隔离、召回融合、在线延迟、索引更新这些老问题。
但它确实把过去那种“多模态一定要多套模型、多套索引、多阶段拼装”的默认范式,往前推了一大步。
更重要的是,这一步不是停留在“论文层面”的。Google 已经给出了官方接入路径,也已经列出 LangChain、LlamaIndex、Haystack、Weaviate、Qdrant、ChromaDB 和 Vertex AI Vector Search 等生态集成方式。也就是说,这不是一个“看上去很厉害但暂时用不起来”的能力,它已经开始变成开发者今天就能碰、今天就能试、今天就能接进系统里的东西。
所以,Gemini Embedding 2 真正改变的,可能不是“embedding 这个模型又进步了多少”,而是:
Google 终于把多模态检索,从一项需要大量拼装和妥协的工程活,推进成了一种更统一、更自然、更接近基础设施的能力。
最后
如果文本、图片、音频、视频、PDF 真的开始共享一个语义空间,接下来最值得重新思考的问题,也许就不再是:
“我还能接多少模型?”
而是:
在我的系统里,什么才算一个真正值得被检索的对象?
是一段文字,
是一页 PDF,
是一张图,
是一条帖子,
还是一个由图文、声音、视频共同组成的“实体”?
Gemini Embedding 2 给出的,不只是一个新模型。
它更像是在提醒所有做 AI 应用的人:
下一代检索系统要统一的,从来不只是接口,而是我们理解世界的入口。