
事情是这样的。
最近我几乎每天都在用Claude Code写东西。用得越多,我越产生一种奇怪的感觉。
就是你给它下完一个任务之后,它开始一步一步地干活。先是啪,读了一个文件。然后哒,想了几秒。然后啪,又打开一个文件。再想几秒。再打开一个文件。就这么一直持续下去。
你坐在椅子上看着进度条一格一格地亮起来,心里清楚得不能再清楚,这十个文件它明明可以一起读的,它们之间根本没有任何依赖关系。
但它就是不。它就是要一个接一个地来。
一时间无语凝噎。
后来我跟几个同样重度用Agent的朋友聊了一下,他们也都有这个感受。说真的我始终觉得这是现在所有Agent产品共同的一个病,不管是 Claude Code、Cursor、Manus还是那些MCP插件,只要你让它干稍微复杂一点的活,你就会看到它在那里慢悠悠地一步一步走,像一个做事非常有耐心但完全不会一心二用的老实人。
前两天跟朋友吐槽这事的时候,我又想起了两年前Berkeley那帮人写的一篇论文。论文叫LLMCompiler,2024年就发在ICML上了,现在回头看它也不算新东西。但每次我被Agent气到的时候都会想起它,觉得它的思路到今天都没过时,甚至越品越有味道。
它当时就已经把这个病的根源讲得很清楚了,这个慢不是LLM的错,也不是任务复杂度的错,是我们给它用的那套调度系统,还停留在1960年代的水平。

这篇论文的名字挺干的,叫**《An LLM Compiler for Parallel Function Calling》**,ICML 2024。作者是Sehoon Kim、Amir Gholami那帮人,都在Berkeley和LBNL。它不是今年的新论文,但在我心里一直是Agent方向上最被低估的几篇之一。
它在做的事其实非常cool。
它在把大学一年级《计算机组成原理》那本书里的东西,原样搬到LLM的世界里。
坦率的讲,你想想看过去60年整个计算机体系结构的历史,其实就是一部「怎么让本来是串行的指令跑得更并行」的历史。指令流水线、乱序执行、超标量、分支预测,这些听着就头大的名词,说到底都是在干一件事,就是让CPU不要一条指令一条指令傻乎乎地等,能同时干的活就一起干。
这套东西人类已经研究得非常透了。透到什么程度呢?透到你今天买一颗普通的i5芯片,它每个时钟周期能同时发射的指令数,大概是80年代那种整栋楼的超级计算机的水平。
但是。
当我们把LLM当成一种新型处理器去用的时候,这套智慧全忘了。
现在几乎所有的Agent框架,底层都是一个叫ReAct的东西。它是Yao等人2022年提的,全称是Reason + Act。工作方式非常朴素,想一步,做一步,看结果,再想一步,再做一步,再看结果。它是一个循环。
听着很自然对吧?它确实自然。但你仔细看就会发现,这玩意从执行效率上来说,跟那种每次只能执行一条指令、做完一条才开始下一条的远古处理器,是一样的。
一次一条。干等。
而且这个问题在越来越多的Agent场景里暴露得越来越厉害,因为我们现在给Agent的活越来越复杂,一次要调用的工具越来越多。ReAct的串行执行就成了一个越来越重的镣铐。
回到LLMCompiler这块。
作者的思路简单粗暴,既然Agent执行工具调用的过程跟CPU执行指令长得一样,那就直接套编译器的架构好了。他们搞了三个组件。
第一个叫 Function Calling Planner,函数调用规划器。你可以把它想象成编译器里那个分析语义、构建依赖图的部分。用户给了一个问题,比如论文里举的那个例子,「微软的市值需要涨多少才能超过苹果?」,Planner要做的事情是先把这个问题拆成几个独立的任务,再搞清楚这些任务之间谁依赖谁。
它会拆成三步。
一,去查微软的市值。 二,去查苹果的市值。 三,用一个数学工具做减法,把差值算出来。
然后它会发现一件事,任务1和任务2,彼此没有任何关系。它们完全可以同时去查。只有任务3需要等前两个都拿到结果。
这就是一张 DAG,有向无环图,编译器里最核心的数据结构之一。
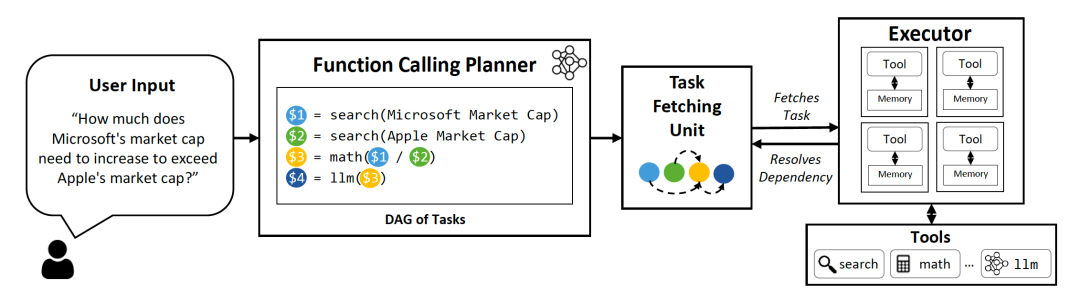
第二个组件叫 Task Fetching Unit,任务获取单元。这个名字直接就是从CPU里偷来的。
在现代CPU里有一个东西叫指令获取单元,它的任务是一旦前一条指令把某个寄存器的值算出来了,立刻把依赖这个寄存器的下一条指令发射出去,别等一整串指令都准备好再开搞,那样太慢。
LLMCompiler的Task Fetching Unit做的事完全一样。Planner一吐出DAG,它就开始扫描,发现哪些任务的依赖已经解决了,立刻往下扔。任务1和任务2没有依赖?好,同时发射,两个搜索并行执行。任务3等着1和2的结果?好,等它们回来我再把结果塞进任务3里,然后发射。
整个过程是流式的。Planner一边在吐计划,执行器一边在干活,中间没有「等Planner把所有计划全想完再开始」这种停顿。论文里专门做了个消融实验,流式处理本身就贡献了一个量级的加速。
第三个组件叫 Executor,执行器。这个没啥好说的,它就是真正去调工具的那个家伙。Task Fetching Unit告诉它哪个工具可以调了,它就调。
三个东西加起来,整个架构就跟一台小号的CPU一模一样。有人分析程序,有人调度,有人执行。
说到这我真的有点被打动。你知道我为啥被打动吗?因为这个思路其实任何一个学过编译原理的本科生都能想到。它没有任何复杂的数学,没有什么神秘的训练技巧,就是把一个用了60年的老配方,拿来炒一道新菜。
但它偏偏有效。而且效果好到离谱。
顺着上面的再聊聊,这篇论文最让我兴奋的其实是实验结果部分。
作者用了四个benchmark来测试LLMCompiler。这四个测试排起来有一个隐藏的升番结构,从最简单的场景到最复杂的场景,效果一个比一个炸。我逐个说一下。
第一个叫HotpotQA。这是个很经典的多跳问答数据集,论文的Figure 1就举了一个例子,「斯科特·德瑞克森和埃德·伍德是不是同一个国籍?」这种问题。用ReAct的话就是一步一步来,先搜A,拿到结果,再搜B,拿到结果,再对比。用LLMCompiler的话,A和B可以同时搜。
速度快了1.8倍。成本降了3.37倍。准确率基本一样。
就这个结果拎出来看已经很能打了,但它只是开胃菜。
第二个叫Movie Recommendation。这个更有意思,它每次要你从8部电影里找出跟某部电影最像的那部。也就是要对8部电影分别做独立的搜索和分析。
ReAct在这里干了一件特别傻的事。论文附录里有一张图我看完直接笑出声,它显示有大约85%的样本,ReAct根本没搜完8部就结束了。它搜到第五部就停下来,觉得「我好像够了」,然后给一个答案。
你敢信???
一个号称能干活的Agent,居然连把活干完都做不到。它会提前认输。
LLMCompiler在这里就完全没这个问题,因为Planner一开始就把8个任务全部规划好了,Executor必须全部执行完才能汇总。结果是速度快了3.74倍,成本降了6.73倍,准确率还反超ReAct 7个多点。
第三个叫Game of 24。这游戏你们可能玩过,给你4个数字让你用加减乘除搞出24。之前最强的解法叫Tree-of-Thoughts,让LLM自己去搜索各种可能的组合。LLMCompiler在这里做了一个很骚的事,它把「Tree-of-Thoughts的一次尝试」当成一个工具,然后让Planner去并行调度这些尝试。
速度快了2倍。
到这里我已经觉得够牛了。
但是真正让我给整不会的是第四个benchmark,WebShop。这是一个模拟网上购物的环境,你要在一堆商品里找到符合某些需求的那一个。典型的操作是搜索→看结果→再搜索→再看结果。
LLMCompiler在这里直接跑出了101.7倍的加速。
不是10倍,不是50倍,是一百零一点七倍。
而且成功率还比ReAct高了25.7个百分点。
我第一次看到这个数字的时候真的愣住了。我来回看了好几遍论文的表格,生怕自己看错了小数点。101.7x。
它的原因其实非常直观。WebShop里有大量「先广撒网再选最优」的搜索动作。LLMCompiler可以一口气把所有候选搜索并行发射出去,而ReAct得一个一个搜。你想想,如果你在淘宝上找一个东西,你是一次打开十几个标签页横向对比,还是一个一个点开再返回再点开?
答案很明显。
但前者需要你有一个「规划」的能力,得先知道哪十几个是值得看的。这恰好就是LLMCompiler在做的事。

这块需要注意一下。LLMCompiler的意义不只是快,还有一个更深的点,它顺手救了准确率。
这个我刚才提到了一嘴,但值得展开说说。作者分析了ReAct失败的案例之后发现,这些失败的绝大多数其实跟智力无关,跟纪律有关。
两种典型的失败场景。一种是提前收工,它只搜了部分信息就觉得够了,开始瞎答。另一种更惨,是它会在同一个查询上无限循环,因为Wikipedia返回的信息不够精确,它就一直搜一直搜一直搜,直到context window爆掉。
这两种失败加起来,贡献了ReAct绝大部分的失败样本。
为啥会这样?我自己的理解是,ReAct是一种即兴架构。它没有全局视野,每一步都是基于上一步的观察临时决策的。这种即兴决策模式很像我们人脑,但它也天然带着人脑即兴决策的毛病,容易累、容易放弃、容易走进死胡同。
LLMCompiler强迫模型在一开始就把所有要做的事列出来,这等于逼着它做一次系统性的规划。规划好了之后,执行阶段就只负责执行,不再思考。
我觉得这里有一个非常深的启发。我们过去几年一直在迷信让LLM多想一步,搞出了Chain-of-Thought、Tree-of-Thoughts、Self-Reflection各种花活,都是在鼓励模型「思考得更细、更久、更多」。但其实有时候反过来,让它先想一次然后别再想了,反而更管用。
CPU的设计哲学其实也是这样。现代CPU里最快的指令是那些不需要跳转、不需要预测、不需要动态决策的指令。凡是涉及到走一步看一步的指令,都会拖慢整条流水线。
计算机硬件的人早就发现了,即兴决策是昂贵的。
而这个老道理,现在又回到了AI Agent这边。
坦率的讲,我觉得LLMCompiler这篇论文本身可能不是最大的新闻。真正的新闻是它揭示的那个更大的趋势。
我们正在把整个计算机体系结构,重新发明一遍。
你仔细想想这几年LLM推理和Agent方向上那些最亮眼的突破,几乎每一个都能在老教科书里找到原型。
Speculative decoding,是把CPU的分支预测搬到了LLM推理。 KV cache,是把CPU的cache机制搬到了LLM推理。 Continuous batching,是把操作系统的进程调度搬到了LLM推理。 现在LLMCompiler,是把编译器的指令调度搬到了LLM Agent。
每一个都在发生。每一个都带来10倍甚至100倍的加速。每一个的核心创意都不是横空出世的神来之笔,而是一句「等等,这个问题我们在硬件/OS层面已经解决过了,直接拿来用就好」。
卡帕西前阵子说过一句我记了很久的话,他说LLM是一种新的计算机,一种以自然语言为指令集的计算机。这句话如果你真的认真对待,那它的所有推论都是自洽的。既然它是一种新的计算机,那我们给旧计算机发明的所有优化技巧,理论上都应该能再用一次。
我有时候会觉得,我们这一代做AI的人特别幸运。我们在亲眼看一部已经拍过一遍的电影,被用新的道具重新拍摄。剧本是一样的,角色是一样的,剧情走向都是一样的。但因为道具全换了,看起来就像一部全新的片子。而且你手里只要有一本原版的剧本,你就能提前知道下一幕会发生什么。
回到这篇论文本身。
我觉得它最重要的贡献其实不是那些benchmark数字,而是它开了一个非常清晰的方向。那就是Agent的慢不是不可解决的。
你今天用Claude Code等十分钟,不是因为LLM笨,也不是因为你的任务太复杂。是因为底下那套调度系统还在用ReAct这种20世纪60年代级别的执行模式。只要换上哪怕一个粗糙的编译器思路,立刻就能快10倍、快100倍。
其实这两年已经有不少框架在往这个方向走了,LangGraph、LlamaIndex都陆陆续续搞过类似的planner组件,多Agent框架里的并发调度也都能看到这套思路的影子。但奇怪的是,我们日常在用的那些最主流的Agent产品,Claude Code、Cursor这些,还是没有把这套东西吃得特别透。你还是经常能看到它们在那里一步一步串行地跑,跑得你抓狂。
我始终觉得这是一件很可惜的事。一个两年前就该被充分吸收的好思路,到今天还只在部分框架里存在,绝大多数用户还是在吃ReAct的苦。
其实之前OpenAI做过一个简化版,它叫Parallel Function Calling。但这篇论文里也明确对比了,OpenAI那个只能处理最简单的、完全独立的并行任务,一碰到有依赖关系的就歇菜了。LLMCompiler能处理有依赖的完整DAG,这是质变。而且论文在ParallelQA这个他们自己造的benchmark上,直接把OpenAI的并行函数调用给干穿了。
还有一个让我很开心的点,LLMCompiler不依赖特定模型。它能跑在闭源的GPT系列上,也能跑在开源的LLaMA-2 70B上,效果都很好。这意味着你要用它,不需要求爷爷告奶奶去办一个特殊API,自己拿个开源模型搭一套就能跑。对整个开源生态是实实在在的利好。
论文的代码早就开源在 https://github.com/SqueezeAILab/LLMCompiler ,这两年我零零散散跑过一些例子,整体感觉是它确实好使,但对Planner的prompt质量非常敏感,稍微写粗糙一点就容易崩。这大概也是为啥它没在主流产品里全面铺开的原因之一,论文里优雅的架构,落到工程上总会多出一堆脏活。
最后说点题外话。
我一直觉得AI这个行业最迷人的地方,就在于它需要你是一个杂食动物。你得懂一点机器学习,懂一点系统,懂一点产品,懂一点用户。因为AI正在跟所有领域发生化学反应,任何一个你以为已经过时的角落,都可能突然长出一个全新的方向。
LLMCompiler这篇论文就是一个典型的例子。它既不需要你是最顶尖的ML研究员,也不需要你是最强的系统工程师。它需要你有一个能从「我的LLM Agent跑得好慢啊」跳到「诶等等,CPU当年也有这个问题,是怎么解决的来着?」的跨界联想能力。
我始终觉得这种联想能力,比任何单一领域的深度都重要。
很多朋友问我怎么跟上AI的发展。我有时候觉得,与其拼命去看最新的模型发布,不如回头去翻翻那些老的、经典的、看起来跟AI毫无关系的书。编译原理、操作系统、计算机网络、数据库系统、图形学。这些书里有太多你以为已经过时的东西,在LLM时代突然又活了过来。
你读过的每一本旧书,都可能在未来某天变成一枚重新上膛的子弹。
前提是你得先把枪挂在墙上。
以上。