导读: 在 AI 辅助编程普及的今天,你的团队是怎么写代码的?是靠开发者随心所欲的“自然对话”,还是有严谨的工作流约束? 本文将为你详细拆解“轻量 Harness 化 AI 研发工作流”的设计思路、工具选型与落地路径。无论你是独立开发者还是研发团队负责人,这套直接可抄作业的 Workflow 都不容错过。
一、 AI 编程的“向左走向右走”
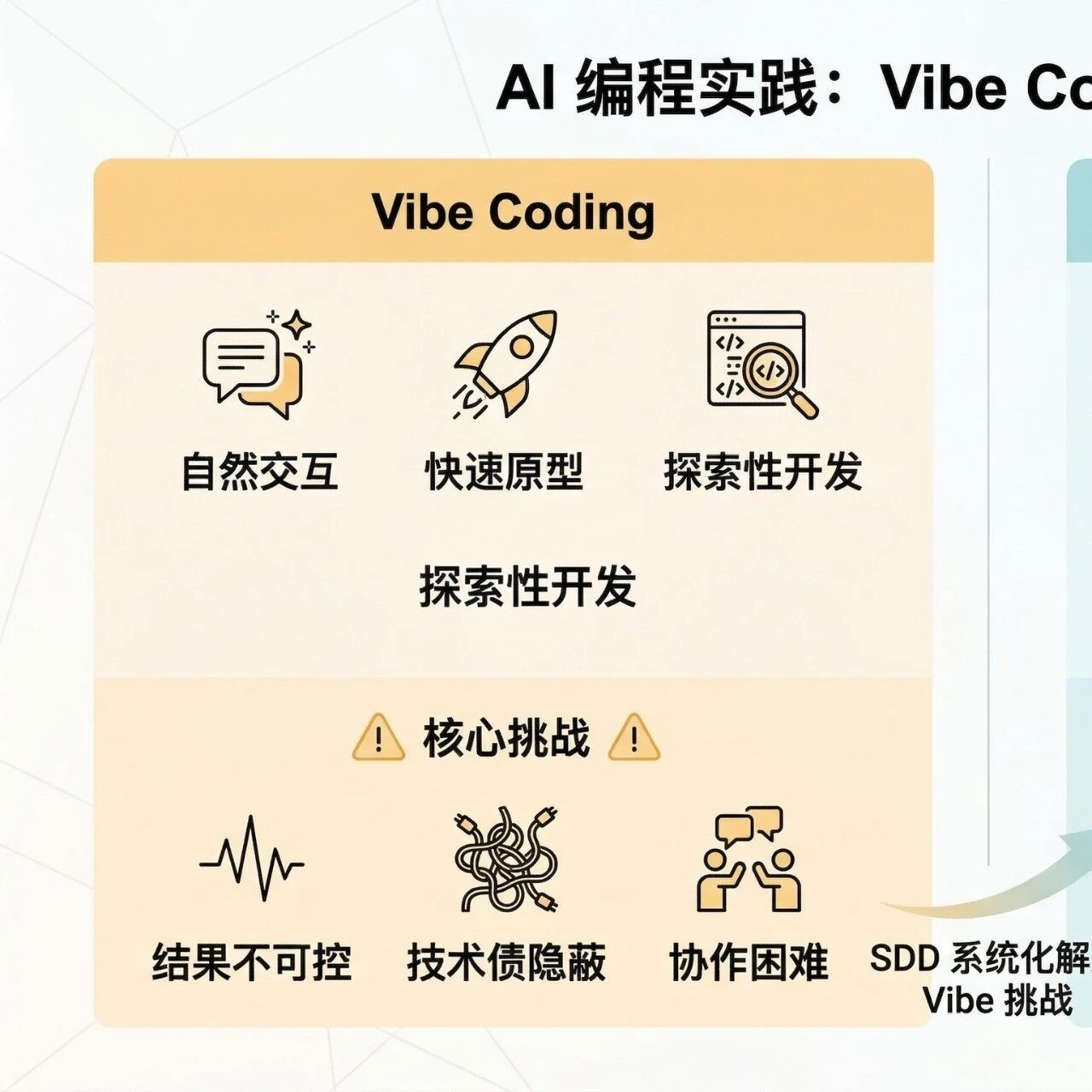
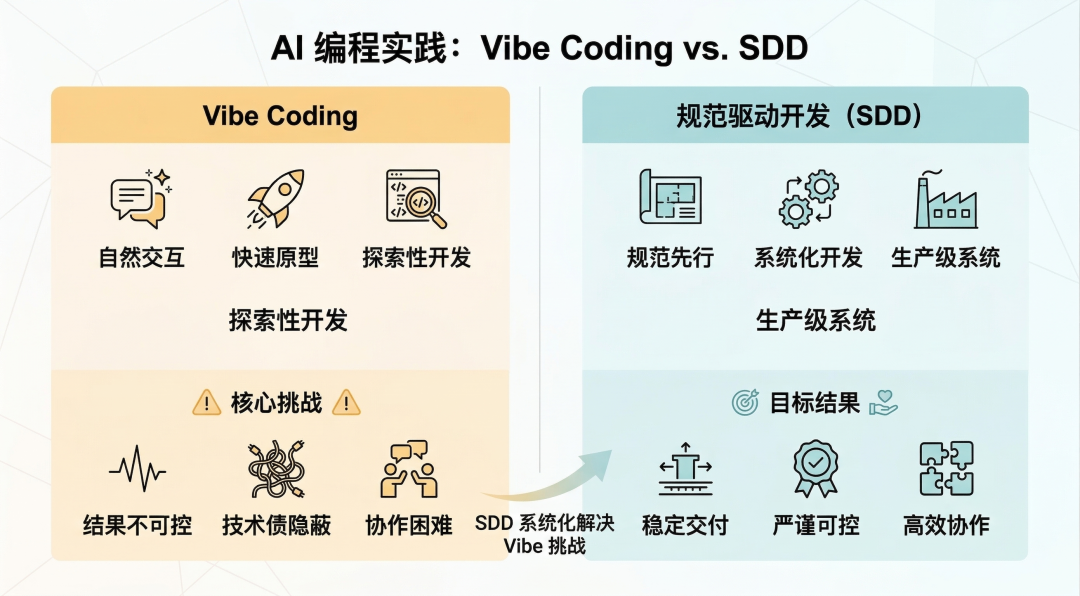
当前 AI 编程的实践,大致演化出了两条截然不同的路径:Vibe Coding 与 规范驱动开发 (SDD)。
| 维度 | 🎨 Vibe Coding (直觉编程) | 📐 规范驱动开发 (SDD) |
|---|---|---|
| 核心理念 | 自由交互,强调开发者与 AI 的自然对话 | 规范先行,以 Spec 为唯一事实来源 |
| 适用场景 | 快速原型、概念验证、探索性开发 | 生产环境、复杂系统、高质量要求 |
| 侧重点 | 提示词 (Prompt) 工程的灵活性 | 规范的严谨性与完整性 |
⚠️ Vibe Coding 的隐患:
随着大模型能力的增强,Vibe Coding 搭配插件确实能快速出活。但在团队级实践中,它暴露出 4 个致命问题:
1.效果不可控:不同模型、不同 Prompt 风格的产出质量参差不齐。
2.幻觉难约束:缺乏结构化约束,强如顶尖模型也会“胡编乱造”。
3.技术债隐蔽:表面跑通了,底层可能埋下了架构和质量的“雷”。
4.协作难统一:个人习惯各异,大规模协作时极易失控。
正是为了系统性解决这些痛点,SDD (Spec-Driven Development) 应运而生。
二、 什么是 SDD?它为什么重要?
💡 核心理念: 在 SDD 中,规范(而非代码)才是唯一的事实来源。开发者编写严谨的自然语言规范,由 AI 自动生成、测试并维护代码。 参考阅读:GitHub Spec-Driven Development
采用 SDD,意味着研发范式的三大转变:
○🔄 权力反转:过去是“需求文档服务于代码”(代码写完文档就废了);现在是“代码服务于规范”(代码只是规范的衍生品)。
○🛤️ 工作流重塑:修 Bug 或加功能,不再直接改代码,而是先更新规范,再让 AI 重新生成代码。
○🛡️ 两道防线约束质量:
▫模板约束:强制 AI 聚焦业务逻辑。遇到模糊需求必须提问([需要澄清]),杜绝瞎猜。
▫架构宪法:设定硬规则(如:必须先写测试并确认失败,才能写业务代码;强制模块化等)。
🎯 终极价值:消除需求与实现之间的鸿沟,让程序员从“敲代码的打工人”进化为“定义系统意图的架构师”。
三、 击中痛点:告别“实现漂移”
主流 AI 工作流为何纷纷拥抱 SDD?因为它解决了一个核心顽疾——实现漂移 (Implementation Drift)。
在随意的 Vibe Coding 中,代码层的知识无法被提取和固化。AI Agent 就像一个失忆的工人,缺乏上层显性知识和关键上下文,导致:
○效率低下:每次开发都要让 AI 重新从底层啃代码,无法高层建瓴。
○知识断层:编程规范、技术约束无法沉淀。
○协作困难 & 质量崩塌:Bug 和技术债越滚越大。
四、 主流 SDD 工作流大比拼
社区中已涌现出众多优秀的 SDD 实践方案,我们进行了深度体验对比:
| 工作流 | 定位与特色 | GitHub 仓库 | 实践痛点 |
|---|---|---|---|
| Spec-Kit | 官方工具链,全链路 (constitution/spec/plan/tasks/implement) 完整 | github/spec-kit | 流程重、Token 消耗大、耗时长、维护成本高 |
| OpenSpec | 轻量级 SDD 实现,更灵活 | Fission-AI/OpenSpec | 需人为设计流程,上手门槛较高 |
| GSD | 强调 fresh context 和 map-codebase 的分阶段框架 | gsd-build/get-shit-done | 棕地项目知识总结极佳,但完整流程耗时长 |
| superpowers | Skills 驱动,强调 brainstorming, TDD 和 review | obra/superpowers | 亮点突出,但整体流程中部分步骤相对薄弱 |
| compound engineering | 闭环流程 (Brainstorm→Plan→Work→Review→Compound) | EveryInc/compound-engineering-plugin | 流程合理,但对棕地项目的存量知识沉淀不足 |
结论: 在生产环境中,我们需要平衡开发效率、代码质量和 Token 成本。目前没有任何单一工作流能完美兼顾,强行绑定只会让开发体验打折。
五、 破局策略:组合最优解(缝合怪战术)
基于上述痛点,我们的落地策略是:取各家之长,组合使用。
○阶段一(当下):做“缝合怪”。串联 GSD + compound engineering + superpowers 的最佳环节,先跑通验证。
○阶段二(未来):逐步过渡到自研工作流,形成完全契合团队基因的 AI 编程链路。
🛠️ 工具选用原则与雷达图:
| 流程环节 | 选用工具 | 选用理由(最佳平衡点) |
|---|---|---|
| 🔍 Codebase 分析 | GSD /gsd:map-codebase | 对棕地项目(遗留系统)分析最全面完整 |
| 🧠 Brainstorm | CE /ce:brainstorm | 探索速度与效果的最优平衡 |
| 📝 Plan | CE /ce:plan | 兼具效率和生成质量,Token 消耗合理 |
| 💻 Work | Claude Code / Codex | 无需特殊指令,明确方案下 AI Agent 自主能力已足够 |
| 👀 Review | superpowers (自然语言) | 综合表现最佳:不慢、不冗长、反馈极具价值 |
| 📈 Compound | GSD /gsd:map-codebase | 支持增量更新,自动识别并沉淀项目变化 |
(注:CE 为 compound engineering 的简称)
六、 终极实战:六步法完整工作流
综合打磨后,我们得出了这套黄金六步法。它与 Compound Engineering 的流程高度重合(因其设计合理),但我们补齐了 Codebase 环节,并替换了部分步骤的具体实现。
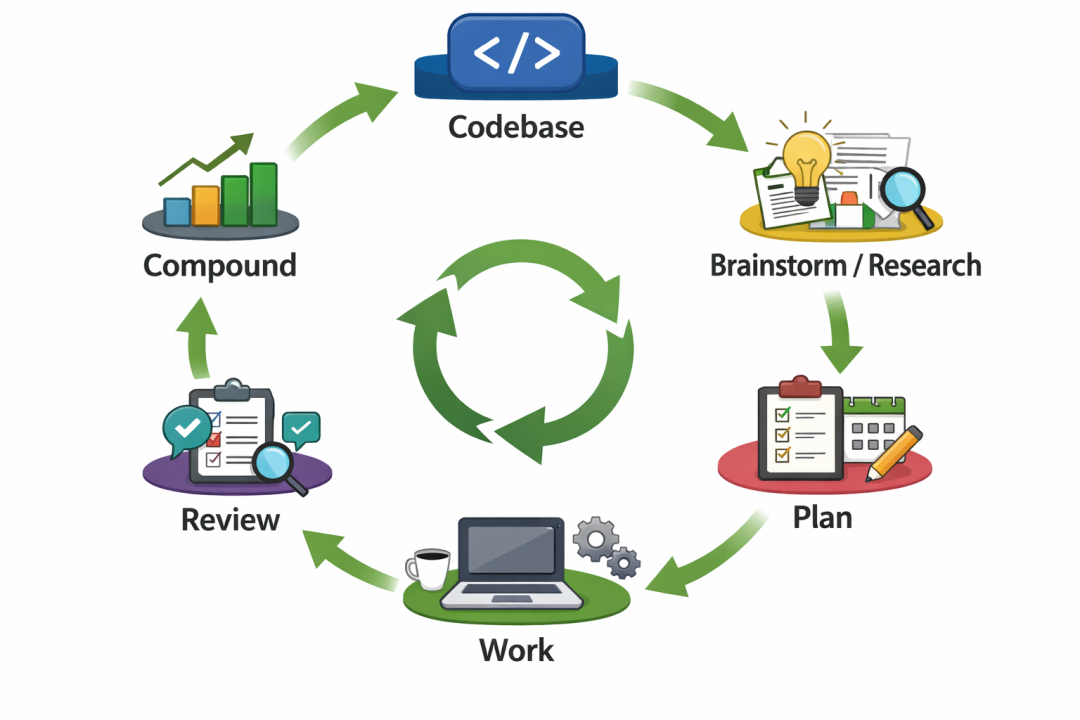
👣 Step 1: Codebase (建立项目认知)
○执行方式:运行 GSD 的 /gsd:map-codebase。
○作用:并行拉起多个代理,全面提取架构文档、规范、外部集成、技术栈、风险点。为后续开发提供关键上下文。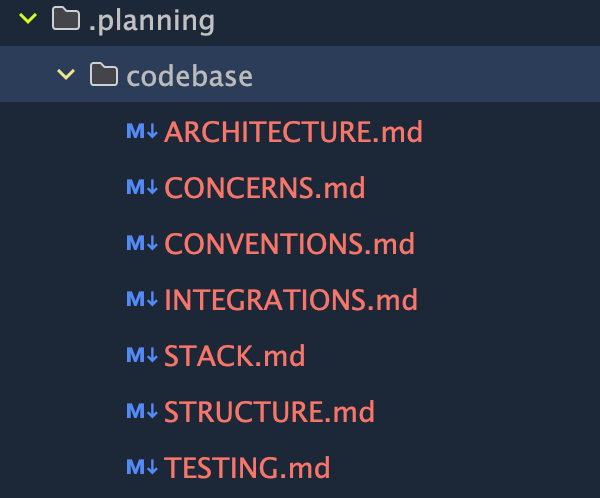
👣 Step 2: Brainstorm / Research (技术方案探索)
○执行方式:运行 /ce:brainstorm。
○作用:结合项目现状探索可行性方案,效率与效果极佳。
👣 Step 3: Plan (制定开发计划)
○执行方式:运行 /ce:plan。
○作用:总结探索成果,输出高质低耗的开发计划。
👣 Step 4: Work (执行开发)
○执行方式:直接对话使用 Claude Code 或 Codex。
○作用:为什么不加约束?因为前置方案已明确,放开手脚让 AI 自主调用工具和子代理,反而能最大化效率。
👣 Step 5: Review (代码审查)
○执行方式:通过自然语言触发 superpowers,例如:
“用 superpowers 对最新的一次 commit 进行 code review”
○作用:提供速度适中、精炼且极具价值的代码质量反馈。
👣 Step 6: Compound (知识复利)
○执行方式:再次运行 /gsd:map-codebase。
○作用:沉淀显性知识(业务逻辑、技术决策等)。支持增量识别,无需每次代码变更都执行。建议执行时机:Feature 完成时、做出重要技术决策时、架构显著变化时。
七、 灵活适配:按场景“裁剪”流程
全套流程虽好,但没必要杀鸡用牛刀。团队可根据任务粒度自由裁剪:
○🚀 完整 Feature 开发 (工作量大):Codebase → Brainstorm → Plan → Work → Review → Compound
○🏃 中等粒度任务 (方案清晰):Codebase → Work → Review → Compound
○🔧 小型修复/调整 (日常 Bug):Codebase → Work → Review
○🩹 快速修补 (十万火急):Codebase → Work
⚠️ 避坑指南: 即使使用短流程,也要记得定期执行 Compound (/gsd:map-codebase) 沉淀知识,防止“实现漂移”死灰复燃!
八、 建立知识沉淀体系(动静分离策略)
通过上述 Workflow,项目会自然沉淀出两类核心资产,我们称之为动静分离:
1.🔄 Codebase 文档 (动态,全队共享)
由 /gsd:map-codebase 自动刷新,包含项目结构、模块关系、依赖分析。它是 AI Agent 的“实时地图”。
2.📌 CLAUDE.md / AGENTS.md (静态,手动维护)
用于兼容不同 AI 工具的内容一致性文件。主要记录开发规范、技术约束、业务规则和“绝对禁区”。不频繁变更。
(除这两者外,其他过程文档在开发结束后可直接删除或归档。)
九、 驾驭工程的核心:上下文工程
有工具还不够,AI 编程的终极壁垒是:将隐性知识转化为显性知识。
不要指望 AI 自己去翻代码找表结构,这不仅慢而且容易错。我们需要主动投喂“AI 友好的知识形态”(Context Engineering)。
✅ AI 喜欢的格式:
○.md Markdown 文件 (如 PRD 文档)
○.sql 数据库脚本 / 表结构导出
○结构化的 Schema / JSON / YAML (如 UI 交互描述)
○CLI 命令行工具 / Bash 脚本
❌ AI 讨厌的格式:
○Word、Excel、PPT 等非结构化办公文档。
落地建议: 团队需建立规范,确保业务规则、设计图和数据结构在进入工作流前,已被转化为上述机读友好的格式。这是划定 AI 操作边界、消除幻觉的关键。
🛠️ 附录:工具链安装避坑指南
为了方便大家上手,我们整理了三大工具的安装差异。整体结论:建议统一使用 Claude Code 执行工作流,支持度最好。
| 工具 | Claude Code 安装姿势 | Codex 安装姿势 | 差异与踩坑点 |
|---|---|---|---|
| GSD | npx get-shit-done-cc --claude --global (或 --local) | npx get-shit-done-cc --codex --global (或 --local) | 同一个 installer,Codex 侧是 skills-first,最省事。 |
| superpowers | /plugin install superpowers@claude-plugins-official | 需 clone 仓库 + 建立 symlink 到 Codex skills 目录。详见 Codex 官方文档 | 明显 Claude-first,Codex 需要繁琐的手工安装。 |
| compound-engineering | 先 /plugin marketplace add EveryInc/compound-engineering-plugin | ||
再 /plugin install compound-engineering | bunx @every-env/compound-plugin install compound-engineering --to codex | Claude 是原生插件;Codex 是转换安装(且官方标明为 experimental)。 |
🔗 传送门:
○GSD: https://github.com/gsd-build/get-shit-done
○superpowers: https://github.com/obra/superpowers
○compound-engineering: https://github.com/EveryInc/compound-engineering-plugin