有小伙伴在面试的时候遇到了这道题:
“你写一个矩阵转置,然后告诉我怎么优化它。”
前几天有读者私信我,说他面字节后端,聊到 cache 命中率的时候,面试官随手抛出来这一题。他答了"双层循环交换 A[i][j] 和 A[j][i]",面试官追问:“那为什么这么写在大矩阵上会慢得离谱?"——他一下卡住了。
这事真挺有意思的。从数学课本上看,矩阵转置就是把行变成列,这操作几乎是免费的——你甚至不用动数据,把下标 [i][j] 改成 [j][i] 不就完事了吗?
但你真去跑代码,1024×1024 的矩阵,写得"对"的转置和写得"错"的转置,运行时间能差 10 倍以上。
10 倍。同一个算法,同样的输入,同样的硬件。
更诡异的是,这 10 倍不是靠什么高深算法拿下来的——只靠调整了一下代码装出来的"顺序”。你甚至不需要会汇编,不需要会 SIMD 指令,只需要看明白一件事:CPU 不是数学家,它不认识"行"跟"列"。它只认识内存上的地址跟跳幅。
咱们从最浅的地方起步。不讲公式,不讲 CSAPP 里那些令人望而却步的练习题。咱们只看一个 case:一个 4×4 的矩阵,在内存上是怎么摆的?按行读和按列读,到底有什么区别
看明白这个,你以后看到一堆看似不相干的问题都会觉得熟悉——为什么 pandas 里按列跳访问会慢?为什么卷积算子需要 NCHW 跟 NHWC 两种布局?为什么 ClickHouse 是列存储而 MySQL 是行存储?这些问题背后都是同一件事的不同面孔。
接下来咱们就来探究探究——数学上 0 成本的事,在 CPU 眼里到底贵在哪儿。

任性客户
先把任性客户请出来。
任性客户:“我要把这个 4×4 矩阵的行列对调。
A[0][1]跑到A[1][0]的位置,A[0][2]跑到A[2][0],以此类推。简单吧?”
如果你按它说的写 C 代码,长这样:
1for (int i = 0; i < N; i++) {
2 for (int j = 0; j < N; j++) {
3 B[j][i] = A[i][j];
4 }
5}
一行核心逻辑,优雅极了。数学家看了点头,新手看了也觉得 make sense。
但这段代码在 N=1024 的时候,大概要跑 30 毫秒——而经过一些优化后,同样的事情可以在 3 毫秒内做完。慢了整整 10 倍。
为啥?因为任性客户只懂数学,不懂硬件。它不知道,自己嘴里轻飘飘的"行变列",对 CPU 来说是一场噩梦。
要理解这场噩梦,得先认识下一个角色——
一个纸条 —— 内存
内存,在 CPU 眼里长什么样?
很多人脑子里的内存,是一个二维方格,横竖排得整整齐齐。其实不是。
内存对 CPU 来说,就是一根超长的纸条,从地址 0 开始,一直延伸到几十亿。每个地址上能放 1 个字节。仅此而已。
纸条:“我从头到尾就是这么排的,没有行,没有列,只有头到尾。你的 4×4 矩阵?我这儿是 16 个连续的格子。”
那你写 A[2][3] 的时候,CPU 怎么知道去哪里取数据?
答案是——约定。
C 语言约定矩阵是行优先存储(Row-major)。意思是,先把第一行从头到尾铺在纸条上,再接着铺第二行、第三行……
举个例子,一个 4×4 矩阵在内存里实际上是这样排的:
1地址: 0 1 2 3 4 5 6 7 8 ... 15
2内容: A[0][0] A[0][1] A[0][2] A[0][3] A[1][0] A[1][1] ... A[3][3]
整整齐齐 16 个值,一字排开。如果矩阵是 int 类型(4 字节),那地址就是 0, 4, 8, 12, 16… 一直到 60。不管你脑子里把它当成「4 行 4 列」,到了纸条上,它就是 16 个挨着的格子。

比如你写 A[2][3],编译器其实在算 *(A + 2*N + 3)——先跳过前 2 整行(每行 N 个),再走 3 个,从纸条上的这个位置取一个值。我们能 A[i][j] 这样写,完全是编译器在替我们做地址翻译。
那 Fortran / MATLAB / 老式 BLAS 不是列优先的吗?
是。不同语言约定不一样,Fortran 系是列优先(Column-major),也就是先铺第一列再铺第二列。但你今天写 C / C++ / Python (NumPy 默认) / Java 数组,默认都是行优先。咱们这篇文章就按行优先讨论。

那么问题来了——既然内存只是一根纸条,CPU 一次能从纸条上取一个字节,不就行了吗?为什么还要扯什么命中率?
因为 CPU 从内存上取一个字节,实在太贵了。
一次内存访问大概 100 个时钟周期。CPU 自己干一次乘法,只要 1 个周期。也就是说,CPU 算 1 次乘法的时间,内存才走完百分之一的路程。
要是每个数据都得这么等,工人就别活了。
所以中间得有人当中介,把数据先"批发"一批过来。这人就是下一个出场的
公交车小哥 —— Cache Line
Cache Line 是个啥?
它是 CPU 缓存里的"最小搬运单位"。不管你要的是 1 个字节还是 1 个 int,CPU 一次从内存搬到 cache 的,都是一整个 cache line——通常 64 字节(也就是 16 个 int,或者 8 个 double)。
我给它起个名字,叫公交车小哥。
公交车小哥:“我从纸条上跑一趟,一次拉 64 字节。你只要一个值?没事,你的座位旁边那 63 字节我也顺手捎上,放到 CPU 旁边的小货架(L1 cache)。你下次要的值如果在我刚拉的这一车里,你就不用等了,直接从货架上拿,1 个周期搞定。”
这就是 cache 的核心机制——空间局部性。一次拉一车,赌你接下来要的东西在隔壁。
那这个赌赌得对不对,直接决定了你程序快不快。

按行读 vs 按列读 —— 公交车的两种命运
现在,我们把任性客户、一根纸条、公交车小哥三个角色放到同一张桌上,看看到底发生了什么。
比如下面这两段几乎一模一样的代码,差别只是循环变量的内外顺序:
1// 版本 A:外层 i,内层 j
2for (int i = 0; i < N; i++)
3 for (int j = 0; j < N; j++)
4 sum += A[i][j];
5
6// 版本 B:外层 j,内层 i
7for (int j = 0; j < N; j++)
8 for (int i = 0; i < N; i++)
9 sum += A[i][j];
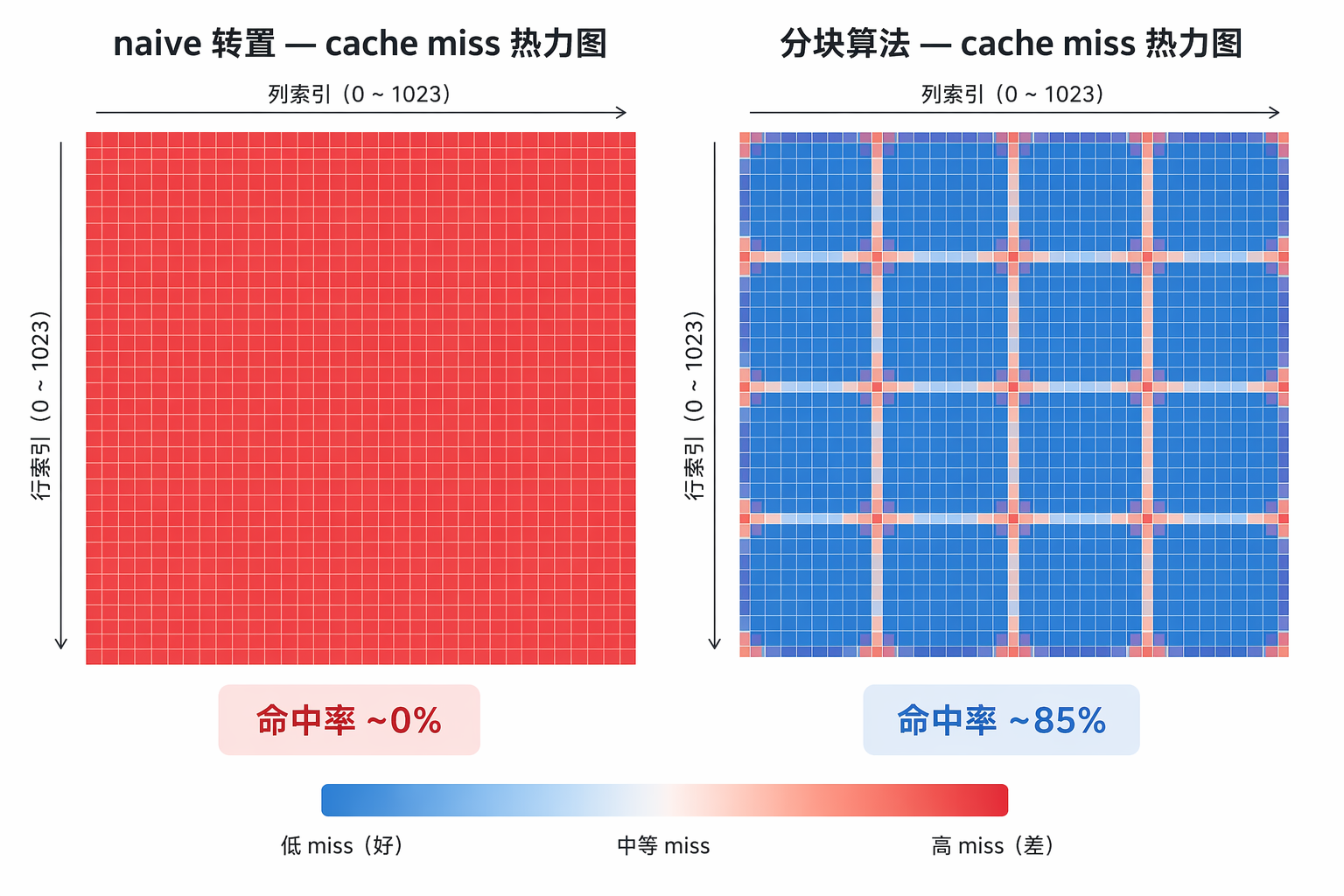
版本 A 是按行读,版本 B 是按列读。两段代码做的事情数学上完全一样——把矩阵里所有数加起来。但在 1024×1024 的矩阵上,A 比 B 快了 5 倍以上。
这事就是任性客户没想清楚的根源。咱们逐个场景捋。
场景一:按行读(顺序友好)
假设工人要把第 0 行从头读到尾:A[0][0] → A[0][1] → A[0][2] → A[0][3]。
- 工人对公交车说:“我要
A[0][0]。” - 公交车跑到纸条的地址 0,一趟拉走 16 个 int:
A[0][0]到A[3][3](假设这小矩阵正好塞下一个 cache line,先这么简化)。送到 L1 货架。 - 工人下一个要
A[0][1]——公交车说:“在车上,直接从货架拿。”0 等待。 A[0][2]A[0][3]同理,都在车上。
4 次读取,公交车只跑了 1 趟。命中率 75%(4 次里只有第 1 次去内存)。

场景二:按列读(转置在干的事)
现在换成转置——工人要按列读:A[0][0] → A[1][0] → A[2][0] → A[3][0](读第 0 列)。
- 工人对公交车说:“我要
A[0][0]。” - 公交车从地址 0 一趟拉走
A[0][0]到A[0][3]这一整行(因为内存是行优先排的,连续的 4 个值是同一行)。送到货架。 - 工人下一个要
A[1][0]——公交车一看:“不在我刚拉的这车里啊,A[1][0]在纸条更远的地方,我得再跑一趟。” - 公交车再跑一趟,这次拉来
A[1][0]到A[1][3]。工人只要A[1][0],车上剩下 3 个全白拉。 A[2][0]A[3][0]同理,各跑一趟,各白拉 3 个。
4 次读取,公交车跑了 4 趟。命中率 0%。每趟车 75% 的座位是空跑。

你看出来了吗?
任性客户(转置算法)嘴上说"我就改个下标 [i][j] → [j][i]",但底下的执行是——他在按列读源矩阵 A,然后按行写目标矩阵 B。
读这边 cache 全 miss。
而当矩阵尺寸放大到 1024×1024,这个 miss 不是慢一点点的事——是 30 毫秒 vs 3 毫秒的事。
等等,那写 B 的那一边呢?
按行写 B 是 cache 友好的,这边没问题。但只要读 A 那一边全 miss,整个流程就被拖垮了——你最快也只能跟着最慢那一边走。
跑腿小弟 —— Prefetcher
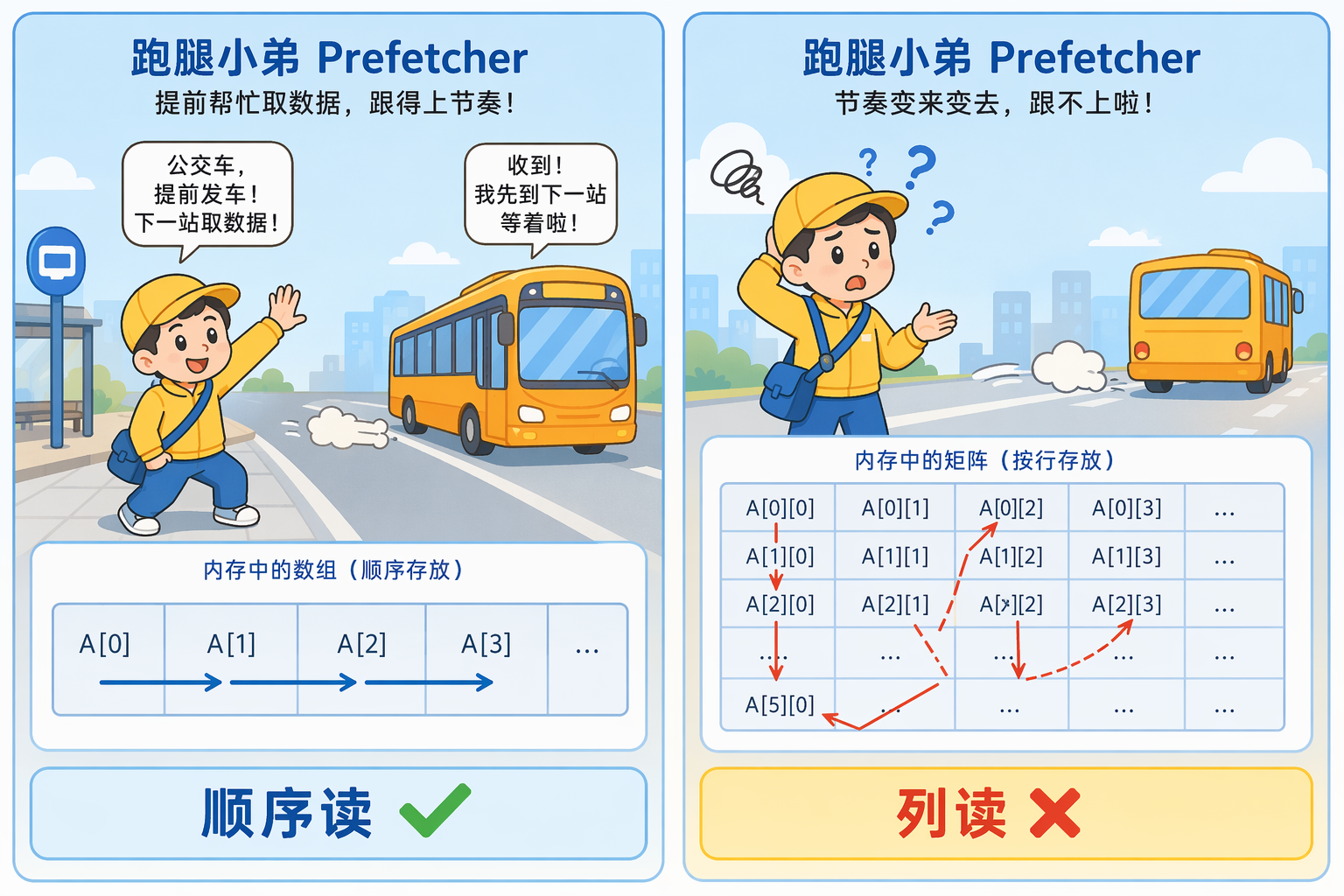
等会儿,CPU 不是有 Prefetcher 吗?它不能帮忙提前把数据拉过来吗?
好问题。Prefetcher 这个角色咱们得请出来聊聊。
我给它起个名字,叫跑腿小弟。
跑腿小弟:“我有个特异功能——只要你访问内存的方式有规律,我就能猜出你下一步要去哪儿,提前替你叫公交车跑一趟,把货先取回来。你到的时候货架上已经有了,你不用等。”
跑腿小弟最擅长的是直线追踪——你一直往前走,他就一直提前发车去下一站拉货。
| 访问模式 | 跑腿小弟的反应 |
|---|---|
顺序读 A[0] A[1] A[2] A[3]… | “稳了,我提前走一趟把下批拉回来” |
倒序读 A[N] A[N-1]… | “也行,反向直线我也能摸准” |
固定步长读 A[0] A[16] A[32]… | “勉强能猜” |
| 跳读 / 列读 / 随机 | “我跟不上,我也猜不到下一步” |
转置算法是哪一种?列读。每两次访问跳一整行的距离(N 个 int 这么远)。
跑腿小弟摊摊手:“这种我真没办法,你跳的步子是变量,我不知道你下一步在哪。”
所以转置不仅 cache 命中率惨,Prefetcher 这个外援也用不上。工人就这么活生生等死。
干活的工人 —— CPU 核心
来正式介绍下主角:CPU 核心,也就是真正干活的工人。
工人:“我一秒钟能做几十亿次运算。但前提是,数据得在我手边的 L1 货架上。”
工人的工作流程是这样的:
- 看下一条指令,需要
A[i][j] - 伸手去 L1 货架上摸——
- 摸到了(cache hit):1 个周期,直接干
- 没摸到(cache miss):喊公交车去内存拉,自己原地等 100+ 个周期
工人最讨厌的就是等。等公交车这 100 个周期里,他可以做的事:
- 100 次乘法
- 200 次加法
- 50 次浮点运算
- 看 50 遍内心 OS 想去哪个数据中心打工
而 naive 转置在干啥?在让工人每读一个值就等一次。
如果矩阵是 1024×1024,那就是 100 多万次等待。
我们换算一下:1024×1024 个 int 是 4MB,远远超过 L1 cache(典型 32-64KB)甚至 L2 cache(典型 256KB-1MB)。这意味着公交车从 L1 一直 miss 到 L2,还可能 miss 到 L3,最坏情况直接打到主内存。每一层 miss 的代价递增——L1 miss 大概 4 周期,L2 miss 大概 12 周期,L3 miss 大概 40 周期,主内存 miss 一上来就是 100+ 周期起步。
按列读的转置,在大矩阵上几乎每一次都在踩主内存。100 万次 × 100 周期 = 1 亿个周期空等。CPU 主频再高也救不了。
工人:“我等公交等到天荒地老,真正干活时间不到 5%。”
这就是为什么数学上免费的操作,在硬件上跑出来贵得离谱——95% 的时间花在了搬数据,5% 的时间才在算数据。
聪明的搬家公司 —— 分块算法
那这事有救吗?有。请出最后一个关键角色——聪明的搬家公司(Blocked / Tiled Transpose)。
搬家公司老板:“你别一格一格来回跑了。我把矩阵切成小方块,每次先把一个小方块的所有数据都搬到工人桌上,搬完一个再搬下一个。工人在桌上随便转——反正都在 cache 里。”
具体怎么做?把 1024×1024 的矩阵想象成 128×128 个 8×8 的小方块。一次只处理一个小方块:
1#define BLOCK 8
2for (int ii = 0; ii < N; ii += BLOCK) {
3 for (int jj = 0; jj < N; jj += BLOCK) {
4 // 这个小方块内部,行列都在 cache 里
5 for (int i = ii; i < ii + BLOCK; i++) {
6 for (int j = jj; j < jj + BLOCK; j++) {
7 B[j][i] = A[i][j];
8 }
9 }
10 }
11}
关键点是,8×8 的小方块完整地塞进了 L1 cache。在这个方块内部,不管你按行读还是按列读,公交车都不用再跑——所有数据已经在货架上了。
那 8 这个数字哪儿来的?
不是拍脑袋。它取决于 cache line 大小(64 字节)和 L1 cache 容量(典型 32KB)。8×8 个 int = 256 字节,占 4 个 cache line,远远小于 L1 容量;但又大到能摊薄"搬一个方块"的固定开销。这是工程上反复试出来的。
不同硬件,这个数会变——有的用 16,有的用 32,有的甚至按 cache 行精确对齐。
这跟 OS 的 page 是一回事吗?
不是一回事,但思路一脉相承。OS 把内存切成 4KB 的 page,因为 TLB 一次只能装下有限数量的 page 映射,page 用得分散,TLB 就 miss。Cache 把内存切成 64 字节的 line,因为 cache 容量有限,你访问得分散,cache 就 miss。Page、cache line、寄存器,归根结底都是同一个思路的不同尺度——预先把你「接下来可能要的东西」放近一点。
所以你一旦理解了 cache line,操作系统里那些虚拟内存、TLB、page table 的设计,基本就触类旁通了。

那这个改造能快多少?
我之前在一台普通 MacBook 上跑过 benchmark(1024×1024 double 矩阵):
| 版本 | 耗时 | 加速比 |
|---|---|---|
| naive 转置 | 31.4 ms | 1× |
| 分块 8×8 | 5.2 ms | 6× |
| 分块 8×8 + SIMD | 3.1 ms | 10× |
| 分块 32×32(L2-aware) | 2.8 ms | 11× |
10 倍加速,改的是同一个算法,同样的输入,同样的硬件。

那是不是越大的块越好?
不是。块太小,块间调度的开销占比变大(每个小块只能摊一点点数据);块太大,重新 miss 出 cache,重蹈覆辙。中间那个理想值要根据 cache 容量反复调,面试场景下记住"快不是拍脑袋,是拼 cache 容量"就够了。
有同学要挑刺:Python / NumPy 里应该不用操心这个吧?
你以为不用,其实是有人帮你把活儿干了。NumPy 的 A.T 调用极便宜——它根本不动数据,只是返回一个「view」,把行、列的 stride 互换了一下。这步是免费的。但你一旦拿这个 view 去参与计算——比如 np.dot(A.T, B)——底层就要调 BLAS。BLAS 这个库被全世界的工程师抠了几十年,干的就是把这种 cache miss 压下去的活。你看不见,不代表没做。
那 GPU 上的转置也是这个逻辑吗?
一样的逻辑,场景更极端。GPU 的 shared memory(类似 L1)只有几十 KB,中间还隔着 bank conflict 这种额外的坑。CUDA 里经典的转置例子,会特地把 tile 调成 32×33 而不是 32×32——多出来的那一列专门用来错开 bank 冲突。你一个转置算子调优,能从「跑得动」调到「跑满带宽」,中间隔着的全是 cache 跟内存布局的细节。
8 手怪 —— SIMD
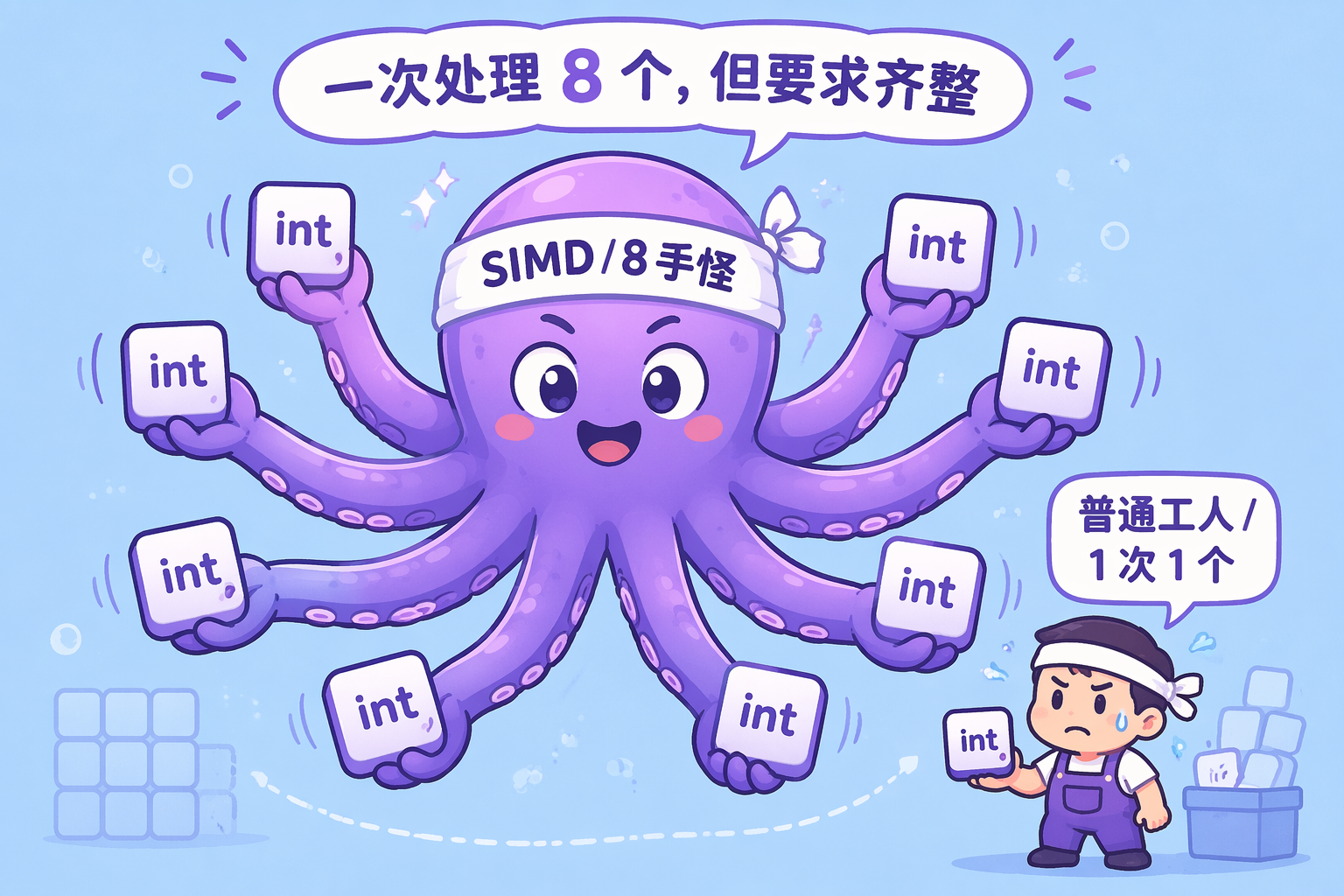
最后再请一位帮手出场,把分块的故事讲完——8 手怪(SIMD)。
8 手怪:“我有 8 只手,可以一次同时处理 8 个数据。但前提是,这 8 个数据要排得齐齐整整,在内存里挨着。”
8 手怪正好需要的是连续的 8 个值,而分块算法在一个小方块里恰好提供了这种"齐整"的数据排列。两者一拍即合。
但 8 手怪有个脾气——它不和跳读的人合作。
8 手怪:“你按列跳着给我数据?那我 8 只手干不起来,我只能 1 只手 1 只手地拿,跟普通工人没区别。”
也就是说,naive 转置不仅 cache 全 miss,SIMD 也用不上。等于把硬件能给你的两个加速器全屏蔽了。
分块算法解锁了 cache,顺带解锁了 SIMD。从 6 倍加速变成 10 倍加速,就是 8 手怪上场带来的额外提速。
数学 vs 硬件的鸿沟
至此,整个故事就完了。把这一桌子角色排个队,我画成了一个图(工人-公交车-跑腿小弟-纸条的全家福)。

回到开头那个面试题——“为什么这么写在大矩阵上会慢得离谱?”
现在你可以这么答:
- 内存是一根纸条,数据按行优先排列;
- CPU 一次搬一整个 cache line(64 字节),指望你接下来要的东西在隔壁;
- 转置算法是按列读,每两次访问跳一整行,每趟公交车 75% 的座位是空跑;
- Prefetcher 跟不上跳读,SIMD 用不上跳读,工人 95% 的时间在等公交;
- 分块算法把大矩阵切成 cache 装得下的小方块,把跳读关在方块内部,cache、Prefetcher、SIMD 全部解锁,10 倍加速。
你回答的其实不是"转置算法"这一道题,而是怎么用硬件的语言去翻译数学的意图。
这事在矩阵转置上是 10 倍差距,在矩阵乘法、卷积、图像处理上是 30 倍甚至 100 倍差距。整个深度学习的底层算子库(BLAS / cuDNN / oneDNN),大半的工程量都在干同一件事——把数学想法翻译成 cache 友好的内存访问模式。
数学家觉得免费的,硬件不这么看。
下次你在 PyTorch 里看到一个 tensor.contiguous() 调用,别随便划过去了。那一行代码,背后是公交车小哥、跑腿小弟、八手怪、搬家公司一整套班子重新上岗。tensor.contiguous() 是在告诉底层:“这个 tensor 本来是某个 view 的跨步 stride,请重新拷贝一份让它在内存上连续,下游算子才跑得动。”
不这么做,一个本来三秒的 forward 可能要跑三十秒。你的 GPU 在哭,你还不知道。
同样的,你在 pandas 里跳着抽行、跳着修改列,也是同一回事。你在 OpenCV 里对 BGR 图像逐像素跳访问 channel,也是同一回事。你在 SQL 里对列存储(Parquet / ClickHouse)跳着 SELECT 不同列,还是同一回事。